
过去两年,具身智能几乎成为科技产业最热门的赛道之一。
无论是人形机器人、智能机械臂,还是各种具身大模型,行业讨论的焦点往往集中在“大脑”层面:模型是否足够聪明、规划能力是否足够强、是否具备推理和决策能力。然而,当机器人真正走出实验室进入家庭、工厂和服务场景后,一个更加现实的问题逐渐暴露出来——机器人或许已经学会思考,却依然没有学会像人一样使用双手。
事实上,人类绝大多数复杂能力最终都要通过双手与物理世界发生交互。拿起一枚硬币、系鞋带、拧开矿泉水瓶、使用螺丝刀完成装配,看似简单的动作背后,是数十块肌肉、数百条神经以及多个关节自由度的实时协同。对于人类而言,这是一种经过数百万年进化形成的本能;而对于机器人而言,这恰恰是具身智能最难突破的能力边界之一。
因此,一个越来越被产业界认可的观点正在形成:未来机器人灵巧操作能力的上限,很大程度上取决于训练阶段能够获得多少真实的人类操作数据。而在这一过程中,“如何准确记录人类双手的运动过程”,正在成为整个具身智能产业链最基础却又最关键的问题之一。
视觉与肌电,两条长期平行发展的技术路线
长期以来,手部动作感知领域主要存在两条技术路线。
第一条路线是计算机视觉。通过RGB相机、深度相机或者多视角视觉系统,利用深度学习模型重建手部三维姿态。这也是当前绝大多数机器人数据采集系统采用的方案。视觉的优势十分明显,它能够直接观察手部的空间位置、姿态变化以及与环境的交互关系,因此天然适合构建机器人模仿学习所需的大规模训练数据。

EgoEMG 数据采集设置:双侧肌电(EMG)腕带、头戴式自我中心视角(egocentric)RGB 相机、外部 ZED 2i RGB-D 相机,以及用于姿态标注的光学动作捕捉系统(配备手部标记点)
然而视觉也存在天然局限。当双手相互遮挡、手部被物体遮挡、光照环境变化或者动作速度过快时,视觉系统的性能往往会明显下降。对于机器人而言,恰恰是这些复杂场景最具有学习价值,而也是视觉最容易失效的场景。
另一条路线则来自神经科技领域——表面肌电(Surface Electromyography,sEMG)。
与视觉不同,肌电记录的是肌肉活动过程中产生的电信号。从生理机制上看,EMG本质上是大脑运动指令传递到肌肉过程中的外在体现。换句话说,视觉看到的是动作结果,而EMG看到的是动作产生的过程。正因为如此,即使手部完全被遮挡,肌电信号依然能够反映手指弯曲、握拳力度以及发力模式等信息。
过去很多年里,这两条路线始终各自发展。视觉研究者不断刷新三维手势重建精度,神经接口研究者则持续探索如何从肌电信号中解码运动意图。但由于缺少统一的数据平台,业界始终无法回答一个关键问题:究竟是视觉更重要,还是肌电更重要?两者是否能够真正互补?
EgoEMG:让两种感知方式第一次站在同一条起跑线上
这一空白直到EgoEMG的出现才被打破。
2026年5月,清华大学自动化系长聘副教授冯建江团队发布了《EgoEMG: A Multimodal Egocentric Dataset with Bilateral EMG and Vision for Hand Pose Estimation》。从数据集名称就可以看出,它将Egocentric(第一视角)与EMG(肌电)两种关键元素融合到了一起。
与以往单一模态的数据集不同,EgoEMG几乎构建了一套完整的人类手部数字化采集系统。研究人员为41名受试者同步采集双侧腕带肌电信号、IMU数据、头戴式第一视角RGB视频、外部RGB-D视频以及光学运动捕捉数据,并最终重建出包含22个自由度的手部关节角标签。整个数据集覆盖60类手势动作,累计采集时长超过10小时。

来自 EgoEMG 的代表性同步样本。每一行(3.9 秒时间窗口)展示了:真值(GT)手部姿态、双侧肌电信号(EMG)、窗口中心处的自我视角 RGB 图像以及外部视角 RGB-D 图像
更重要的是,这些数据全部被严格同步到同一时间轴之上。
这意味着研究人员第一次能够在同一个动作过程中,同时观察到视觉信息、肌电信号以及真实手部运动状态之间的对应关系。对于具身智能而言,这相当于首次获得了一份同时包含“看到什么”“肌肉如何发力”“手最终如何运动”的完整训练样本。
从产业角度看,这种价值甚至超过数据集本身。因为未来机器人真正需要学习的,并不仅仅是动作轨迹,而是动作形成背后的控制机制。
肌电神经接口的真正价值:让机器人理解动作意图
很多人容易把EMG理解成另一种动作捕捉工具。实际上,这种理解低估了肌电神经接口的价值。
在人类运动控制链条中,大脑首先产生运动意图,随后通过脊髓和外周神经将指令传递给肌肉,最终形成实际动作。EMG恰好位于这条链路的中间环节。因此,相比视觉只能观察已经发生的动作,肌电能够捕获动作即将发生时的神经肌肉活动。
这种差异看似细微,却可能决定未来具身智能的发展方向。

用于 EMG 转姿态任务的 EMGFormer 架构。该架构利用 TDS 风格的时序卷积前端对双侧 EMG 信号进行编码,通过采用 RoPE 位置编码的 Transformer 进行解码,并将其映射为包括腕部关节在内的关节角度
如果机器人只学习视觉数据,它学习到的是“人类做了什么”;而如果同时学习肌电数据,它学习到的则可能是“人类为什么这样做”。这也是Meta过去几年持续重金投入腕部神经接口的重要原因之一。对于未来的人机交互系统而言,肌电不仅是一种输入设备,更是一种能够直接读取运动意图的神经接口。而对于机器人而言,它则可能成为理解人类动作生成机制的重要窗口。
EMGFormer背后的技术逻辑:把神经信号翻译成动作语言
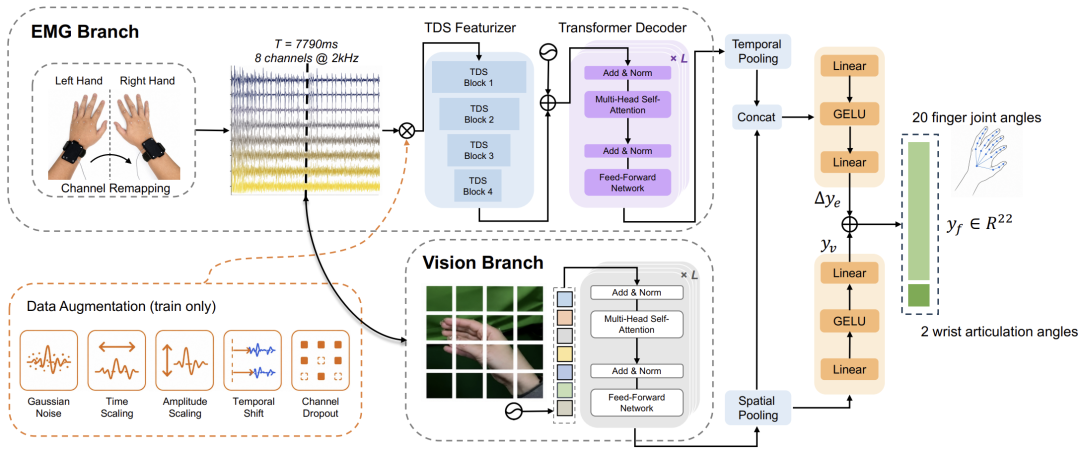
为了验证肌电信号是否真的能够重建复杂手部运动,研究团队提出了EMGFormer模型。其核心思想并不复杂,但却非常具有代表性。
研究人员借鉴语音识别领域成熟的TDS时序卷积架构,首先对2kHz采样率的原始EMG信号进行压缩编码,再利用带有RoPE旋转位置编码的Transformer学习长时间跨度内的肌肉活动规律,最终输出22自由度手部关节角。整个过程本质上是在学习一种“神经信号到动作空间”的映射关系。

“视觉-姿态”基线模型。从中心帧裁剪出的 256×256 尺寸手部图像经由 ResNet 或 ViT 主干网络处理,随后通过 MLP 头部回归出 22 个关节角度
实验结果显示,在EMG2Pose公开基准最困难的跨用户泛化任务上,EMGFormer相比上一代基线模型实现22%的性能提升。
这一结果说明,肌电已经不再只是简单的手势分类工具,而开始具备连续、高自由度运动重建能力。
对于未来机器人学习而言,这意味着神经信号有可能成为一种新的训练数据来源。
一个更值得关注的产业信号:融合正在取代路线之争
如果说数据集和模型属于科研成果,那么EgoEMG真正带来的产业启示则来自于它的实验结论。
肌电与视觉融合基线
过去很多年里,视觉派和肌电派始终存在路线之争。但EgoEMG第一次在统一基准下给出了答案:两者都不是终局,融合才是终局。
实验显示,在纯视觉方案已经取得较高精度的情况下,引入肌电信息后仍然能够获得稳定性能提升。尤其是在自遮挡、运动模糊和深度歧义等复杂场景中,融合模型表现明显优于单一视觉方案。
这背后的逻辑非常符合工程实践。视觉负责观察环境和整体姿态,肌电负责补充视觉无法看到的肌肉发力与精细动作信息。二者并非竞争关系,而是天然互补关系。
从更长周期看,这种多模态融合思路很可能成为未来具身智能的重要方向。未来机器人学习的数据将不再只是视频,而是包含视觉、动作、肌电、力觉甚至脑电在内的多源感知信息。机器人学习的对象也不再只是动作轨迹,而是人类完整的感知—决策—执行过程。
从腕带到机器人:神经科技正在进入具身智能时代
如果把时间线拉长来看,EgoEMG所代表的意义或许远不止一个手部数据集。
过去十年,肌电神经接口主要服务于假肢控制、人机交互和可穿戴设备;而未来十年,它可能成为具身智能的重要基础设施。
因为机器人最终需要学习的,不仅是人类双手如何运动,更是神经系统如何驱动这些运动。
当第一视角视觉、肌电信号、运动捕捉和机器人学习开始融合,一个新的研究方向正在形成——神经具身智能(Neuro-Embodied Intelligence)。
从这个角度看,清华大学团队和手亿团队联合发布的EgoEMG的价值不仅在于让机器人“看见手”,而在于让机器人开始理解人类动作背后的神经逻辑。这或许正是下一代灵巧操作系统真正需要补上的那块拼图。
脑机接口/神经接口 X 具身智能交流群:
群规:
1、加群后请在两日内备注:行业-昵称,若未备注,群主会不定期移除;
2、禁止外部宣传推广营销,一经发现移除群;

来源:https://arxiv.org/pdf/2605.05712

脑机接口社区是国内首家脑机接口(BCI)产业服务平台、国内脑机接口新媒体开创者与引领者。主要为企业、科研团队、投资机构和从业者提供以下服务:
宣传报道:图文、短视频、直播形式报道企业动态、技术解读、产品介绍等内容,提升曝光和行业影响力。
资源对接:根据需求匹配资本、供应链、临床机构、渠道方等资源,完成真实对接,促进合作。
成果转化:协助技术团队寻找产业方、投资人及落地场景,推动技术到产品的转化。
活动策划执行:承接线上线下路演、沙龙、论坛等活动的策划与执行。
其他定制需求:包括报告定制、市场调研、人才招聘支持等个性化服务。
合作洽谈,请联系微信:ZuoLeiLeiya
(备注:姓名-单位-合作)
投稿丨成为创作者,请联系微信:RoseBCI

🌟星标置顶🌟
不错过每一条脑机前沿进展

一键三连「分享」、「点赞」和「在看」
欢迎在评论区聊聊










