
导读
近年来,大规模人工智能(AI)的快速发展,正在以前所未有的速度重塑数字基础设施。以 GPT、Gemini 等大模型为代表的新一代 AI 系统,早已不再依赖单台机器或单个数据中心运行,而是需要成千上万块 GPU 和专用加速器跨机架、跨机房,甚至跨数据中心协同工作。支撑这一切的,不只是算力芯片本身,更是数据在各计算单元之间的高速流动能力。换句话说,未来 AI 基础设施的竞争,早已从“算力竞争”升级为“算力 + 互联”的双重竞争。
在这样的背景下,数据链路必须同时满足高带宽、低延迟、低功耗三重要求。光纤通信作为现代数据通信的骨干,支撑着数据中心内的数据互联。然而,随着传输速率不断攀升,光信号在链路中会受到色散、收发器带宽受限以及非线性效应等多重损伤,导致信号失真。传统方案依赖光电转换后再通过数字信号处理器(Digital signal processor, DSP)进行补偿,虽然技术成熟,但对短距离、高容量的数据中心互联也带来了高延迟和巨额电能消耗。这种“电域后补偿”模式正逐渐逼近瓶颈,导致大规模数据中心中的GPU闲置空转、效率急转直下。
为应对这一挑战,香港中文大学黄超然教授团队与合作者研发出一种集成全光信号处理器(Optical signal processor, OSP),可直接在光域完成信号均衡。与传统依赖电子后处理的方案不同,OSP可以在光信号尚未转化为电信号之前,就对失真进行实时修复,实现真正意义上的全光实时处理。相关成果以“An all-optical signal processor enabling terabit-per-second real-time equalization”为题发表在Science。香港中文大学黄超然教授为文章的通讯作者,香港中文大学博士研究生王本善和肖洽荣为文章的共同第一作者。其他共同作者包括来自香港中文大学的博士研究生徐滕基、范理、刘少杰和孔秋强教授,华中科技大学董建绩教授和复旦大学张俊文教授。
这项成果最令人瞩目的地方在于:OSP可作为一种通用非线性均衡器, 不仅能补偿色散,扩展可用的波分复用 (Wavelength-division multiplexing, WDM)窗口到6.8倍以上, 还能同时缓解带宽受限和非线性失真;不仅能支持1.6 Tbit/s的实时补偿,还实现了低于 60 ps 的延迟和每比特数十飞焦耳级的能耗。更重要的是,它将传统依赖电域 DSP 的补偿任务前移到光域,从而为下一代人工智能数据中心互联提供了一条更高速、更低延迟、更高能效的全光革命路径。
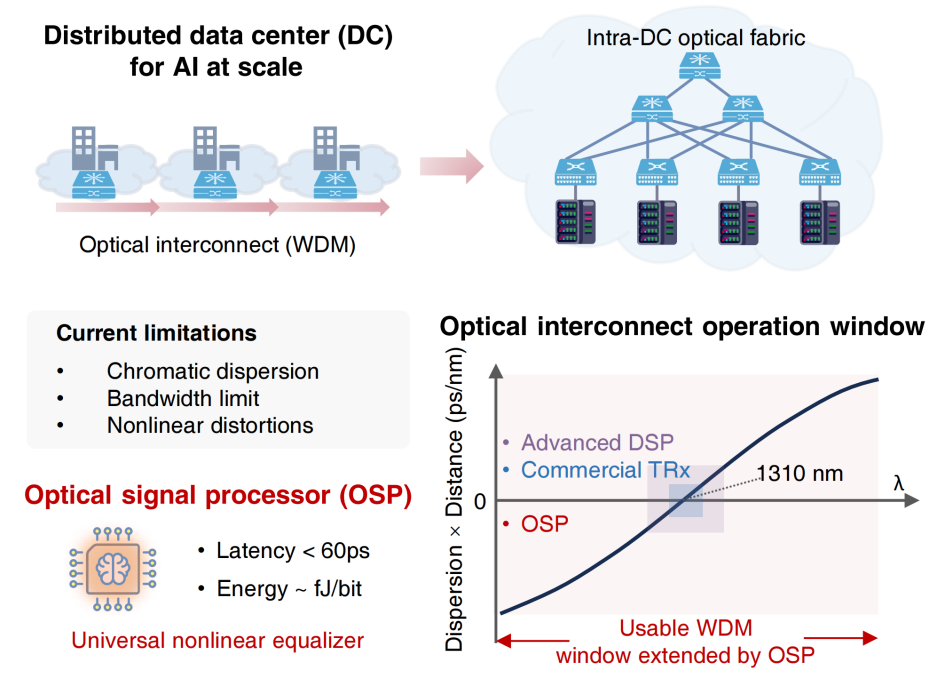
图1:分布式数据中心 (DC) 依靠光互联支撑着大规模人工智能的发展
一、全光高速信号处理器
OSP的核心,是一种深度光学储备池架构。它将多个带反馈回路的光学储备池节点级联起来,增强系统对高速光信号时序特征的记忆与处理能力,并结合全光读出层实现信号均衡。如图2所示,失真的光信号依次经过三个集成储备池层和一个具有 8 个分支的读出层处理。研究团队通过有意调谐储备池层与读出层中的光延迟线长度,构造出类似“游标效应”(Vernier-like effect)的机制,从而让模拟光子芯片实现低至 1 ps 的超高有效采样分辨率。换句话说,虽然芯片物理规模很小,但借助递归反馈和时间记忆机制,它获得了极强的信号处理能力,在功能上就等效实现了一个拥有 7 个反馈通道和 64 个前馈通道的复杂 IIR(无限脉冲响应)滤波器。
更巧妙的是,系统中的光电探测器采用平方律探测,与光子储备池结合后,在数学上可构成一个二阶 Volterra 非线性均衡器,真正实现了“全光计算 + 非线性处理”的统一。这种架构不仅提升了处理能力,也显著压缩了芯片尺寸和系统复杂度。
OSP基于商用 SOI 平台制造,片上 MZI 和移相器组合提供可编程复数权重,微加热器驱动的原位训练则用于实时优化参数。结合片上解波长复用器,一个 OSP 就能支持多个波长通道的并行处理,而不需要像传统 DSP 那样为每个通道单独配置独立DSP模块。对未来 WDM 数据中心互联而言,这种并行处理能力具有非常强的现实意义。
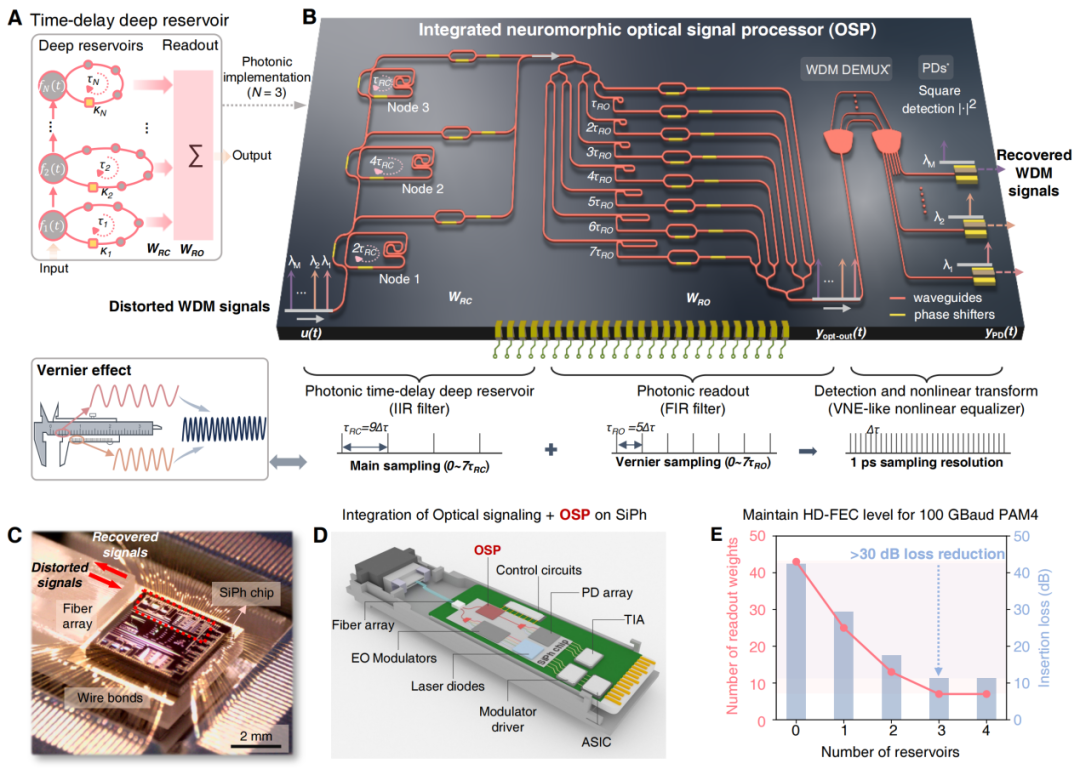
图2:OSP 架构和部署
二、OSP全光色散补偿
在超高速光传输系统中,色散(Chromatic Dispersion, CD)是限制传输距离和容量的关键瓶颈,尤其是在强度调制直接检测(IM/DD)链路中。色散会引发频率选择性功率衰落,严重损害信号完整性。传统 DSP 虽然可以尝试补偿,但由于光电探测后相位信息已经丢失,补偿能力会受到明显限制,同时还可能带来高频噪声放大问题。这使得 IM/DD 系统受限于经典的物理极限——带宽-色散乘积 B2DL 边界(例如,对于 C 波段的 100 GBaud 信号,DSP无损补偿的累积色散 DL 仅为约 25 ps/nm)。OSP的策略则是在光电探测器之前直接补偿色散。也就是说,它在损伤被转换成难以修复的电信号之前,就已经完成了信号修复,因此能够有效避免传统 DSP 的噪声惩罚。
如图3所示,实验中,研究团队在 5 km 单模光纤上测试了累积色散高达 85 ps/nm 的链路,结果表明,即便在没有任何接收端 DSP 辅助的情况下,OSP 依然成功实现了 100 GBaud PAM4 信号传输,并获得清晰完整的眼图。仿真进一步显示,OSP 甚至可支持 170 ps/nm 色散下的 100 GBaud 传输,以及高达 200 GBaud 的超高速信号。这一结果将可用的 WDM 窗口拓宽了 6.8 倍以上,为下一代大容量数据中心互联打开了新的空间
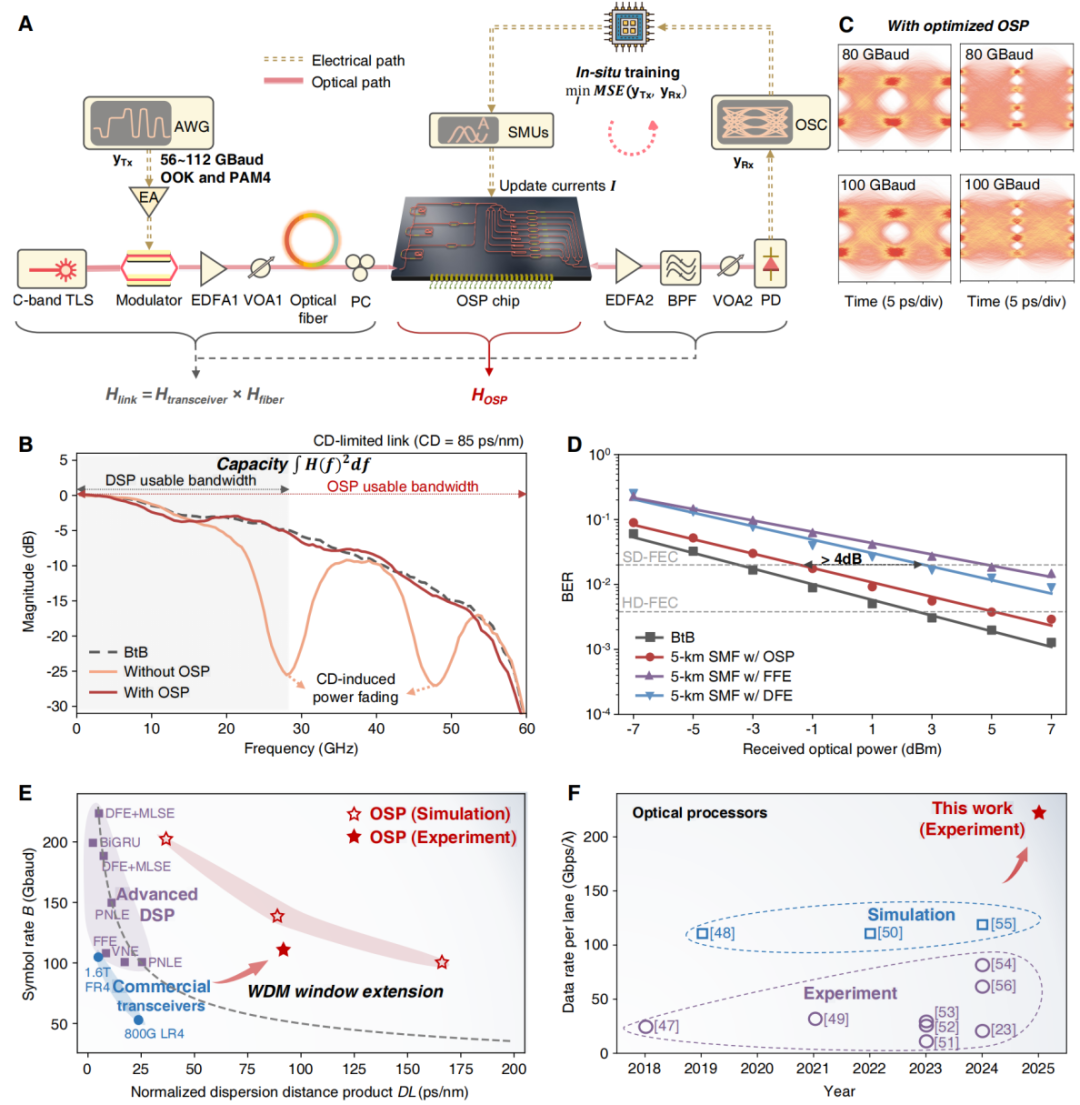
图3: OSP色散链路补偿效果
三、OSP全光带宽补偿
除了在强色散链路中表现优异,OSP还可扮演通用非线性均衡器的角色。在实际光纤通信系统中,收发机的有限带宽会导致高频分量衰减,进而引入码间串扰(ISI)。当带宽受限与中度色散叠加时,问题会更加复杂。如图4所示,研究团队使用 40 GHz 带宽调制器,对两类典型场景进行了严苛测试:(1)纯收发机带宽受限;(2)收发机带宽受限 + 中度色散共同作用。
在场景一中,OSP通过在线训练成功补偿了器件导致的高频谱衰减,将系统 3 dB 带宽从约 10 GHz 提升到 50 GHz以上,显著抑制了 ISI, 眼图清晰完好。在场景二中,中度色散与带宽限制共同造成奈奎斯特频率处的频谱塌陷,而 OSP 则将严重失真的接收谱修复为近乎平坦的理想状态。
更关键的是,OSP单独补偿的效果已经优于传统前馈均衡(FFE),并接近高复杂度 反馈判决均衡(DFE);当再叠加仅 1-tap 最大似然序列估计(MLSE) 时,其性能甚至超过“DFE + MLSE”组合。也就是说,OSP不是简单替代某个 DSP 模块,而是把补偿逻辑直接前移到光域,从而实现了更低复杂度、更低功耗的全光均衡,也为未来高速、低功耗、低复杂度的光互连系统提供了一种更具前景的全光均衡路径。

图4:OSP带宽受限与非线性链路补偿效果
四、OSP全光非线性补偿
高速光链路中,非线性失真同样是不可忽视的难题,尤其是在较高发射功率下,光纤中的 Kerr 效应会引入相位扰动,并在 IM/DD 系统中进一步转化为带记忆的强度失真,形成传统 DSP 难以彻底消除的非线性码间串扰。实验以 5 km 单模光纤 和 100 Gbaud PAM4 信号为例,在高功率发射条件下对比了 FFE、DFE、DFE+MLSE 以及前馈神经网络等多种 DSP 方案。结果显示,OSP在非线性主导场景中取得了最佳性能。更重要的是,OSP是在光域中提前削弱主要非线性串扰,因此能显著降低后端 DSP 复杂度和功耗。这意味着,OSP不仅是一种补偿器,更是一种面向未来高速链路的光电协同破局方案。
五、OSP可编程性
OSP的另一大优势是高度可编程。不同于许多一经制造便固定功能的光子处理器或色散补偿器,,该OSP可通过调节片上相移器重新配置光场处理过程,从而适应不同的调制格式、数据速率和工作波长。实验中,研究团队在 5 km 单模光纤链路 上测试了 OOK 和 PAM4 信号,符号率覆盖 56 至 112 GBaud,工作波长从 1540 nm 连续调谐到 1565 nm。借助基于粒子群优化的原位训练方法,OSP能够针对不同波长和链路状态自动优化相移器参数,使误码率始终保持在 HD-FEC 门限以下。更进一步,OSP还支持连续可调的数据速率,其工作范围并不局限于固定采样周期,而是可在较宽速率区间内保持有效均衡能力。这意味着,OSP不是一个单一功能器件,而更像一块可重构的“全光 DSP 芯片”,能够根据实际链路环境灵活切换工作状态,为未来多波长、多速率、多调制格式的高速光互联提供统一而灵活的光域处理平台。
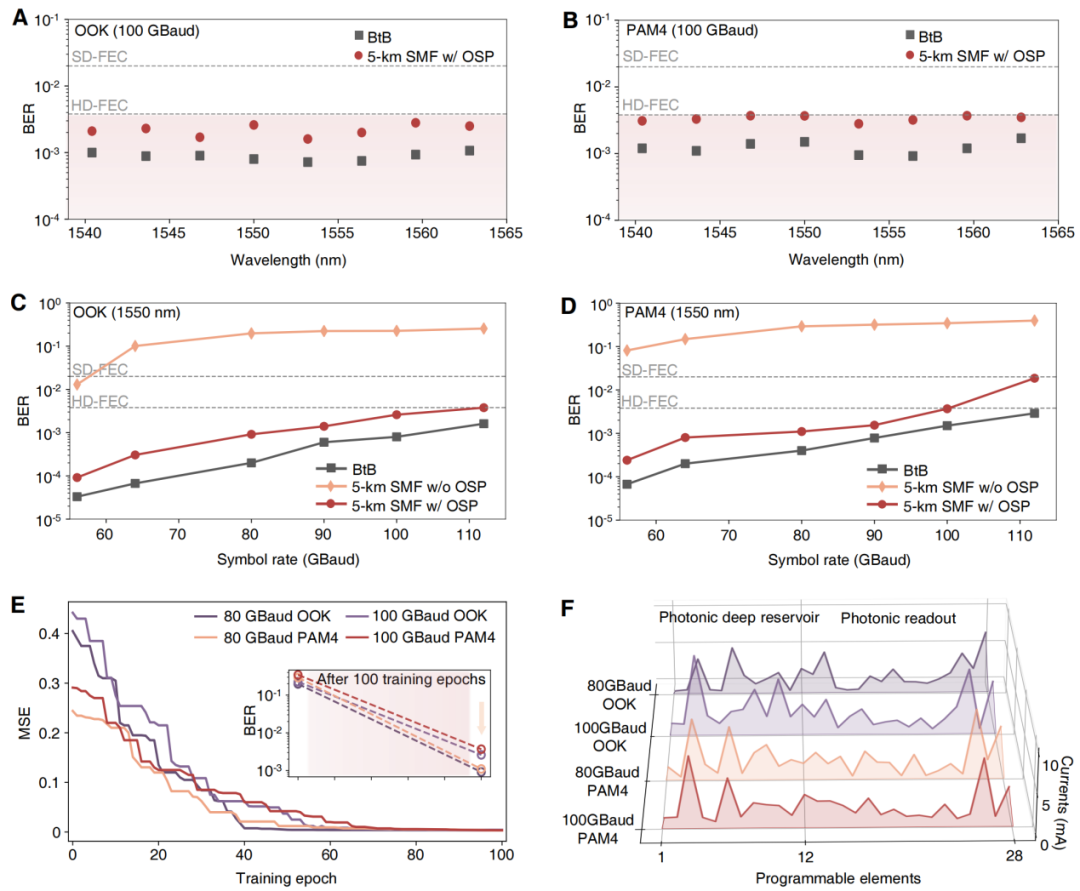
图5:OSP 可编程性验证
六、OSP赋能1.6T数据中心互联
随着数据中心流量的爆炸式增长,基于波分复用(WDM)的数据中心互联(DCI)系统成为支撑超高吞吐量的核心基础设施。然而,随着波长通道数的增加,DSP模块的数量、功耗、占板面积以及热管理挑战都会同步上升,代价极高。
OSP的与众不同之处在于,它天然利用了光波的并行性与宽带特性——处理多个波长通道无需额外的能耗或芯片面积开销。实验中,研究人员构建了一个1.6Tbit/s的WDM数据中心互联系统,在C波段1540至1565nm范围内采用8个波长通道,每个通道承载200Gbit/s PAM4信号,并通过5km单模光纤传输。结果显示,OSP能够同步作用于所有波长通道,即便不同波长存在各自的色散差异,进一步结合轻量级DSP后处理后,系统所有WDM通道均可低于HD-FEC门限,而所需FFE或DFE抽头数相比纯DSP方案大幅减少,计算复杂度显著下降。这意味着,在未来数据中心中,OSP有望将主要补偿任务前移到光域完成,让电域DSP只承担少量残余修正,从而实现更高吞吐、更低功耗、更低延迟的1.6Tbit/s级光互连。
 图6:OSP赋能1.6T数据中心互连
图6:OSP赋能1.6T数据中心互连
七、结论与展望
这项研究中的OSP并不是简单替代某一种传统数字均衡算法,而是把高速光互连中的关键补偿任务前移到了光域完成。相比依赖FFE、DFE、MLSE或神经网络等电域DSP方案,OSP能够在光电探测之前直接处理完整光场,对色散、带宽受限以及非线性损伤进行实时补偿,从源头上降低码间串扰和高频衰落带来的影响。实验结果表明,OSP不仅在补偿性能上优于复杂DSP方案,还展现出极低的处理延迟和能耗:系统实测延迟约为55ps,在1.6Tbit/s传输场景下,能效约67.5fJ/bit。AI训练集群的带宽饥渴不会停歇,数据中心的光互连速率翻倍仍在加速。当电域DSP的算力账单越来越"昂贵",OSP所代表的"光层先行、电域轻载"范式,有望深刻重塑未来高速光互联的技术版图。
论文信息
B. Wang, et al., An all-optical signal pocessor enabling terabit-per-second real-time equalization. Science 392, eady5344 (2026). DOI: 10.1126/science.ady5344.
https://www.science.org/doi/10.1126/science.ady5344
点这里👆加关注,锁定更多原创内容
*免责声明:文章内容系作者个人观点,半导体芯闻转载仅为了传达一种不同的观点,不代表半导体芯闻对该观点赞同或支持,如果有任何异议,欢迎联系我们。
推荐阅读

喜欢我们的内容就点“在看”分享给小伙伴哦~![]()











