哈喽,大家好~
今天的主题是:随机森林和XGBoost的核心对比。
对于在特定情况下,如何选择这两个模型?我们来聊聊看~
随机森林 和 XGBoost 是两种常用的集成学习算法,都属于决策树集成模型,但它们在构建模型的方式、优化目标、偏差与方差的平衡、模型复杂度、以及计算效率上有显著不同。
对于核心的一些区别,咱们先列一个表格来说明:
核心原理
1. 随机森林(Random Forest)
基于 Bagging(Bootstrap Aggregating)策略,即对数据进行多次有放回采样。
每一棵树是独立的,训练时随机选择样本和特征。
算法流程:
从训练集中有放回地随机采样形成多个训练子集; 每个子集训练一棵CART树,分裂时只从随机选取的特征子集中选择最佳特征; 所有树的预测结果进行多数投票(分类)或平均(回归)。
数学公式:
设训练集为,
每棵树在从原始训练集抽样的子集上独立训练,记为;
最终预测为:
分类问题(投票):
回归问题(平均):
特点:
强调“去相关性”以减少方差; 容易并行化; 无显式损失函数,未进行模型的全局最优训练。
2. XGBoost(eXtreme Gradient Boosting)
Boosting思想:新模型不断叠加,每一步拟合上一步的残差,使用二阶泰勒展开的梯度下降策略优化目标函数。
引入正则项控制模型复杂度,防止过拟合。
算法流程:
初始化预测值;
对于每一轮:
计算一阶梯度;
计算二阶梯度;
构造目标函数的二阶近似,并选择分裂特征和叶子值;
更新预测值:
最终输出预测为所有弱模型的加权和。
目标函数:
正则项:
其中是叶子节点个数,是第个叶子的权重。
特点:
使用梯度下降优化显式目标函数; 有正则化,控制复杂度; 分裂点精确、支持欠采样、支持缺失值处理; 模型精度高,但训练时间较长。
性能和适用性对比
如何选择?
案例说明
我们训练了两个模型(随机森林和XGBoost),并基于一个虚拟的二分类数据集(1000个样本,20个特征)生成了多个图像,以深入比较两者的优劣。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.datasets import make_classification
from sklearn.ensemble import RandomForestClassifier
from xgboost import XGBClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, confusion_matrix, roc_auc_score, roc_curve
plt.rcParams["figure.figsize"] = (10, 6)
# 生成一个虚拟二分类数据集
X, y = make_classification(n_samples=800, n_features=20, n_informative=12,
n_redundant=5, n_classes=2, random_state=42)
# 拆分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 训练随机森林模型
rf = RandomForestClassifier(n_estimators=100, random_state=42)
rf.fit(X_train, y_train)
y_pred_rf = rf.predict(X_test)
y_proba_rf = rf.predict_proba(X_test)[:, 1]
# 训练XGBoost模型
xgb = XGBClassifier(use_label_encoder=False, eval_metric='logloss', random_state=42)
xgb.fit(X_train, y_train)
y_pred_xgb = xgb.predict(X_test)
y_proba_xgb = xgb.predict_proba(X_test)[:, 1]
# 评估指标
accuracy_rf = accuracy_score(y_test, y_pred_rf)
accuracy_xgb = accuracy_score(y_test, y_pred_xgb)
auc_rf = roc_auc_score(y_test, y_proba_rf)
auc_xgb = roc_auc_score(y_test, y_proba_xgb)
# 图1:准确率对比条形图
fig1, ax1 = plt.subplots()
colors = ['#FF6347', '#3CB371']
ax1.bar(['Random Forest', 'XGBoost'], [accuracy_rf, accuracy_xgb], color=colors)
ax1.set_title('模型准确率对比')
ax1.set_ylabel('Accuracy')
# 图2:ROC曲线
fpr_rf, tpr_rf, _ = roc_curve(y_test, y_proba_rf)
fpr_xgb, tpr_xgb, _ = roc_curve(y_test, y_proba_xgb)
fig2, ax2 = plt.subplots()
ax2.plot(fpr_rf, tpr_rf, label=f'Random Forest (AUC = {auc_rf:.5f})', color='#FF6347')
ax2.plot(fpr_xgb, tpr_xgb, label=f'XGBoost (AUC = {auc_xgb:.5f})', color='#3CB371')
ax2.plot([0, 1], [0, 1], 'k--')
ax2.set_title('ROC 曲线比较')
ax2.set_xlabel('False Positive Rate')
ax2.set_ylabel('True Positive Rate')
ax2.legend()
# 图3:混淆矩阵热力图
cm_rf = confusion_matrix(y_test, y_pred_rf)
cm_xgb = confusion_matrix(y_test, y_pred_xgb)
fig3, (ax3a, ax3b) = plt.subplots(1, 2, figsize=(14, 6))
sns.heatmap(cm_rf, annot=True, fmt='d', cmap='Reds', ax=ax3a)
ax3a.set_title('Random Forest 混淆矩阵')
ax3a.set_xlabel('Predicted')
ax3a.set_ylabel('Actual')
sns.heatmap(cm_xgb, annot=True, fmt='d', cmap='Greens', ax=ax3b)
ax3b.set_title('XGBoost 混淆矩阵')
ax3b.set_xlabel('Predicted')
ax3b.set_ylabel('Actual')
# 图4:特征重要性
feature_names = [f"Feature {i}"for i in range(X.shape[1])]
importances_rf = rf.feature_importances_
importances_xgb = xgb.feature_importances_
df_importances = pd.DataFrame({
'Feature': feature_names,
'Random Forest': importances_rf,
'XGBoost': importances_xgb
}).set_index('Feature')
fig4, ax4 = plt.subplots()
df_importances.sort_values('XGBoost', ascending=False).head(10).plot(kind='bar', ax=ax4, color=['#FF6347', '#3CB371'])
ax4.set_title("Top 10 特征重要性对比")
ax4.set_ylabel("Importance")
plt.tight_layout()
plt.show()
模型准确率对比图

展示两个模型在测试集上的准确率。XGBoost 的准确率略高于随机森林,说明在这个数据集上它对边界分类的学习更强。
ROC 曲线对比图
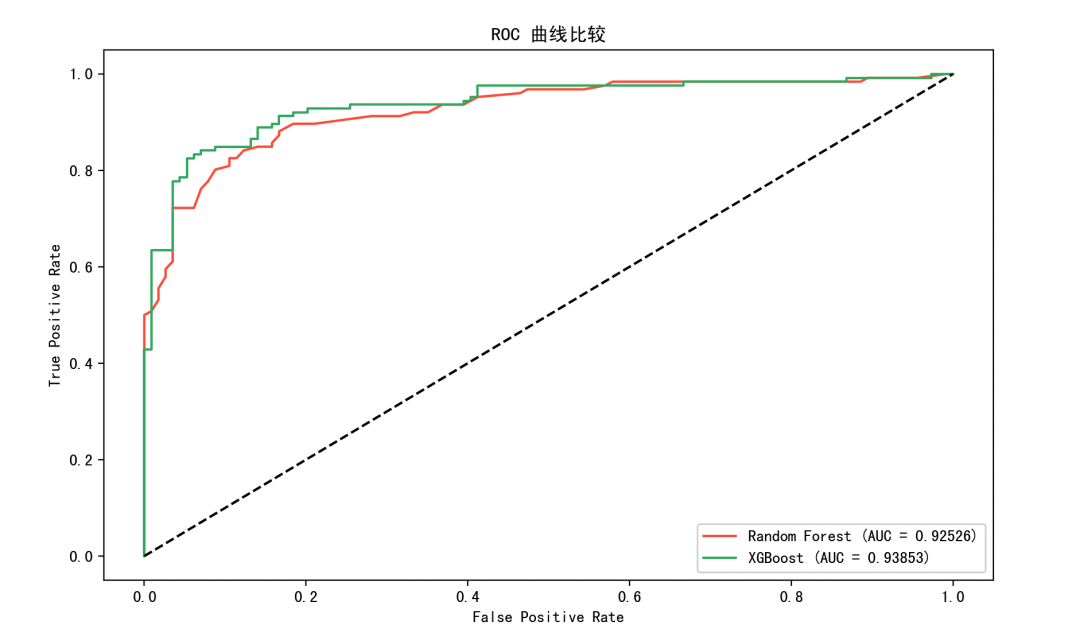
展示了在所有分类阈值下,两个模型的真正率与假正率之间的权衡。AUC 值(曲线下的面积)是评估模型整体性能的重要指标:
Random Forest AUC:0.92526 XGBoost AUC:0.93853
XGBoost 的 ROC 曲线在大多数区域都包围了 RF 的曲线,表明它在召回与精准度之间找到了更好的平衡。
混淆矩阵热力图

用于分析分类错误的模式。XGBoost 相比 Random Forest,误分类数量更少,特别是在 False Negatives 上(更少漏报)。
特征重要性对比图

展示两个模型对前10个重要特征的关注度差异。XGBoost 在信息丰富的特征上权重集中、响应强烈,而 Random Forest 更平均分配注意力,这可能造成泛化能力下降。
如果你面对以下场景,可以选择:
其实大家可以先从随机森林入手,因其训练快、无需复杂调参,是很好的baseline。
然后,如果对预测性能有更高追求,且资源允许,尝试 XGBoost。
最后
最近准备了16大块的内容,124个算法问题的总结,完整的机器学习小册,免费领取~