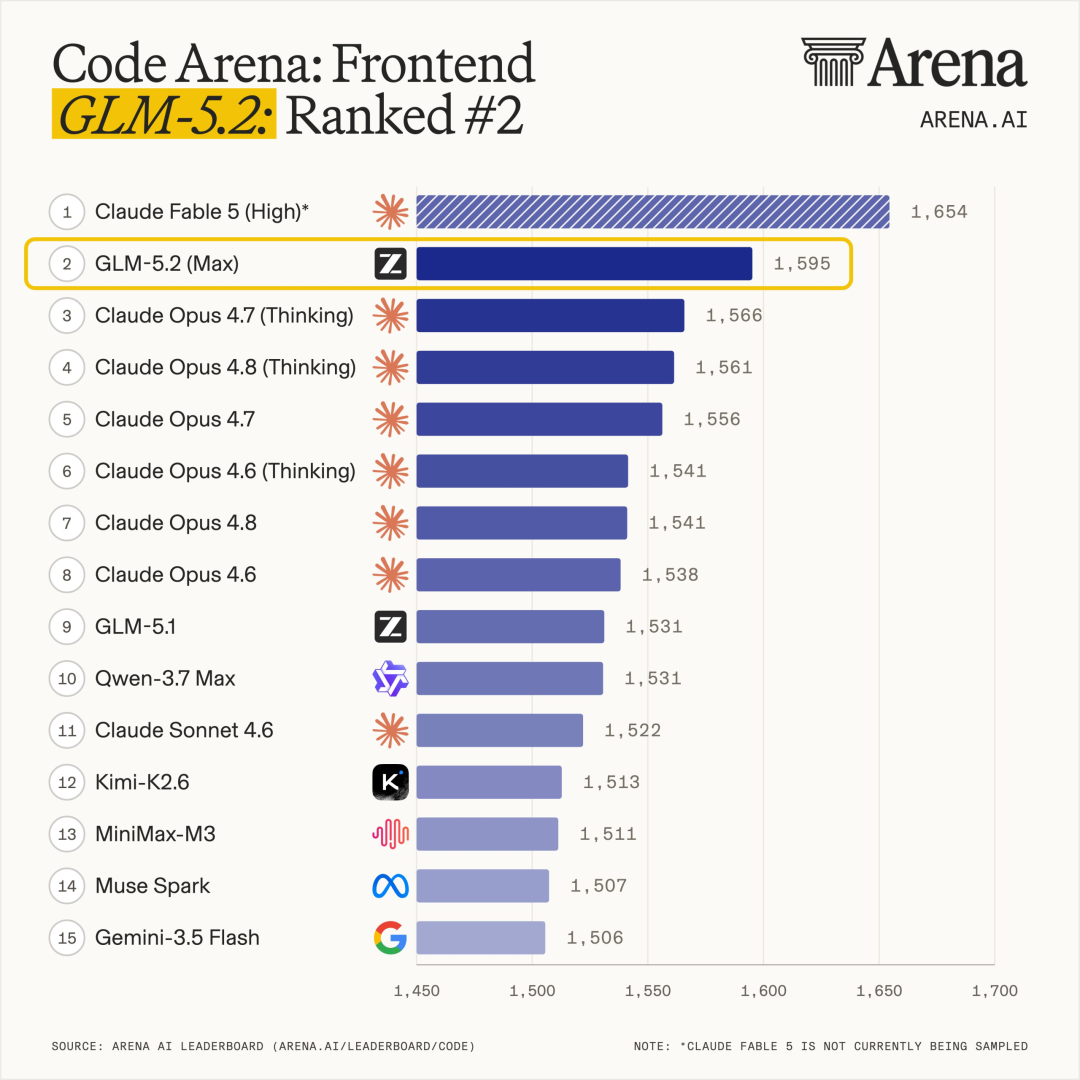
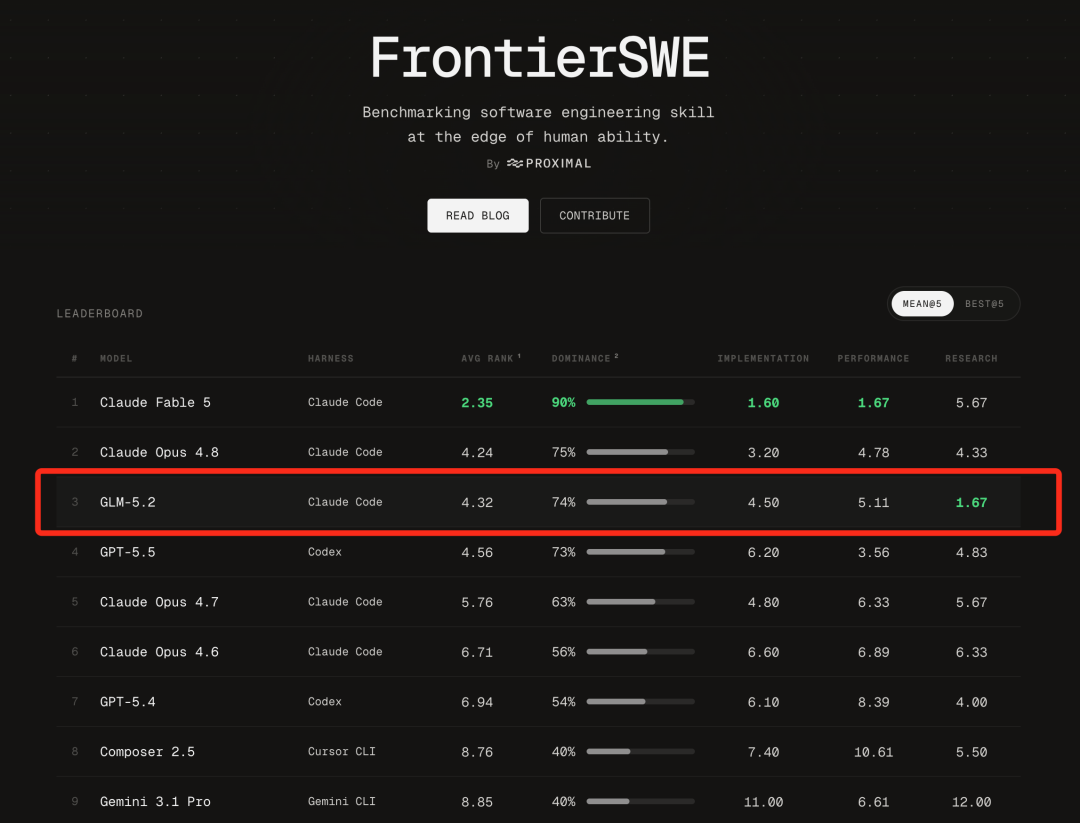
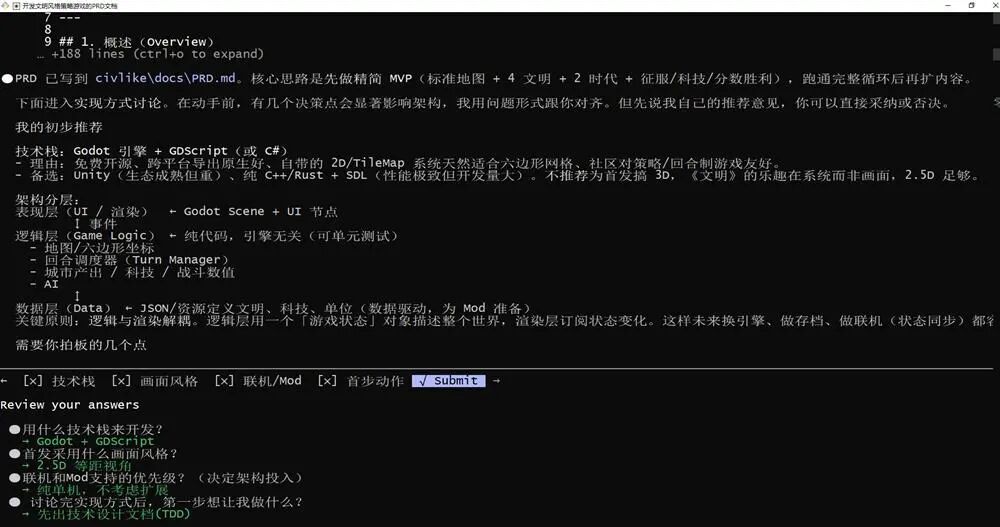
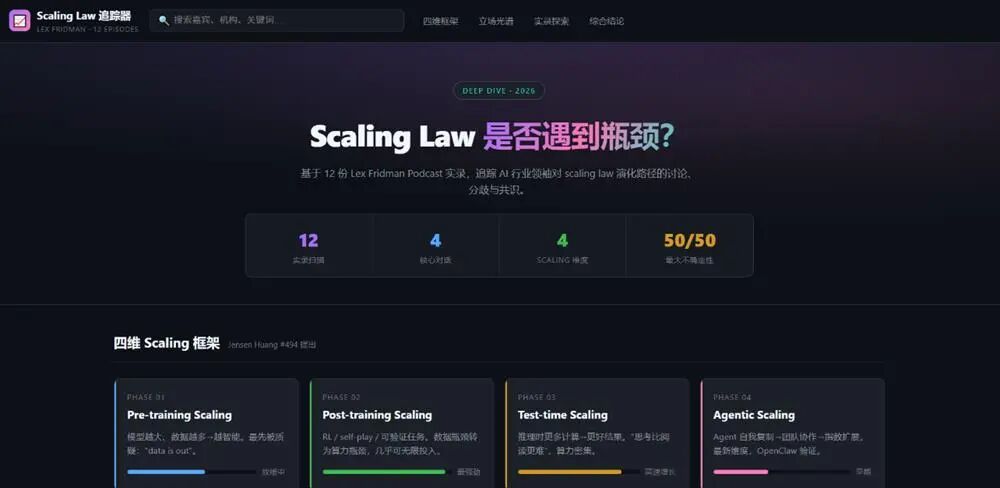
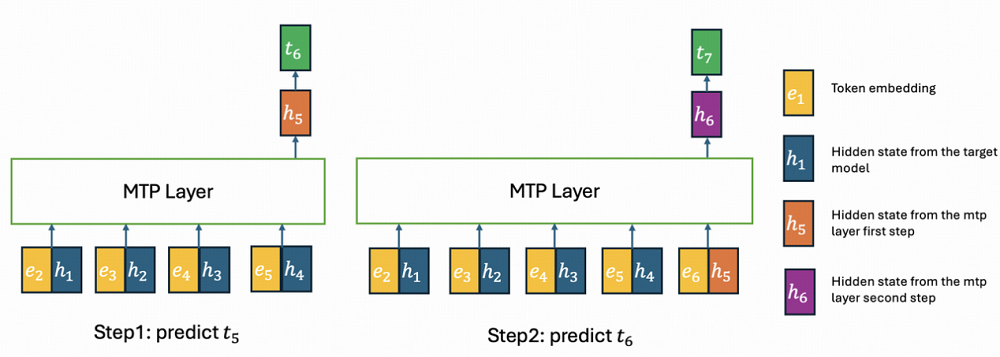
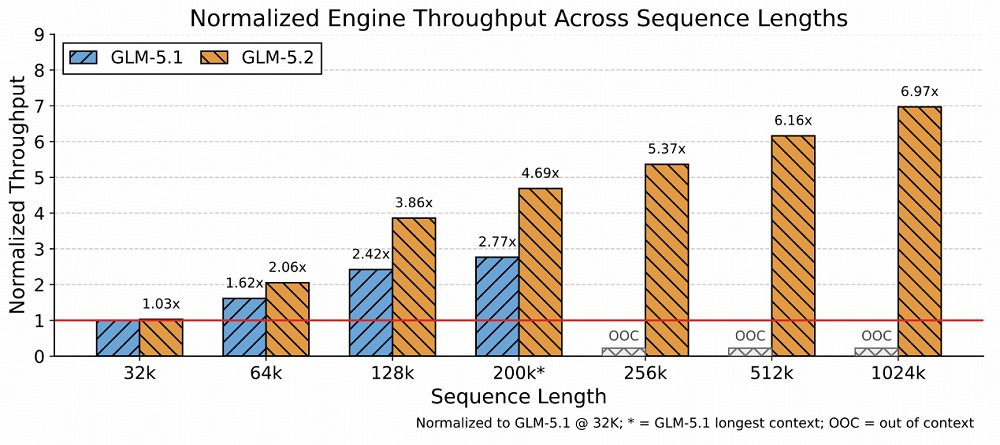
智谱补齐长程任务技术拼图。作者 | 陈骏达编辑 | 漠影智东西6月17日报道,今天,智谱正式发布并开源了新一代旗舰模型GLM-5.2。在大模型盲测平台竞技场(Arena.ai)的编程评估系统Code Arena上,GLM-5.2拿下了1595分的高分,排名总榜第二,仅次于Fable 5,并在全球可用模型中排名第一。在测评“超长程、开放式、高难度软件工程任务”的基准测试FrontierSWE中,目前GLM-5.2排名仅次于Opus 4.8以及暂时不可用的Fable 5。在专门评测模型品味(taste)的Design Arena上,GLM-5.2取得全球第一的表现,审美也冲到全球前沿。知乎上,大V toyama nao打趣道,以后通过中转站用Opus的用户得面对一个新问题:如果Opus是GLM-5.2冒充的,那用户可能真的分辨不出来。体验到GLM-5.2实际效果的国内外用户反响热烈。有开发者直言:“这是国内第一款在我工作流上达到Opus级的模型。”海外用户也反馈,GLM-5.2的表现超出预期,与Fable 5的差距比预期中要小得多。如今,Fable 5已无法正常使用,海外网友原本以为它的封禁会拉开差距,没想到GLM已经快追上来了。这下轮到Anthropic头疼了。目前,GLM-5.2 API已经上线,企业和用户也可在Hugging Face等开源平台直接下载并部署这一模型。此前,智东西已经连续对智谱的GLM-4.5、GLM-4.7、GLM-5、GLM-5.1等模型进行了深度体验,此次GLM-5.2发布后,我们第一时间跑了几组大型案例,能明显感觉到一条清晰的进化脉络:如果说GLM-4.7实现了对彼时顶级编程模型Sonnet 4.6的对齐,在GLM-5.2上,这一模型的“使用体感”,已经和Opus级模型基本没有差别。在AI编程模型领域,此前公认的全球头部玩家长期只有Anthropic(Claude系列)和OpenAI(GPT系列)。此次,GLM-5.2通过全球可用编程模型第一的榜单成绩和开发者“Opus平替”真实口碑,正在跻身这一顶级俱乐部。可以说,一个由Anthropic、OpenAI、智谱构成的“Coding御三家”格局正在成形。在闭源巨头垄断编程模型话语权,并且随时可能收回访问权限的当下,GLM-5.2用开源将选择权交还给了广大开发者。01.和GLM-5.2协作编程4小时:几乎用满百万上下文、修16个bug从零打造一个《文明》复刻版我的首个实测任务,是让GLM-5.2从零开始开发一款《文明》风格的策略游戏,逐步从M0版本迭代到M4版本。在正式开发前,我先让GLM-5.2写了一份PRD文档,并与它讨论了具体的技术实现,最后的技术方案确定为使用Godot引擎、GDScript,实现2.5D画风的游戏。M0版本是整个项目的地基。在这一版本中,GLM-5.2一连创建并编写了十几个文件,生成了标准的地图网格、基础游戏单位等核心内容。开发完成后,GLM-5.2 快速跑了一次验证,交付了M0版本。不过,这个版本只是个初步成果,游戏设计还较为粗糙,角色仅用圆形图标替代,也没有清晰的游戏机制,还自带不少交互层面的小bug。我决定在M0阶段逐一优化这些bug。GLM-5.2在我的指令下调整了信息面板无法打开、初始单位无法移动等多个bug,不过,每个bug的修复基本都可以在一两轮对话中完成,效率还是不错的。之后,我跳过了M1版本,直接让GLM-5.2开发出M2版本,这也是游戏深度的核心。在没有明确要求的情况下,GLM-5.2自主判断并决定加入了战斗系统、科技树、城市经济和资源限制四大子系统。这些新系统的开发工作量较大,GLM-5.2持续工作了30多分钟才完成。在这一过程中,GLM-5.2严格按照我和它定下的开发规则:完成一个功能,跑一次测试,没问题了再进行下一次开发。其实,这轮迭代跑到后期,上下文窗口已经到30多万tokens了,GLM-5.2此时还能记得规矩,实属不易。M3版本让游戏从沙盒变成了能分出输赢的完整单局。GLM-5.2实现了敌方战术AI,并扩大了地图的尺寸。虽然我的开发指令主要以游戏本身功能迭代为主,但GLM-5.2还主动考虑到了游戏优化的问题。随着地图越来越大,GLM-5.2决定将地形渲染拆分为静态和动态层,小地图也加上了缓存优化,这让游戏跑起来更加顺畅。后期M4版本的工作主要集中在美感和可玩性方面,在这一阶段,GLM-5.2展现出了不错的审美。比如,我告诉它游戏的UI设计“没有游戏味儿”,全是文字堆砌,它便自己找素材更新图标,重新设计交互卡片,让整个游戏的视觉效果上了一个档次。最后,我还遇到了一个意想不到的bug,当地图扩张到100x100的尺寸时,出现了画面随着拖拽剧烈跳动的问题,试了各种方法也无法解决。最后,还是GLM-5.2成功定位了问题:它发现,这一个问题其实从M0版本开始就贯穿始终,但在地图放大后才变得明显,这与UI控件的问题有关。这种问题根因的定位,意味着GLM-5.2可以跨越大几十万的上下文长度,精准定位了初版代码中的隐藏bug。 在完成上述所有开发任务后,我们也简单统计了下,在这一项目中,GLM-5.2总计使用了87万的上下文窗口,已经接近它的极限。GLM-5.2复盘了它在接近百万上下文长度的任务中修复的所有bug。它的统计结果是16个,与实际数据保持一致。同时,GLM-5.2还记得每个bug发生的原因以及解法,真正展现出在百万上下文场景内的可靠记忆。02.30小时播客实录一口气读完,GLM-5.1败下阵来除了编程之外,GLM-5.2 100万上下文的能力还可以解锁很多其他用途。在日常工作中,我常常需要处理大量长文本的信息整合,更大上下文窗口的模型可以起到很好的提效作用。实测中,我一次性上传了13份AI领域相关的播客实录,总时长超过30小时,文本量约25万词,换算下来至少有30万个token。这些播客来自The Lex Fridman Podcast,涉及不同嘉宾,时间跨度数周,话题涵盖大模型架构、企业AI战略、多模态、AI安全、开源生态等多个子领域,信息高度分散且存在大量跨期观点的呼应、补充与矛盾。让GLM-5.2一次性读入全部13份实录后,我下达了以下解读任务:(1)跨期观点追踪:我让GLM-5.2定位“scaling law是否遇到瓶颈”这一话题在所有13份实录中的讨论轨迹。GLM-5.2成功识别出了黄仁勋旗帜鲜明否定“预训练撞墙论”的观点,也找到了Sam Altman到对Scaling过程中算力重要性的强调,完整串起了一条跨越30小时对话、相隔数万字的观点演进链。GLM-5.2最后给出总结,2023年时大家讨论的还是单一预训练Scaling,但之后Scaling Law的定义不断扩展,演变出了四条曲线,涵盖预训练、后训练、测试时以及智能体。它还判断,目前主要的难点仍然是在架构层面——能否真正再做出一个Transformer级别的技术创新,并从播客实录中找到了Hassabis、陶哲轩对相关问题的论述,做到有理有据。(2)主题聚类:之后,我还让GLM-5.2将散落各处、形式各异的讨论,按“推理能力提升路径”、“合成数据的有效性边界”、“Agent架构的主流选择”等主题自动归类,生成每个主题下的共识摘要与待解争议。GLM-5.2仅用时1分多钟就完成了梳理,找到9大主题,每个主题下都有来自多个不同人物的观点,显示出对数十万上下文内容的把握。我抽检了几个关键的引语,发现GLM-5.2基本没有出现幻觉,相关观点在播客实录中都可以找到印证。这类任务如果用常规上下文窗口的模型处理,只能分段投入、分批总结再人工拼接,跨实录的逻辑关联和隐性矛盾或多或少会有些丢失。为验证这一现象,我们让GLM-5.1(20万上下文窗口)试了试同一个跨期观点追踪任务。最终,GLM-5.1虽然也可以逐步读完这些内容,但其输出的总结更像是逐个阅读文件后,对每个文件进行提炼然后汇总,观点在不同时期如何变化、彼此之间有何联系,这些需要跨越多文件才能提炼出来的细节,GLM-5.1没能成功定位。不过,并不是所有任务,都必然需要GLM-5.2的百万上下文能力。在一些轻量级任务上,GLM-5.1和GLM-5.2并不会带来明显的使用体感差异。比如,我让GLM-5.1和GLM-5.2做了同样的轻量Web UI开发工作,两个模型的输出速度和质量都基本一致。在像是单文件代码补全、简单脚本编写、日常问答或短文档摘要这类任务上,两个模型的输出质量也基本持平。百万上下文的优势主要显现在需要跨区段关联信息的超长任务中,日常开发中大部分小修小改,200K窗口已经足够,不必为了1M而1M。03.百万上下文的真正挑战:装下只是开始,好用便宜才是关键那么,智谱在GLM-5.2上到底采用了哪些技术,才实现了百万上下文窗口,并让模型真正能有效利用它?其实,智谱在GLM-4时代就曾推出过百万上下文窗口的模型,但其大部分模型此前仍维持着较小的上下文窗口。在百万级上下文窗口中,单纯强调“长度”本身意义有限。真正的挑战在于,随着上下文规模扩展,模型注意力机制的计算复杂度呈平方式增长。要让100万token的上下文不只是参数表上的一个数字,而是真正可用,就要解决两个核心问题:模型效果能否在从0到100万token的全程中不出现明显衰减,以及推理成本能否控制在可用的范围内。这背后涉及大量的工程工作。GLM-5.2在这一问题上的思路是从推理基础设施层面和模型架构层做协同优化。围绕长序列的效率瓶颈,智谱引入了IndexShare 、KVShare、LayerSplit和HiSparse的组合方案。模型架构层,智谱改进了GLM-5.2的MTP层以实现更好的推测解码。他们在MTP层应用了IndexShare和KVShare的组合方案。此前,MTP每预测一步,都要做一次注意力计算,而GLM-5.2在多步MTP中,只在第一步计算索引器(indexer),得到topk索引后,后续所有步骤直接复用,不再重复计算。其中,LayerSplit已在GLM-5系列模型“降智”问题优化的工程实践中得到验证。GLM主打的Coding Agent工作负载以上下文长、Prefix缓存命中率高为特点,这使得Context Parallel(CP,上下文并行)成为Prefill节点的主要并行策略。在基础设施层,智谱提出的LayerSplit已在GLM-5系列模型“降智”问题优化的工程实践中得到验证。这项技术针对Coding Agent工作负载以上下文长、Prefix缓存命中率高特点,重点解决KV缓存冗余存储问题,其核心思路是:每张GPU仅持有部分层的KV Cache,从而显著降低单卡显存占用。计算时,持有某一层Cache的CP rank会在Attention计算前将其广播给其他rank。为进一步减少开销,智谱设计了KV Cache广播与Indexer计算的重叠机制,使二者在时间上相互掩盖。整个流程仅额外引入约为KV Cache体量1/8的Indexer Cache广播,通信成本对性能影响可忽略。实验结果表明,在32k-1024k的请求长度区间内,GLM-5.2的系统吞吐量较GLM-5.1实现了3%-192%的提升,且上下文越长收益越显著。同时,智谱还根据模型的稀疏注意力特性,设计了一套名为HiSparse的分层内存系统。该系统可以主动将非活跃的KV缓存条目卸载至主机内存,大幅缓解GPU显存压力,同时在GPU HBM中维护热点设备缓存区,存放高频访问的KV缓存区域,以此最小化关键路径上的数据迁移开销。这些优化共同降低了长序列推理的显存占用和延迟,使100万上下文从仅仅"能跑",变成真的“用得起”、“好用”。智谱称,GLM-5.2的线上推理依托多个国产算力平台,已在Day 0完成与华为昇腾、平头哥、摩尔线程、寒武纪、昆仑芯、沐曦、海光、壁仞等国产算力平台的推理适配。此外,GLM-5.2还新增了High与Max两档思考强度(thinking effort)设定,复杂编码任务中可启用更高档位以确保架构级逻辑的严谨性。智谱GLM-5.2的百万级上下文能力,将解锁许多新的AI应用场景。例如,在复杂的Web Search类任务中,GLM-5.2可以基于公开资料,调研12-15个主流K12在线编程教育品牌,并输出完整的xlsx数据库、分析报告和图表。结合智谱的Agent产品AutoClaw,GLM-5.2的100万上下文与长程任务能力可以服务于设计、法务等白领场景,例如一次性写出数十个原型页面,自主迭代和微调,在设计中保持品牌规范与一致性。在这些类型的任务上,GLM-5.2带来的本质差异不在于结果好还是坏,而是“能用还是不能用”。这些任务的量级、复杂度,是其他不具备百万上下文能力的模型所难以想象的。04.结语:智谱补齐长程任务技术拼图回顾智谱近期的技术路线,从GLM-5.1将开源模型的长程任务能力推进8小时级,到GLM-5.2以1M上下文将这一能力进一步延展,其技术拼图的脉络是清晰的:先让模型能持续工作更久,再为它配备足够大的记忆容量。长程任务的失败,很多时候不是模型不够聪明,而是它忘了最初的约束,1M上下文解决的正是这个问题。当补齐这些能力拼图后,智谱GLM系列模型在真正工程任务中的可用性有望进一步提升。在实测中,GLM-5.2已经完整跑通理解需求、设计方案、写代码、跑测试、修bug,到最终交付的闭环,我不再需要逐段拆解任务、反复喂入背景信息、检查中间步骤是否偏离初衷。当模型既能工作得久、又能记得住,它才真正具备了成为长期协作伙伴的基础。这也是从“对话式AI”走向“执行式AI”的关键一步。