> 作者:李剑锋
1. 前言
在前面的课程中,我们已经围绕大模型的使用与优化,学习了提示词设计、RAG 知识库问答、监督微调、模型部署以及模型测评等内容。通过这些内容,我们其实已经逐步建立起了一条比较完整的大语言模型实践链路:先让模型能够按照提示完成任务,再通过外部知识增强模型能力,进一步通过微调调整模型行为,最后再将模型部署成可调用的服务,并通过测评观察模型效果。
不过,前面的大部分实践仍然主要围绕“文本大模型”展开。也就是说,模型接收的主要是文本,输出的也主要是文本。但在真实应用中,很多信息并不是以文本形式存在的。例如图片中的物体、视频中的动作、截图中的界面、票据中的字段、医学影像中的异常区域、工业场景中的设备状态等,都属于视觉信息。如果模型只能处理文本,那么它能够理解的世界其实仍然是受限的。
而视觉大模型的出现,正是为了让大模型从“只理解文字”进一步走向“能够理解图像和视频”。它不仅可以回答文字问题,还可以结合图片、视频等多模态输入完成描述、识别、问答、分析和推理等任务。因此,从文本大模型过渡到视觉大模型,并不是简单地多传入一张图片,而是意味着模型的输入形式、数据格式、训练方式、推理流程和部署参数都会发生变化。
因此,本节将以视觉大模型为主线,系统梳理从模型调用、数据准备、LoRA 微调,到推理部署、接口封装、效果测评与模型发布的完整实践流程。与前面主要基于 Transformers 编写推理代码的方式不同,这一节将进一步引入 ModelScope 生态中的 ms-swift 作为核心实践框架。
之所以在这一节选择 ms-swift,关键并不只是因为它能够支持微调训练,而在于它更适合作为视觉大模型工程流程的统一入口。前面使用 Transformers,重点在于帮助我们理解模型加载、输入构造与生成调用等底层机制;而在视觉大模型场景下,真正的实践重点已经不再局限于“把模型跑起来”,而是进一步扩展到模型获取、数据集组织、参数高效微调、量化导出、推理加速、服务部署以及效果评测等一整套工程环节。

从工具生态上看,ms-swift 与 ModelScope 的模型和数据集资源衔接较为紧密,能够较自然地承接开源模型选择、训练数据准备和实验流程配置;同时,它还可以与 EvalScope 结合完成模型测评,并在部署与推理阶段对接 vLLM、LMDeploy、SGLang 等常见后端,在量化侧也支持 AWQ、GPTQ、FP8、BNB 等多种导出方案。这样一来,本节内容就不需要再将训练、部署、测评、量化等环节割裂开来分别处理,而是可以围绕一套相对统一的工具链,完成视觉大模型从训练、优化到部署落地的完整闭环。
那接下来,我们将以 Qwen3-VL 为例,从最基础的视觉大模型概念开始,逐步完成模型下载、图片与视频推理、ms-swift 命令行调用、视觉大模型微调、vLLM 后端部署、OpenAI 风格接口调用、模型测评与模型上传等步骤,完整跑通一次视觉大模型调优与部署流程。
2. 视觉大模型:从“理解文字”到“理解图像和视频”
2.1 什么是视觉大模型
视觉大模型通常也被称为 VLM,也就是 Vision-Language Model,中文可以理解为“视觉语言模型”。它是一类能够同时处理视觉信息和文本信息的大模型。和普通大语言模型主要接收文本输入不同,视觉大模型的输入可以同时包含图片、视频和文字,并根据这些多模态信息生成自然语言回答。
例如,我们可以给模型输入一张图片,并提问“这张图里有什么?”;也可以输入一张网页截图,并提问“登录按钮在哪里?”;还可以输入一段视频,并要求模型描述视频中发生了什么。此时,模型要完成的并不只是文本生成,而是需要先理解视觉内容,再结合用户的文字指令进行分析和回答。

从任务形式上看,视觉大模型通常可以处理以下几类输入:
图片 + 问题
视频 + 问题
截图 + 指令
文档图片 + 抽取要求
图文混合上下文 + 多轮对话
虽然最终输出大多仍然是文本,但模型内部处理的信息已经不再只是文本 token,而是同时包含了视觉信息和语言信息。也就是说,视觉大模型并不是简单地“多接收一张图片”,而是需要把图片或视频转换成模型能够理解的视觉表示,再和文本指令一起送入模型进行推理。
从整体结构上看,一个典型的视觉大模型通常可以拆成三部分:
视觉输入
↓
视觉编码模块
↓
视觉特征 / 视觉 token
↓
多模态连接模块
↓
大语言模型
↓
文本回答
其中,视觉编码模块负责把图片或视频转换成视觉特征;多模态连接模块负责把这些视觉特征映射到语言模型可以理解的表示空间;大语言模型则负责结合视觉信息和文本指令,完成理解、推理和生成。在下面的章节中我们将会对这部分内容进行更详细的讲解。
因此,VLM 的核心并不是“把图片先转成文字,再交给 LLM 回答”,而是让模型在内部直接对视觉信息和语言信息进行联合建模。这样一来,模型不仅可以描述图片中有什么,还可以根据用户的问题关注图像中的特定区域、分析视觉关系、理解截图结构,甚至结合视频帧之间的变化进行推理。
所以,简单来说,视觉大模型可以理解为是一种能够看懂图片或视频,并结合文字指令进行理解、分析和回答的大模型。这个概念上的裂解对于后续视觉大模型调用、微调和部署都非常重要。由于输入不再只是文本,模型需要同时处理视觉内容和语言指令,因此数据格式、显存占用、推理参数和部署方式都会和普通文本大模型有所不同。
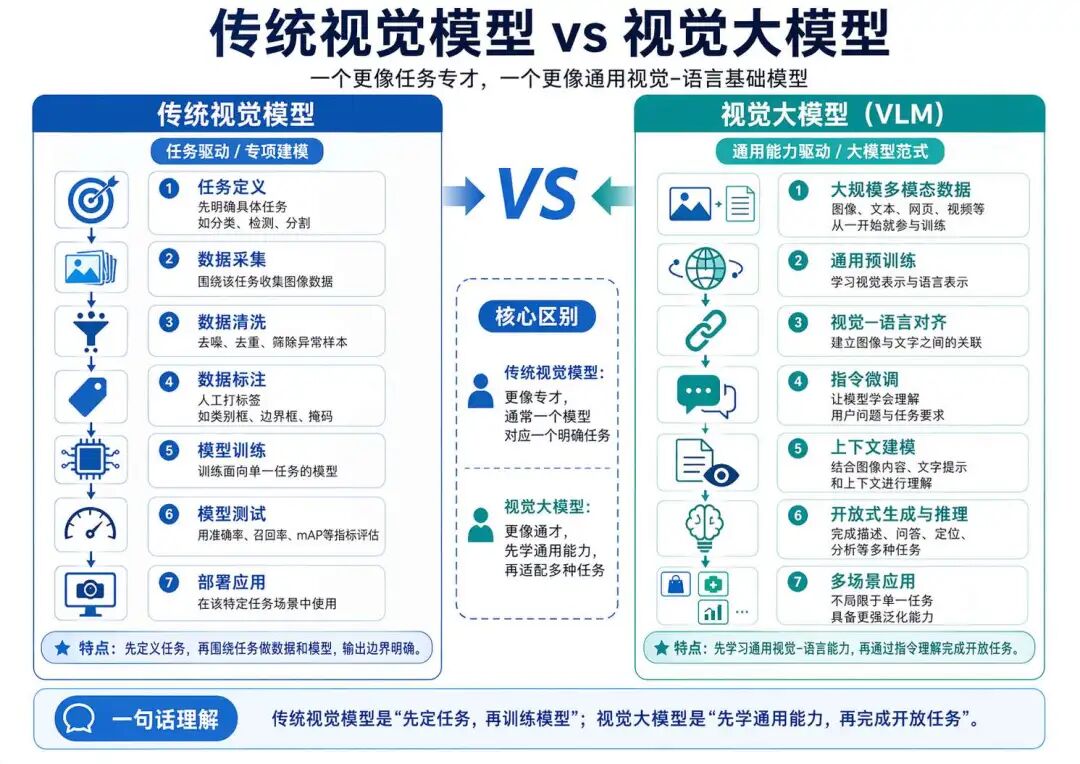
2.2 VLM 和传统视觉模型有什么区别
需要说明的是,视觉模型并不是视觉大模型出现之后才有的。早在大模型流行之前,计算机视觉领域就已经发展出了大量成熟的视觉模型和任务范式,例如图像分类、目标检测、图像分割、OCR 文字识别以及视频动作识别等。这些模型在工业质检、安防监控、医学影像、自动驾驶、票据识别等场景中已经有了非常广泛的应用。

不过,传统视觉模型大多是围绕某一类具体任务设计的。比如,图像分类模型主要判断“这张图属于什么类别”,目标检测模型主要判断“图中有哪些物体以及它们在哪里”,OCR 模型主要识别“图片中有哪些文字”。它们的任务目标通常比较明确,输入输出形式也相对固定。

而视觉大模型的出现,并不是简单地把这些传统视觉任务重新做一遍,而是引入了一种新的视觉理解方式:模型不再只输出固定类别、坐标框或识别文本,而是可以结合用户的自然语言指令,对图片或视频内容进行描述、问答、分析和推理。
因此,传统视觉模型和视觉大模型之间的核心区别,不在于前者“不会看图”、后者“会看图”,而在于二者处理视觉信息的方式不同。传统视觉模型更像是面向特定任务的专用工具,而视觉大模型更像是能够围绕视觉内容进行开放式交互的通用助手。
更具体地说,两者的区别主要体现在以下几个方面。
2.2.1 任务目标不同
传统视觉模型通常面向的是一个明确、封闭的任务。例如,图像分类模型的目标是判断图片属于哪个类别;目标检测模型的目标是找出图中有哪些物体以及它们的位置;OCR 模型的目标是识别图片中的文字内容。也就是说,它们往往是在“一个模型对应一类任务”的思路下构建的。
而视觉大模型的目标并不是只解决某一个固定任务,而是希望模型具备更通用的视觉理解能力。它既可以描述图片内容,也可以回答与图片相关的问题,还可以完成文档理解、界面分析、视频摘要甚至多轮视觉对话等任务。
举个简单例子,假设输入的是一张“教室上课”的图片。传统图像分类模型可能只会判断这是一张“教室”或“课堂”相关图片;目标检测模型可能会识别出其中的“学生”“老师”“桌子”“黑板”等对象;OCR 模型可能会识别黑板或投影上的文字。
而视觉大模型面对同一张图片时,则可以根据不同问题完成不同任务。例如,用户问“这张图里发生了什么”,它可以描述课堂场景;用户问“老师在做什么”,它可以关注画面中的人物行为;用户问“这节课可能在讲什么内容”,它还可以结合黑板、投影和人物动作进行综合判断。也就是说,视觉大模型的任务目标不是固定在某一个类别或检测结果上,而是可以随着用户指令发生变化。
2.2.2 输出形式不同
在输出形式上,传统视觉模型的输出通常是结构化且固定的。例如:
图像分类输出的是类别标签;
{
"label": "classroom",
"label_zh": "教室",
"score": 0.97
}
目标检测输出的是类别和边界框坐标,例如 [x1, y1, x2, y2];
[
{"label": "teacher", "bbox": [210, 85, 320, 310], "score": 0.96},
{"label": "student", "bbox": [40, 220, 130, 410], "score": 0.94},
{"label": "student", "bbox": [150, 240, 250, 420], "score": 0.92},
{"label": "blackboard", "bbox": [60, 40, 360, 210], "score": 0.98},
{"label": "desk", "bbox": [20, 300, 360, 470], "score": 0.90}
]
图像分割输出的是像素级掩码;
{
"mask_labels": {
0: "background",
1: "teacher",
2: "student",
3: "blackboard",
4: "desk"
},
"mask": [
[0, 0, 0, 3, 3, 3],
[0, 0, 1, 1, 3, 3],
[0, 2, 2, 1, 0, 0],
[0, 2, 2, 4, 4, 0]
]
}
OCR 输出的是识别出的文字内容。
[
{"text": "二次函数的图像", "bbox": [380, 55, 560, 95], "score": 0.99},
{"text": "1. 开口方向", "bbox": [400, 120, 520, 150], "score": 0.97},
{"text": "2. 对称轴", "bbox": [400, 160, 500, 190], "score": 0.96},
{"text": "3. 顶点坐标", "bbox": [400, 200, 520, 230], "score": 0.95}
]
这些输出往往是预先定义好的,形式比较固定,也比较适合在明确指标下进行评估。而视觉大模型的输出通常是自然语言,或者是自然语言驱动下的结构化结果。也就是说,它不仅可以“识别出内容”,还可以“把理解结果说出来”。例如,同样面对一张图片,传统分类模型可能输出“cat”,而视觉大模型则可能回答“图中有一只坐在窗台上的猫,正在看向窗外”。
2.2.3 交互方式不同
传统视觉模型通常是“单次输入、单次输出”的任务处理方式。输入一张图像,模型返回一个结果,流程就结束了。模型本身并不会理解用户额外提出的问题,也不会根据不同提问角度调整回答内容。
视觉大模型则具有明显的交互属性。用户不仅可以上传图片,还可以围绕同一张图片连续提问。例如:
“这张图里有什么?” “左边的人在做什么?” “图中最可能发生的场景是什么?” “如果把这张图作为广告素材,它适合表达什么主题?”
这说明视觉大模型并不是简单完成一次视觉识别,而是在视觉理解基础上支持更开放的语言交互。
2.2.4 通用性不同
传统视觉模型通常是“任务专用型”的。一个分类模型很难直接拿去做 OCR,一个检测模型也不能直接完成视觉问答。如果要覆盖多种任务,往往需要分别训练不同模型,或者为不同任务设计不同模块。
视觉大模型则更接近“通用模型”的思路。通过统一的图像/视频输入与文本指令机制,同一个模型可以在不同任务之间切换。用户只需要改变提示词或任务指令,模型就可以在图像描述、视觉问答、文档理解、界面分析等任务之间进行迁移。
当然,这种“通用性”并不意味着它在所有单项任务上都一定优于专用模型,而是意味着它在任务覆盖范围和交互灵活性上具有更强的统一能力。
2.2.5 建模思路不同
传统视觉模型的核心思路通常是:围绕某个明确任务,学习从视觉输入到任务标签之间的映射关系。它更强调任务目标清晰、输出边界明确、评测指标确定。
视觉大模型的建模思路则更接近“大模型范式”,即先学习通用的视觉—语言对齐能力,再通过指令理解、上下文建模和语言生成完成开放式任务。换句话说,传统视觉模型更像是“专才”,而视觉大模型更像是“通才”。

2.2.6 小结
因此,可以把两者的区别概括为一句话:传统视觉模型主要解决“看到了什么”的特定任务问题,而视觉大模型进一步解决“如何围绕所看到的内容进行理解、问答与推理”的通用任务问题。
不过也需要说明的是,视觉大模型并不是要完全替代传统视觉模型。对于一些目标非常明确、对速度和精度要求很高的专用场景,传统视觉模型仍然具有很强的实用价值。而视觉大模型的优势,更多体现在任务统一、交互灵活和跨任务泛化能力上。
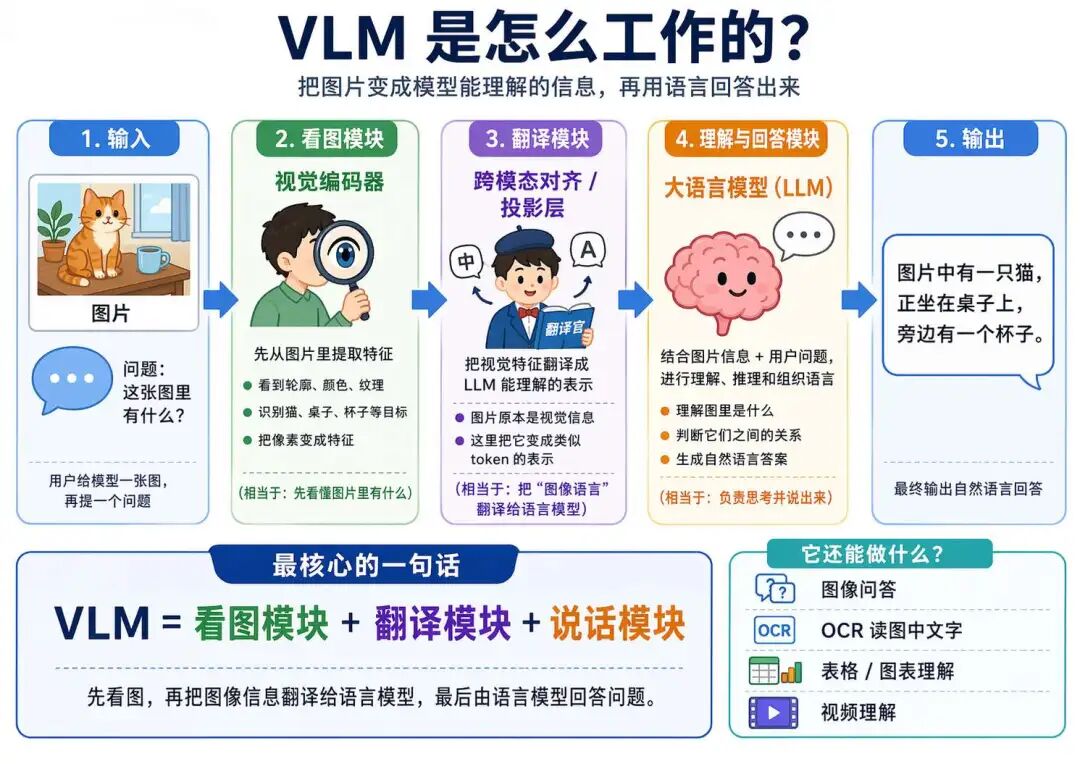
2.3 VLM 的核心架构
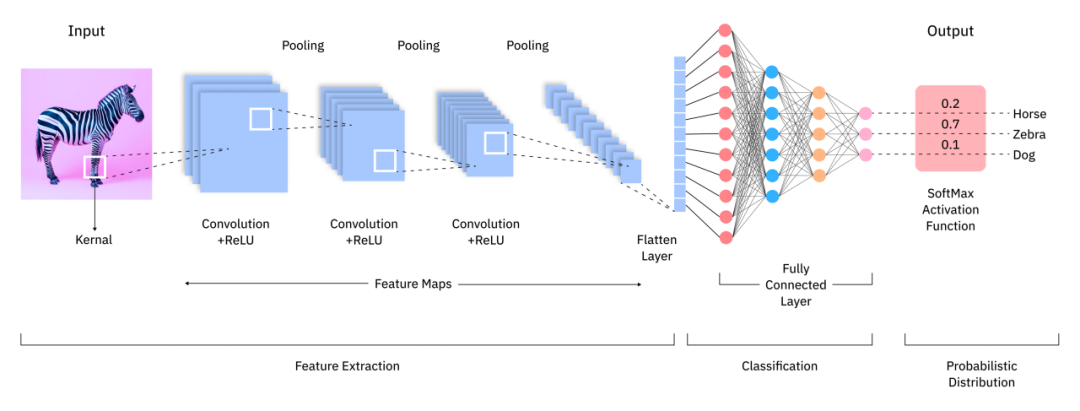
视觉大模型并不是简单地把图片直接丢给大语言模型。因为图片本身是像素矩阵,而语言模型真正擅长处理的是 token 序列。两者的数据形式完全不同,所以中间必须有一套结构,把视觉信息转换成语言模型能够理解的表示。
一个典型的 VLM 架构,通常可以拆成四个核心部分:
视觉输入 → 视觉编码器 → 跨模态连接器 → 大语言模型 → 文本输出
其中,真正承担核心功能的主要是三部分:视觉编码器、跨模态连接器和大语言模型。它们分别负责“看图”“对齐”“回答”这三个关键环节。
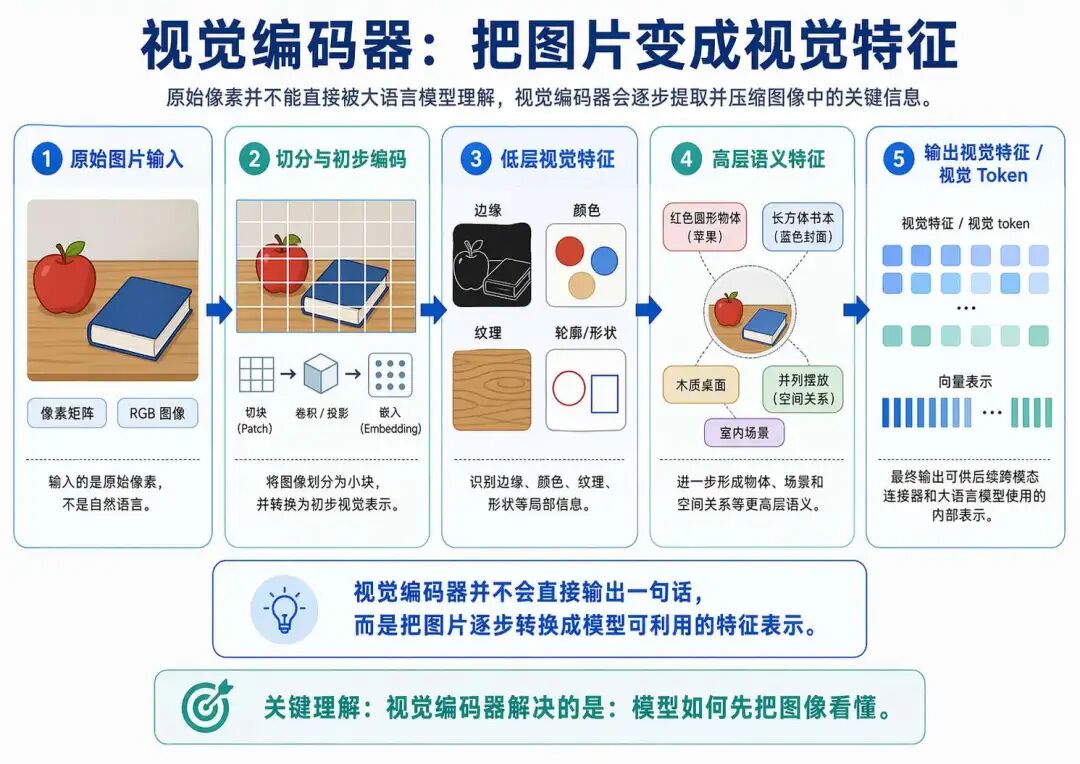
2.3.1 视觉编码器
视觉编码器可以理解为 VLM 的“眼睛”。它的主要作用,是把原始图像中的像素信息转化为更高层次的视觉特征表示。
对于模型来说,一张图片并不是一句自然语言,而是一大堆像素值。模型如果想理解图片里到底有什么,就必须先经过视觉编码器,将这些像素提炼成有意义的特征。例如,图中的物体轮廓、颜色分布、空间位置、局部区域关系,甚至图像中的文字信息,都会在这一阶段被逐步编码出来。
通俗来说,视觉编码器要完成的事情,就是把“原始图片”转成“模型能够利用的视觉特征”。举个例子,输入一张“桌子上有一个苹果和一本书”的图片,那么视觉编码器不会直接输出一句话,而是先提取出诸如“红色圆形物体”“长方体书本结构”“木质桌面背景”“两个物体并列摆放”等视觉信息,并把它们表示成内部向量。

因此,这一部分解决的是模型如何先把图像看懂。
2.3.2 跨模态连接器
有了视觉特征之后,虽然已经将图片转化为 token 的形式了,但是此时还不能直接让语言模型使用。因为视觉编码器输出的是视觉表示,而大语言模型擅长处理的是文本 token 对应的表示空间。二者虽然都可以用向量表示,但来源不同、结构不同、语义组织方式也不同。因此这时候就需要跨模态连接器进行转换。
跨模态连接器的作用可以理解为是把视觉编码器提取出的视觉特征,转换成大语言模型能够接收和处理的形式。如果说视觉编码器负责“看”,大语言模型负责“说”,那么跨模态连接器就负责把“看到的内容”翻译成“语言模型能理解的内部表示”。这一点非常关键。因为 VLM 的核心并不只是“图像识别”,而是要做到:
图像内容 + 用户问题 → 联合理解 → 生成回答
而视觉信息和语言信息要能在同一套推理过程中共同发挥作用,就必须先完成这种跨模态映射与对齐。
从工程实现上看,不同 VLM 所使用的连接器结构可能不一样。有的比较简单,使用投影层或 MLP;有的更复杂,会使用专门的 Query 模块或更强的适配结构。但从教学和理解角度来说,我们可以把它统一理解为负责“对齐视觉表示和语言表示”的中间模块。

因此,这一部分解决的是模型如何把图像信息送入语言模型。
2.3.3 大语言模型
当前两部分完成之后,视觉信息就已经以一种语言模型可以接受的形式进入了系统。接下来,大语言模型就开始发挥它最擅长的能力:理解指令、结合上下文、组织语言并生成回答。
也就是说,在 VLM 中,LLM 依然是非常关键的核心部分。它并没有被替代,而是在原有语言理解与生成能力的基础上,进一步接入了视觉信息。
例如,用户提出:
“这张图里有什么?” “登录按钮在哪里?” “图表反映了什么趋势?” “视频中这个人在做什么?”
这些问题本质上仍然是自然语言指令。大语言模型需要先理解用户到底想问什么,然后结合前面输入的视觉信息,生成最终回答。
所以,大语言模型在 VLM 中主要承担三类工作:
理解用户指令:它要知道用户是在让模型做描述、定位、解释、比较,还是推理。 结合视觉信息进行推理:它不能只根据文字猜,而是要把视觉特征一起纳入上下文。 生成自然语言回答:最终把理解结果组织成用户可以直接阅读的文字输出。

因此,这一部分解决的是模型如何根据图像和问题给出自然语言回答。
2.3.4 小结
通过上面的介绍可以看到,视觉大模型的核心并不是简单地“给大语言模型加一张图片”,而是要在图像和语言之间建立一条可以共同理解和推理的通路。
在这条通路中,视觉编码器负责把原始图片或视频转换成视觉特征,相当于帮助模型完成“看图”的过程;跨模态连接器负责将这些视觉特征映射到语言模型能够处理的表示空间中,相当于完成视觉信息与语言表示之间的“对齐”;大语言模型则负责理解用户指令,并结合视觉信息生成最终回答。
也正因为多了视觉编码和跨模态对齐这两个环节,视觉大模型在数据格式、显存占用、推理速度和部署参数上,都会比普通文本大模型更加复杂。后面在使用 ms-swift 进行视觉大模型调用、微调和部署时,我们遇到的图片 token 数量、视频帧数限制、视觉输入长度控制等问题,本质上都和这一架构特点有关。
2.4 从 Qwen-VL 到 Qwen3-VL:视觉语言模型的持续演进
前面我们已经了解了 VLM 的基本结构,它通过视觉编码器理解图像或视频,再把视觉信息转换成大语言模型可以处理的形式,最后结合用户的问题生成回答。不过,理解基本结构只是第一步。接下来如果想真正进入实战,我们还需要选择一个具体的模型系列,看看这些原理在真实模型中是如何落地的。
这里我们首先选择 Qwen-VL 系列 作为后续实战对象。原因并不只是它“能看图”,而是因为它有比较清晰的技术演进路线:从 Qwen-VL,到 Qwen2-VL、Qwen2.5-VL,再到 Qwen3-VL,每一代都在围绕图像理解、OCR、文档解析、图表理解、视频理解等实际任务不断升级。
同时,Qwen-VL 系列和 Qwen、ModelScope、ms-swift 等生态结合比较紧密,后续无论是模型下载、数据准备、推理测试,还是微调训练和部署调用,都比较适合作为教学和实战案例。
所以,接下来我们会以 Qwen-VL 系列为主线,把前面讲到的 VLM 基本原理,进一步过渡到真实的模型调用、微调和部署流程中。
2.4.1 Qwen-VL:让 Qwen 从文本模型走向视觉语言模型
最早的 Qwen-VL,可以看作 Qwen 系列从文本大模型走向视觉语言模型的重要起点。它的核心思路,是在原有 Qwen 语言模型的基础上接入视觉编码器,使模型不仅能够处理文本,还能够接收图像输入,并围绕图像内容进行描述、问答和理解。
从结构上看,Qwen-VL 大致由三部分组成:底部的 ViT 视觉编码器负责提取图像特征,中间的 Cross-Attention 模块负责连接视觉特征和语言模型,顶部的 QwenLM 则负责理解指令并生成回答。也就是说,ViT 负责“看图”,Cross-Attention 负责“把图像信息传给语言模型”,QwenLM 负责“根据图像和问题进行回答”。
从图中的训练流程可以看到,Qwen-VL 并不是一次性完成所有能力训练,而是采用了分阶段训练的方式。
第一阶段是预训练阶段。这个阶段主要使用图文对数据,让模型先学习图像和文本之间的基础对应关系。图中可以看到,此时 QwenLM 被冻结,训练重点主要放在 ViT 和 Cross-Attention 等视觉接入部分。这样做的目的,是在尽量保持语言模型原有能力的基础上,让新增的视觉模块先学会如何把图像信息接入到语言模型中。
第二阶段是多任务预训练阶段。这个阶段开始使用更高分辨率的图像,以及多任务、交错式的视觉语言数据。相比第一阶段简单的图文对,第二阶段的数据形式更加丰富,模型需要处理的不再只是“图片对应一段文本”,还包括多图、图文交错、视觉问答等更复杂的任务。因此,这一阶段会进一步训练 ViT、Cross-Attention 和 QwenLM,使视觉理解能力和语言生成能力更加紧密地结合起来。
第三阶段是监督微调阶段。这个阶段主要使用面向对话和指令跟随的视觉语言数据,例如图文交错对话、多轮问答等。图中可以看到,此时 ViT 被冻结,而 QwenLM 和 Cross-Attention 继续训练。也就是说,模型在已经具备基本视觉理解能力的基础上,进一步学习如何按照用户指令进行回答,使其更适合真实交互场景。
因此,Qwen-VL 的意义并不只是“让 Qwen 能看图”,更重要的是它提供了一种比较清晰的视觉语言模型构建方式:先让视觉模块学会提取图像信息,再通过连接模块把视觉特征对齐到语言模型,最后通过多任务和指令微调,让模型具备图像问答、多图理解、多轮对话和图文交互能力。
不过,尽管 Qwen-VL 已经具备了较完整的基础视觉语言能力,但它在输入分辨率适配、长图文档理解、视频处理以及更复杂的多模态任务上仍然存在进一步提升空间。后续的 Qwen2-VL、Qwen2.5-VL 和 Qwen3-VL,正是在这些方向上不断继续演进。
2.4.2 Qwen2-VL:更灵活地处理不同尺寸的图像和视频
到了 Qwen2-VL 阶段,模型开始重点解决一个非常实际的问题:真实世界中的视觉输入并不是统一规格的。图片可能是普通照片,也可能是长文档截图、网页截图、极端长宽比图片或高清图表;视频则还会包含不同帧数和不同时间长度。如果简单地把所有图片都缩放到固定大小,就容易损失细节,尤其是文档、表格、截图中的小字和局部结构。
因此,Qwen2-VL 的一个重要升级,是引入动态分辨率机制。它不再把所有图片都压缩成固定视觉 token 数量,而是根据图像自身的分辨率和复杂度,动态生成不同数量的视觉 token。这样一来,对于高分辨率文档或复杂图片,模型可以保留更多细节;对于较小或较简单的图片,则可以减少不必要的视觉 token 开销。

除了动态分辨率之外,Qwen2-VL 还引入了 M-RoPE,也就是多模态旋转位置编码。普通文本的位置关系主要是一维顺序,而图像具有二维空间结构,视频还额外包含时间维度。M-RoPE 的作用,就是把文本的一维位置、图像的二维位置和视频的三维时空位置统一纳入位置建模中,从而让模型更好地理解图文视频混合输入。
所以,如果说 Qwen-VL 解决的是“让模型具备基础看图能力”,那么 Qwen2-VL 进一步解决的就是“如何让模型更自然地处理不同尺寸、不同形态的图片和视频”。这一步非常关键,因为它让 VLM 从相对理想化的图文输入,进一步走向真实世界中更加复杂、更加不规则的视觉输入。
2.4.3 Qwen2.5-VL:面向文档、长视频和智能体场景继续增强
随后,Qwen2.5-VL 在 Qwen2-VL 的基础上继续增强。它并没有推翻 Qwen2-VL 的设计,而是在动态分辨率、多模态位置编码和图文视频统一建模的基础上,进一步面向真实应用场景进行优化。
相比 Qwen2-VL,Qwen2.5-VL 更强调文档解析、表格与票据抽取、图表理解、精确目标定位、长视频理解和视觉智能体等任务。对于这些任务来说,模型不仅要“看见内容”,还要理解页面布局、结构关系、目标位置、时间顺序和操作意图。例如,在票据场景中,模型需要抽取金额、日期、商户等结构化信息;在图表场景中,模型需要理解坐标轴、趋势和数值关系;在长视频场景中,模型需要知道某个事件大概发生在什么时间位置。

从架构和输入处理上看,Qwen2.5-VL 继续强调原生分辨率输入,并在视觉编码器上进行优化。它通过原生动态分辨率 ViT 和 Window Attention,在尽量保留视觉细节的同时降低视觉侧计算开销。简单来说,Window Attention 可以让模型优先在局部窗口内计算注意力,从而更高效地处理高分辨率视觉输入;而必要的全局信息交互则用于补充整体理解。
在视频理解方面,Qwen2.5-VL 也进行了进一步增强。视频相比图片多了时间维度,模型不仅要理解“画面中有什么”,还要理解“什么时候发生了什么”。因此,Qwen2.5-VL 引入动态 FPS 采样和绝对时间编码,使模型可以处理更长的视频,并支持秒级事件定位。
所以,Qwen2.5-VL 相比 Qwen2-VL 的重点,不只是“更灵活地看图”,而是进一步走向“能看复杂文档、能理解长视频、能定位目标、能抽取结构化信息、能参与视觉智能体任务”。它解决的是视觉语言模型从通用图文理解走向真实业务场景时遇到的一系列复杂问题。
2.4.4 Qwen3-VL:传统 VLM 范式下的综合升级
到了 Qwen3-VL 阶段,模型继续在视觉感知、空间理解、视频动态建模、长上下文和复杂视觉推理等方向上增强。它依然延续了“视觉输入 → Vision Encoder → 语言模型 Decoder”的 VLM 主线,但相比 Qwen2-VL 和 Qwen2.5-VL,Qwen3-VL 在视觉 token 组织、空间时间位置建模、多层视觉特征融合和视频事件对齐方面做了更系统的升级。

首先是位置建模能力的增强。对于文本来说,位置主要是一维顺序;对于图像来说,位置包含高度和宽度;对于视频来说,还要额外考虑时间维度。Qwen3-VL 引入 Interleaved-MRoPE,用于更细致地建模时间、高度和宽度之间的位置关系,从而增强模型对长视频、复杂空间场景和图文视频交错输入的理解能力。
其次是多层视觉特征融合。视觉编码器不同层次的特征往往包含不同信息:浅层更偏向边缘、颜色、纹理等细节,深层更偏向物体、语义和整体关系。如果只使用最后一层视觉特征,可能会损失一部分细粒度信息。Qwen3-VL 中的 DeepStack 思路,就是把多层 ViT 特征融合进语言模型,使模型能够利用更丰富的视觉层次信息,从而提升细节理解和图文对齐能力。
第三是视频时间理解能力的增强。视频不是静态图片,而是连续发生的视觉事件。用户在视频任务中经常会问“某个动作什么时候发生”“某个事件出现在第几秒附近”。Qwen3-VL 通过 Text-Timestamp Alignment,让视频中的时间信息可以更明确地和文本描述对齐,从而提升视频事件定位和时间相关问答能力。

因此,Qwen3-VL 可以看作 Qwen-VL 系列在传统 VLM 范式下的一次阶段性综合升级。它不是简单地“模型更大”或“能看更多图片”,而是进一步强化了视觉信息如何被编码、定位、融合,并参与复杂推理。也正因为如此,Qwen3-VL 非常适合作为本节视觉大模型调优与部署的实践对象:它既能体现 VLM 的典型工程流程,又能覆盖图片问答、视频理解、OCR、文档解析、GUI 理解和空间推理等较完整的视觉语言任务。
2.4.5 小结
回顾 Qwen-VL 到 Qwen3-VL 的演进,可以看到这条路线始终围绕一个核心目标展开:让模型更好地理解视觉信息,并把视觉信息纳入语言推理和任务执行过程。
可以简单概括为:
Qwen-VL:
让 Qwen 从纯文本模型扩展为能够理解图像和文字的视觉语言模型。
Qwen2-VL:
通过动态分辨率和多模态位置编码,让模型更灵活地处理不同尺寸图像和视频。
Qwen2.5-VL:
面向真实应用场景,强化文档解析、目标定位、图表理解、长视频理解和视觉智能体能力。
Qwen3-VL:
进一步增强空间位置建模、多层视觉特征融合、长视频时间对齐和复杂视觉推理能力。
从这个角度看,Qwen-VL 系列的升级并不是单纯追求“模型更大”,而是在不断解决视觉大模型落地中的关键问题:如何保留高分辨率图像细节,如何处理不同形态的视觉输入,如何理解文档和图表结构,如何对长视频进行时间建模,以及如何让视觉信息更深入地参与语言推理。
理解了这条演进线之后,后面我们再进入 Qwen3-VL 的调用、微调、部署和测评,就会更加清楚每一个工程参数背后的意义。比如图片 token 数量、视频帧数限制、动态分辨率处理、显存占用和推理速度,本质上都和视觉信息如何被编码、组织和送入语言模型有关。
2.5 视觉大模型的典型应用场景
那在了解了关于视觉大模型的架构以及具体模型情况后,最后我们来看看到底视觉大模型最常用的应用场景在哪里。
在前面介绍 Qwen-VL 系列的演进时,我们已经看到,视觉大模型的发展并不是单纯为了让模型“能看见图片”,而是为了让模型能够围绕视觉内容完成更加丰富的理解、问答、分析和推理任务。也就是说,VLM 的价值不只体现在模型结构上,更体现在它能够把图像、视频、文档、界面等视觉信息转化为可交互、可推理、可应用的结果。
从 Qwen-VL 和 Qwen2-VL 论文中的示例图也可以看到,视觉大模型的应用范围正在不断扩大。早期 Qwen-VL 已经能够完成多图输入、多轮对话、图像文字识别、视觉定位、细粒度识别等任务:
而到了 Qwen2-VL,能力进一步扩展到视频理解、长文档理解、多语言 OCR、数学与代码推理、公式识别、函数调用、UI 交互和智能体任务等更复杂的场景:
因此,我们可以从以下几个方向来理解视觉大模型的典型应用。
2.5.1 图像问答与多轮视觉对话
最基础、也最容易理解的一类应用,是图像问答和多轮视觉对话。用户可以上传一张图片,然后围绕图片内容提出问题,例如“图中有什么”“这个人在做什么”“这两张图片有什么区别”“图中哪个位置存在异常”等。
传统视觉模型通常只能输出固定类别、检测框或识别文本,而视觉大模型可以根据用户问题灵活组织回答。比如,同样是一张城市图片,用户可以问“这是什么城市”“两张图有什么不同”“哪张图更像现代商业区”,模型都可以结合图片内容进行自然语言解释。
其实在 Qwen-VL 的示例中已经展示了这种能力:模型可以围绕人物图片、城市图片、场景图片进行问答,也可以在多轮对话中根据用户追问继续分析图片内容。这说明视觉大模型不只是一次性识别图像,而是可以把视觉内容作为上下文,支持持续交互。
2.5.2 OCR、文档理解与结构化信息抽取
视觉大模型的另一个重要应用是 OCR 和文档理解。很多真实业务数据并不是直接以纯文本形式存在的,而是存在于扫描件、截图、票据、表格、合同、论文页面和网页图片中。
传统 OCR 主要负责把图片中的文字识别出来,但视觉大模型可以进一步理解这些文字所在的上下文和页面结构。例如,它不仅可以识别票据中的金额、日期和商户名称,还可以根据用户要求整理成结构化结果;不仅可以读出论文摘要,还可以围绕摘要内容进行解释和问答;不仅可以识别表格中的文字,还可以理解行列关系和字段含义。
从 Qwen-VL 到 Qwen2-VL 的示例可以看到,文档理解和多语言 OCR 已经成为视觉大模型的重要能力方向。尤其是在长文档、表格、票据和图表场景中,模型需要同时处理文字识别、版面布局和语义理解,这正是 VLM 相比普通 OCR 更有价值的地方。
2.5.3 视觉定位与细粒度目标理解
视觉大模型还可以用于视觉定位和细粒度目标理解。所谓视觉定位,就是根据用户的自然语言描述,在图片中找到对应目标。例如用户问“能不能找到蜘蛛侠和绿巨人”“图片中穿红衣服的人在哪里”“图中哪个区域是黑板”,模型需要理解文本描述,并在图像中找到对应位置。
这类任务和普通目标检测不同。目标检测通常依赖预定义类别,例如人、车、猫、狗等;而视觉大模型面对的是开放式文本描述,用户可以用更加自由的语言表达目标。模型需要把文本语义和图像区域对应起来,完成更灵活的图文对齐。
这类能力在工业检测、医学辅助分析、安防审查、图片检索和教育讲解等场景中都有应用价值。它可以帮助用户快速定位图像中的关键区域,也可以作为后续自动化分析或人工复核的辅助入口。
2.5.4 视频理解与事件分析
随着 VLM 从图片扩展到视频,视频理解也成为重要应用方向。视频相比图片更加复杂,因为它不仅包含空间信息,还包含时间顺序。模型不仅要看懂每一帧画面,还要理解动作如何发生、事件如何变化,以及前后片段之间有什么关系。
Qwen2-VL 的示例中已经展示了视频理解能力,例如根据视频内容进行问答、总结事件、分析画面变化等。到了后续模型,视频理解进一步向长视频、时间定位和事件分析方向发展。用户可以让模型回答“视频中发生了什么”“某个动作出现在什么时候”“前后两个片段有什么变化”等问题。
这类能力可以用于课堂视频摘要、监控视频分析、短视频内容理解、会议录像整理、运动动作分析和多媒体内容审核等场景。对于真实应用来说,视频理解的价值不只是生成一段描述,而是帮助用户从大量连续画面中提取关键信息。
2.5.5 图表、公式、数学与代码场景
视觉大模型还可以处理一些更偏知识型和专业型的视觉任务,例如图表理解、公式识别、数学题解读和代码截图分析。
在图表场景中,模型需要识别坐标轴、图例、趋势、数值变化和不同曲线之间的关系;在公式场景中,模型需要把图片中的数学表达式识别出来,并进一步解释其含义;在代码截图场景中,模型不仅要读取代码内容,还要理解代码逻辑,甚至给出运行结果或错误分析。
Qwen2-VL 的能力示例中就包含 Math & Code、Formula Recognition 等方向。这说明视觉大模型已经不只是面向日常图片,而是开始进入教育、科研、办公和开发等更复杂的知识工作场景。
2.5.6 UI 交互、函数调用与视觉智能体
更进一步,视觉大模型还可以作为视觉智能体的重要组成部分。所谓视觉智能体,指的是模型不仅要看懂图片或界面,还要根据用户目标判断下一步该做什么。
例如,在 UI 交互场景中,模型可以读取网页或软件界面截图,理解按钮、输入框、菜单和页面布局,然后回答“应该点击哪里”“下一步怎么操作”。在函数调用场景中,模型还可以根据视觉内容决定是否调用外部工具,例如调用 OCR 工具、搜索工具、计算工具或自动化操作接口。
Qwen2-VL 示例中展示的 UI Interaction、Function Calling 和 Agent Potential,说明视觉大模型正在从“视觉问答工具”进一步走向“视觉任务执行助手”。这也是多模态智能体的重要发展方向:模型不仅能看懂当前界面,还能结合用户目标、上下文和工具能力完成更复杂的操作。
2.5.7 小结
从这些场景可以看出,视觉大模型并不是传统视觉模型的简单替代品,而是把视觉理解、语言交互和任务推理结合在一起的一类通用多模态模型。对于后续的模型微调与部署来说,这些场景也会直接影响我们如何准备数据、如何设计提示词、如何选择评测任务,以及如何判断模型是否真正具备可用的视觉理解能力。
3. 环境配置
3.1 云服务器配置
在正式开始 Qwen3-VL 的调用、微调和部署之前,我们需要先准备好实验环境。由于视觉语言模型通常对显存要求较高,直接在普通本地电脑上运行可能会受到显存限制,因此这里我们选择使用云服务器来完成后续实验。比如在 ModelScope 上可以有免费的 GPU 服务进行使用:

但由于该服务有所限制,因此下面我们将使用比较通用的 AutoDL 服务器来进行介绍。
假如想要使用 AutoDL 的服务器,首先我们需要前往 AutoDL 主页(https://www.autodl.com/home)进行注册和登录。如果只是用于实验,可以先充值少量金额进行测试。另外,如果学生使用带有 edu 后缀的邮箱,也可以尝试进行学生认证,认证后通常可以享受一定的折扣优惠:

登录完成后,进入控制台,在左侧菜单中找到 容器实例,然后选择 租用新实例。
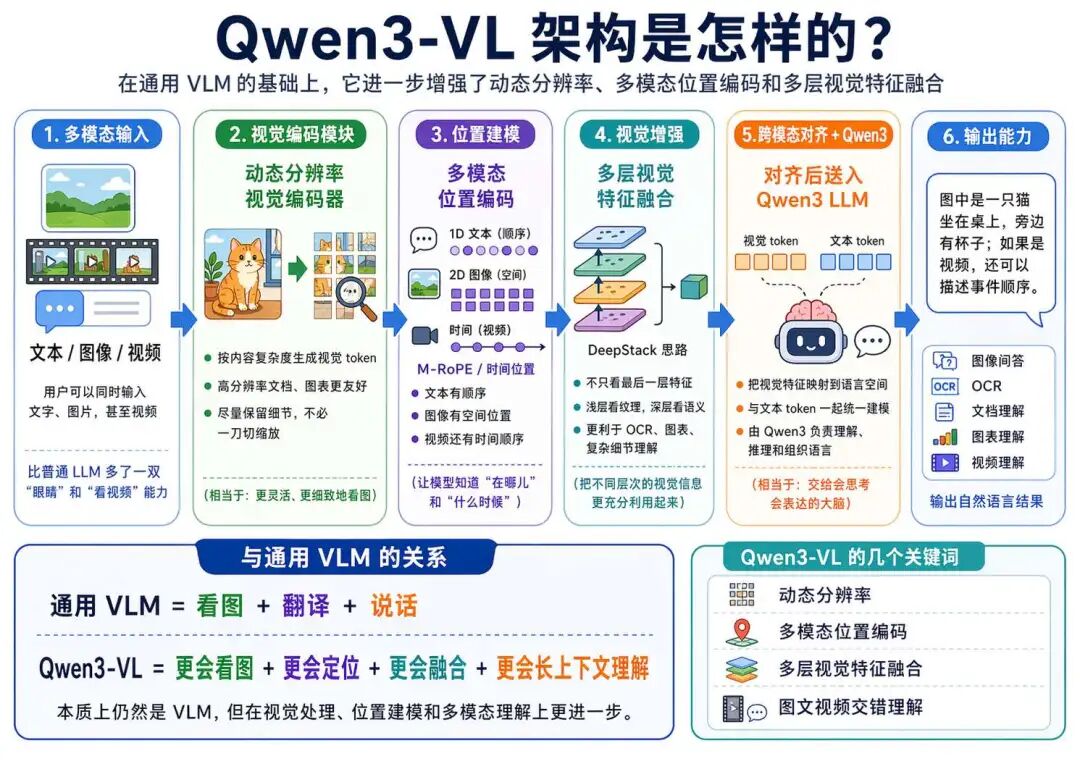
接下来,我们就可以根据实验需求选择合适的显卡实例。AutoDL 支持按量计费,也就是按小时付费,同时也可以选择包日、包周或包月等方式。对于刚开始做实验的同学来说,通常选择按量计费会更加灵活:

在选择 GPU 时,建议优先选择显存在 24GB 以上的显卡。因为 Qwen3-VL 属于视觉语言模型,不仅需要加载语言模型本身,还需要处理图像或视频输入,所以显存压力会比普通文本模型更大一些。
如果希望实验过程更加稳定,可以选择 RTX 4090D 这类显卡。如果当前区域的显卡资源不足,也可以尝试切换到其他地区查看可用实例。例如这里选择的是西北 B 区中价格相对较低的 vGPU-32GB 实例,价格为每小时 1.68 元。
选择好显卡之后,还需要继续配置镜像信息。这里可以选择已经预装好部分深度学习环境的镜像,也可以先不做复杂选择,等进入服务器之后再手动安装所需依赖。确认配置无误后,点击创建并开机即可。
实例创建完成后,我们可以在容器实例列表中看到刚刚租用的服务器。第一次创建完成后,实例通常会自动开机。

接下来有两种常见的使用方式:
第一种方式是直接使用 AutoDL 提供的 JupyterLab 快捷工具,在浏览器中完成代码运行和实验操作。
第二种方式是通过 SSH 远程连接,把云服务器连接到本地 VSCode 中,这样就可以像操作本地项目一样操作云端文件。后续课程中,我们主要推荐使用 VSCode 远程连接的方式,因为它更接近真实开发环境,也更方便进行代码管理和项目调试。
3.2 本地 SSH 连接
如果希望通过本地代码编辑器连接云端服务器,可以使用 VSCode 的 Remote SSH 功能完成远程开发环境配置。
首先打开 VSCode,点击左侧的插件按钮。

然后在插件市场中搜索 ssh,找到并安装 Remote - SSH 插件。

安装完成后,VSCode 左侧会出现远程连接相关的按钮。点击该按钮进入远程资源管理界面。
接着将鼠标移动到 SSH 区域,点击新建远程连接。
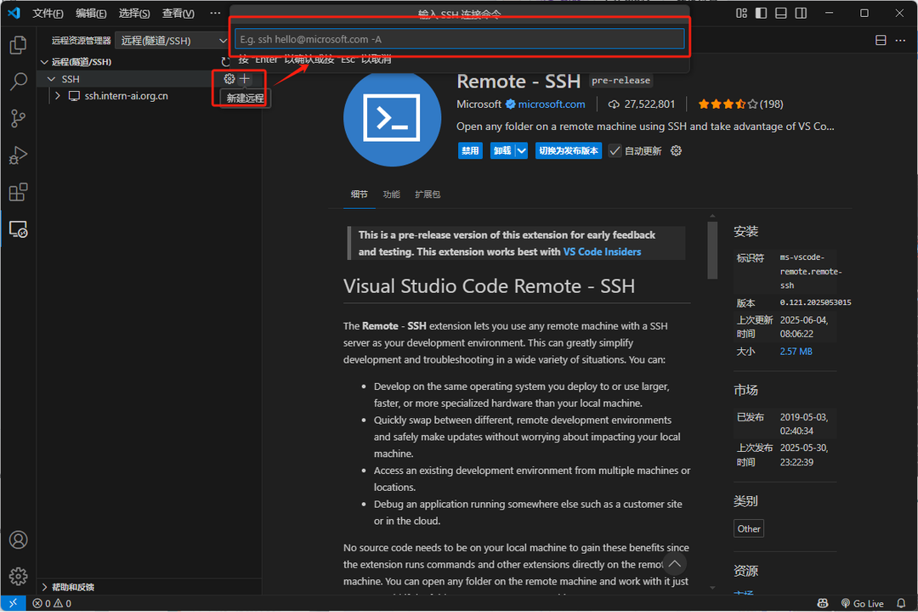
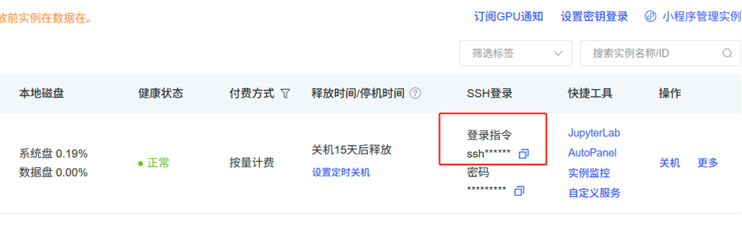
然后回到 AutoDL 控制台,复制实例页面中提供的 SSH 登录指令,并粘贴到 VSCode 弹出的输入框中。
输入完成后按下回车,VSCode 会提示选择 SSH 配置文件保存路径。这里选择其中一个默认路径即可。
配置保存完成后,点击右下角弹出的连接按钮,开始连接远程服务器。
随后 VSCode 会要求选择远程服务器的系统类型,这里选择 Linux,然后继续回车,直到出现输入密码的界面。

回到 AutoDL 页面,复制服务器登录密码,然后粘贴到 VSCode 的密码输入框中。
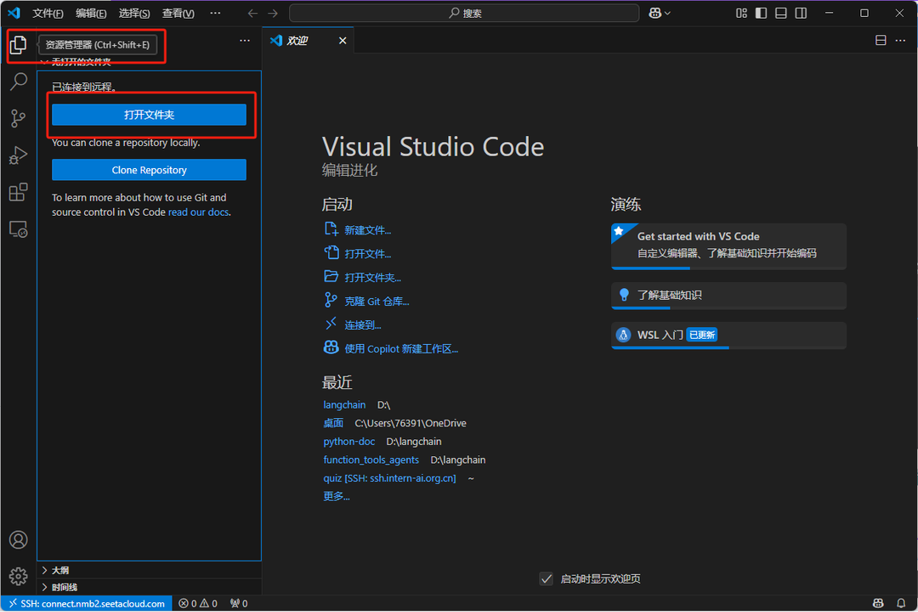
连接成功后,VSCode 左下角会显示当前已经连接到远程服务器的信息。

接下来点击左上角的资源管理器按钮,然后选择 打开文件夹。

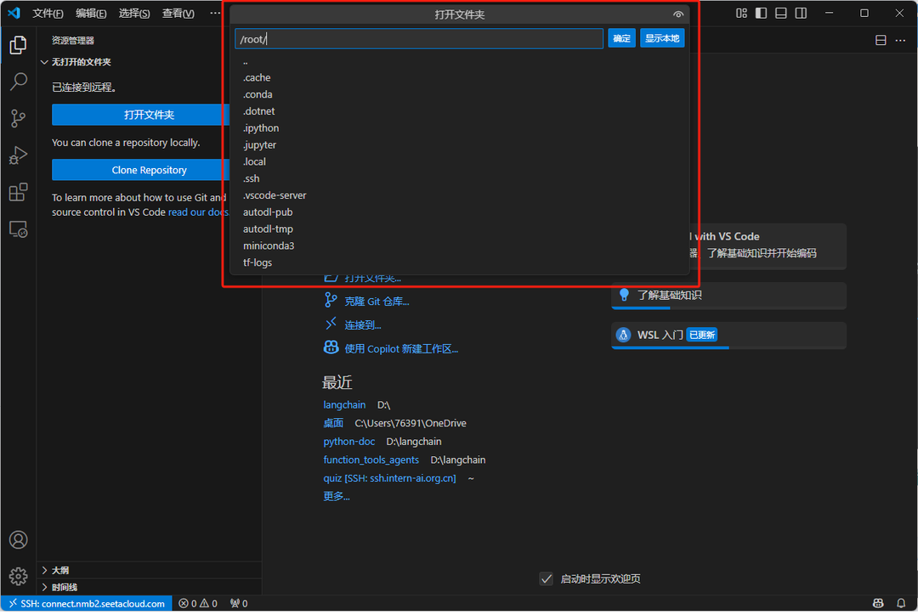
这里可以直接选择默认的 /root/ 路径,并点击确定。
随后系统可能会再次要求输入服务器密码,继续复制 AutoDL 中的密码并粘贴即可。

最后,VSCode 会提示是否信任该远程目录。点击 信任作者 后,就可以正式进入远程开发环境了。

另外我们还需要在该应用商店里安装几个必要的包,包括 python 和 Jupyter,不然后续运行的时候会有影响:

到这里,本地 VSCode 与云端服务器的 SSH 连接就已经配置完成。后续我们就可以直接在 VSCode 中编写代码、打开终端、运行命令,并把所有实验文件保存在云服务器中。
3.3 系统环境配置
进入远程服务器后,我们需要先完成基础 Python 环境配置。打开 VSCode 中的终端,首先输入以下命令:
conda init
执行完成后,点击右上角的 + 号新建一个终端。重新打开终端后,如果命令行前面出现了 (base),就说明 conda 已经成功初始化。
接下来,我们创建一个专门用于本次实验的 conda 环境:
conda create -n ms-swift python=3.12 -y
conda activate ms-swift
这里创建的环境名称为 ms-swift,Python 版本选择的是 3.12。创建独立环境的好处是可以把本次实验所需的依赖包与系统默认环境隔离开,避免不同项目之间出现依赖冲突。
环境激活成功后,就可以继续安装后续实验需要用到的核心依赖:
pip install "transformers>=4.57" "qwen_vl_utils>=0.0.14"
pip install "ms-swift>=4.0"
pip install "vllm>=0.11.0"
pip install "decord" -U
这些依赖中,几个比较关键的包分别是:
transformers:用于加载和调用 Hugging Face 格式的大模型;qwen_vl_utils:用于处理 Qwen-VL 相关的图像、视频等多模态输入;ms-swift:用于后续进行模型微调、推理和部署;vllm:用于高性能推理和 API 服务部署;decord:用于视频读取和视频帧处理。
安装完成后,基础运行环境就配置好了。后续无论是进行模型推理、构造微调数据,还是使用 ms-swift 进行训练和部署,都会基于这个环境来完成。
3.4 模型下载
环境准备完成后,我们还需要下载后续实验中使用的模型。为了让模型微调过程尽可能稳定,同时降低显存压力,这里选择 Qwen3-VL 系列中较小的模型 Qwen3-VL-2B-Instruct 。该模型参数规模相对较小,更适合作为教学实验模型使用。一方面,它能够体现视觉语言模型的基本能力;另一方面,相比更大的模型,它对显存和计算资源的要求也更低,更适合大家跟着课程完成完整流程。
在 AutoDL 中,通常会提供一个专门的数据盘,用来存放模型权重、数据集、训练结果等体积较大的文件。相比系统盘,数据盘更适合保存这类大文件。因此,这里我们将模型下载到 AutoDL 的数据盘目录中。

在终端中输入以下命令即可开始下载模型:
modelscope download --model Qwen/Qwen3-VL-2B-Instruct --local_dir /root/autodl-tmp/qwen3-vl-2b-instruct
其中:
modelscope download表示使用 ModelScope 命令行工具下载模型;-model Qwen/Qwen3-VL-2B-Instruct用于指定要下载的模型名称;-local_dir /root/autodl-tmp/qwen3-vl-2b-instruct用于指定模型保存路径。
下载完成后,模型文件就会被保存到:
/root/autodl-tmp/qwen3-vl-2b-instruct
后续在进行模型推理、微调和部署时,只需要把这个路径作为模型路径传入即可。到这里,本节所需的云服务器、远程连接、系统环境以及模型文件就全部准备完成了。
3.5 实操文件夹创建
模型下载完成后,我们还需要创建一个专门用于本次实验的项目文件夹,用来存放后续的推理脚本、训练数据、微调结果以及部署相关文件。这样可以让整个实验目录更加清晰,后续排查问题时也更方便。
在终端中输入以下命令创建文件夹:
mkdir -p /root/ms-swift
其中,mkdir 表示创建文件夹,-p 表示如果上级目录不存在就自动创建;如果该文件夹已经存在,也不会报错。
创建完成后,继续进入该目录:
cd /root/ms-swift
进入目录后,后续的代码文件、数据处理脚本和训练命令都可以统一放在 /root/ms-swift 下面执行。这样做的好处是实验文件不会散落在不同位置,课程演示和学生复现实验时也会更加方便。
4. VLM 调用实战
前面我们已经完成了云服务器租用、SSH 远程连接、conda 环境创建、依赖安装以及 Qwen3-VL-2B-Instruct 模型下载。接下来就可以正式进入模型调用环节。
这一部分的目标并不是马上开始微调,而是先确认模型能够被正常加载,并且能够正确处理文本、图片和视频输入。因为对于后续微调、部署和评测来说,最基础的前提就是模型本身可以在当前环境中顺利跑起来。
在本节中,我们会分别介绍三种常见调用方式:
第一种是使用 transformers 进行调用。这种方式最接近 Hugging Face 生态的标准用法,适合帮助我们理解视觉语言模型最底层的输入处理流程。
第二种是使用 ms-swift 的 Python 接口进行调用。这种方式更贴近后续微调流程,因为我们后面会继续使用 ms-swift 完成训练、推理和部署。
第三种是使用 swift infer 命令行进行交互式调用。这种方式最简单直观,适合快速验证模型是否可用,也适合课堂演示。
4.1 Transformer 调用
首先我们来看 transformers 调用方式。transformers 是目前大模型加载和推理中非常常见的基础框架,它可以直接读取本地模型目录,然后完成模型加载、输入处理和文本生成。
对于 Qwen3-VL 这类视觉语言模型来说,调用时需要注意一点:输入内容不再只是普通文本,而是由“视觉内容 + 文本指令”共同组成。例如,用户可以给模型一张图片,并同时提出“请描述一下这张图片”的问题。模型需要先理解图像内容,再结合文本问题生成回答。
4.1.1 pipeline 调用
4.1.1.1 图片调用
我们先从最简单的图片理解开始。这里使用一张公开的老虎图片作为输入,让模型完成图片描述任务。
可以在 /root/ms-swift 目录下新建一个 Python 文件(如 infer_image_transformers.py )然后写入以下代码:
import torch
from transformers import pipeline
MODEL_PATH = r"/root/autodl-tmp/qwen3-vl-2b-instruct"
IMAGE_PATH = 'https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/tests/data/tiger.jpeg'
def main():
pipe = pipeline(
task="image-text-to-text",
model=MODEL_PATH,
device_map="auto",
dtype=torch.float16
)
# 统一在 generation_config 里设置生成参数
pipe.model.generation_config.max_new_tokens = 256
pipe.model.generation_config.do_sample = True
messages = [
{
"role": "user",
"content": [
{"type": "image", "image": IMAGE_PATH},
{"type": "text", "text": "请描述一下这张图片。"}
]
}
]
outputs = pipe(
text=messages,
return_full_text=False
)
print(outputs[0]["generated_text"])
if __name__ == "__main__":
main()
这段代码中,最核心的是 messages 部分。它采用的是类似 OpenAI Chat 格式的多模态输入结构:
role表示当前消息来自用户;content是一个列表,里面可以同时放入图片、视频和文本;type="image"表示这里传入的是图片;type="text"表示这里传入的是用户的文字问题。
也就是说,模型实际接收到的不是单独一句话,而是“图片 + 提问”组合后的完整多模态输入。这里用到的图片其实就是一只老虎的图片:
然后我们可以在终端中运行:
python infer_image_transformers.py
如果运行成功,模型会输出类似下面的内容:
好的,这是一张关于一只老虎的图片,以下是详细的描述:
这张图片的主体是一只成年老虎,它正舒适地躺在一片翠绿的草地上。老虎的身体呈侧卧姿态,前爪向前伸展,爪子在草地上留下了一些阴影。它的头部微微抬起,正对着镜头,眼神锐利而专注,仿佛在凝视着什么。
老虎的皮毛呈现出鲜明的橙色,上面覆盖着深色的、粗壮的条纹。这些条纹从头部延伸至身体,环绕着它的身体,形成了独特的图案。它的耳朵竖立着,显得非常警觉。在老虎的周围,阳光洒在草地上,形成了斑驳的光影,为画面增添了层次感和生动感。
整体来看,这张照片捕捉到了老虎在自然环境中的一个宁静而威严的瞬间。
只要模型能够根据图片内容生成合理描述,就说明当前环境已经可以完成基本的图片理解任务。
4.1.1.2 视频调用
除了图片之外,Qwen3-VL 也支持视频输入。视频理解本质上可以理解为模型会从视频中抽取若干帧,然后把这些帧转换成视觉 token,再与文本问题一起输入到语言模型中进行推理。
由于视频通常比图片占用更多显存,因此在实验中建议控制视频帧数和视频 token 数量。否则即使模型参数不大,也可能因为视频输入过长而导致显存不足。
我们可以将视频路径进行写入:
import torch
from transformers import pipeline
MODEL_PATH = r"/root/autodl-tmp/qwen3-vl-2b-instruct"
VIDEO_PATH = '/root/VLM/baby.mp4'
def main():
pipe = pipeline(
task="image-text-to-text",
model=MODEL_PATH,
device_map="auto",
dtype=torch.float16
)
# 统一在 generation_config 里设置生成参数
pipe.model.generation_config.max_new_tokens = 256
pipe.model.generation_config.do_sample = True
messages = [
{
"role": "user",
"content": [
{"type": "video", "video": VIDEO_PATH},
{"type": "text", "text": "请描述一下这个视频。"}
]
}
]
outputs = pipe(
text=messages,
return_full_text=False
)
print(outputs[0]["generated_text"])
if __name__ == "__main__":
main()
然后同样运行该文件,如果模型能够输出视频中的人物、动作和场景描述,就说明视频输入也可以正常处理:
视频中,一个戴着黑色眼镜的小宝宝坐在床上,正在专注地阅读一本打开的书。宝宝穿着浅蓝色的短袖上衣和粉色的裤子,头发是金色的,看起来非常可爱。他/她用双手翻动书页,似乎在认真地寻找某些信息或图案。背景中,可以看到床头柜上放着一些衣物和一个电视,电视屏幕亮着,但没有显示任何内容。房间内还有其他家具,如一个木制的床头柜和一个床头柜上的装饰品。整个场景显得温馨而宁静,充满了童趣和温馨。
需要注意的是,视频调用比图片调用更容易受到环境和依赖影响。如果运行时提示缺少视频处理相关依赖,可以检查前面是否已经安装:
pip install "decord" -U
4.1.2 使用 AutoProcessor 和模型类调用
4.1.2.1 图片调用
除了使用 pipeline 这种高级封装方式之外,我们也可以使用 AutoProcessor 和模型类进行更底层的调用。这种方式代码稍微复杂一些,但更适合理解 VLM 的输入处理流程。
我们可以在文件中写入以下代码:
import torch
from transformers import AutoProcessor, AutoModelForImageTextToText
def main():
model_path = r"D:\微调与部署\qwen-VL"
image_path = r"D:\微调与部署\VLM\test_image.jpeg"
processor = AutoProcessor.from_pretrained(model_path)
model = AutoModelForImageTextToText.from_pretrained(
model_path,
dtype=torch.float16,
device_map="auto"
)
messages = [
{
"role": "user",
"content": [
{"type": "image", "image": image_path},
{"type": "text", "text": "请详细描述这张图片。"}
]
}
]
inputs = processor.apply_chat_template(
messages,
add_generation_prompt=True,
tokenize=True,
return_dict=True,
return_tensors="pt"
)
inputs = {k: v.to(model.device) for k, v in inputs.items()}
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=256,
do_sample=False
)
input_len = inputs["input_ids"].shape[1]
new_tokens = outputs[0][input_len:]
text = processor.decode(new_tokens, skip_special_tokens=True)
print(text)
if __name__ == "__main__":
main()
这里相比 pipeline 方式多了几个步骤:
第一,使用 AutoProcessor 对多模态输入进行处理。对于 VLM 来说,processor 不仅要处理文本,还要处理图片或视频,并把它们整理成模型可以理解的张量格式。
第二,使用 apply_chat_template 把多模态消息转换成模型需要的对话模板。简单理解,就是把用户输入整理成 Qwen3-VL 训练时熟悉的格式。
第三,调用 model.generate() 生成结果。这里生成出来的 outputs 同时包含输入部分和新生成部分,所以后面需要通过 input_len 把原始输入切掉,只保留模型新生成的回答。
假如输出以下结果就代表模型已经跑通:
Loading weights: 100%|██████████| 625/625 [00:02<00:00, 230.72it/s]
这是一张在明亮日光下拍摄的老虎特写照片。画面主体是一只成年老虎,它正舒适地趴在一片翠绿的草地上。老虎的身体呈侧卧姿态,前爪向前伸展,头部微微抬起,目光直视着镜头,显得既威严又警觉。它的皮毛呈现出鲜明的橙黄色,上面覆盖着深邃的黑色条纹,条纹的边缘清晰,与橙色的底色形成强烈对比。老虎的面部特征非常清晰,浓密的胡须和锐利的眼神都清晰可见。阳光从上方照射下来,在老虎的毛发和草地上形成了明暗交错的光影效果,增强了画面的立体感和质感。背景是模糊的绿色草地,这种浅景深的处理方式使得老虎主体更加突出。整张照片构图居中,色彩饱和,充满了力量感和自然的野性美。
这种方式虽然比 pipeline 更复杂,但它更加透明。后续如果我们希望控制输入张量、调整生成参数、观察 token 长度,或者进一步接入自定义推理流程,这种写法会更加灵活。
4.1.2.2 视频调用
同样的,我们也可以通过该方式传入视频内容,不过在实际使用 Qwen-VL 系列模型时,官方通常会配合 qwen_vl_utils 来处理图片和视频输入。这个工具包可以帮助我们完成视觉内容解析,例如读取图片、抽取视频帧、组织视频元信息等。
相比直接使用 pipeline,这种写法更加接近模型底层调用流程,也更方便控制视频输入规模。具体代码如下所示:
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
from qwen_vl_utils import process_vision_info
from transformers import Qwen3VLForConditionalGeneration, AutoProcessor
model_dir = "/root/autodl-tmp/qwen3-vl-2b-instruct"
model = Qwen3VLForConditionalGeneration.from_pretrained(
model_dir, dtype="auto", device_map="auto",
# attn_implementation='flash_attention_2',
)
processor = AutoProcessor.from_pretrained(model_dir)
messages = [
{
"role": "user",
"content": [
{
"type": "video",
"video": "https://modelscope-open.oss-cn-hangzhou.aliyuncs.com/images/baby.mp4",
"max_pixels": 128*32*32,
"max_frames": 16,
},
{"type": "text", "text": "描述一下这个视频。"},
],
}
]
text = processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
image_inputs, video_inputs, video_kwargs = process_vision_info([messages], return_video_kwargs=True,
image_patch_size= 16,
return_video_metadata=True)
if video_inputs is not None:
video_inputs, video_metadatas = zip(*video_inputs)
video_inputs, video_metadatas = list(video_inputs), list(video_metadatas)
else:
video_metadatas = None
inputs = processor(text=[text], images=image_inputs, videos=video_inputs, video_metadata=video_metadatas, **video_kwargs, do_resize=False, return_tensors="pt")
inputs = inputs.to('cuda')
generated_ids = model.generate(**inputs, max_new_tokens=128, do_sample=False)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_text[0])
这段代码中有两个参数尤其值得关注:
max_frames=16:表示最多从视频中抽取 16 帧;max_pixels=128 * 32 * 32:用于限制视觉输入规模,避免视频输入过大。
对于测试实验来说,建议一开始先使用较小的视频帧数,例如 8 或 16。这样可以降低显存压力,也更容易保证代码稳定运行。如果显存比较充足,再逐步提高帧数或输入分辨率,观察模型对视频内容理解是否更加细致。
返回的结果如下所示:
视频展示了一个小女孩坐在床上,她戴着一副黑色的太阳镜,穿着浅蓝色的上衣和粉色的裤子。她正专注地阅读一本打开的书,书页上印有文字。她用双手翻动书页,动作轻柔而专注。背景中可以看到一个木质的床头柜,上面放着一些物品,包括一个蓝色的布料和一个白色的布料。床头柜旁边还有一个小桌子,上面放着一个蓝色的布料和一个白色的布料。房间的墙壁是白色的,墙上挂着一个蓝色的布料和一个白色的布料。房间的
由于这里设置了 max_new_token 参数,因此这里被截断了,不过这也表示我们正确的调用了该模型,说明整体运行环境无误。
4.2 ms-swift 调用
前面我们已经使用原生 transformers 跑通了 Qwen3-VL 的基础推理流程。接下来,我们进一步引入 ms-swift 的推理接口。
之所以要单独介绍 ms-swift,是因为它并不只是一个简单的模型调用工具,而是一套围绕大模型训练、微调、推理、部署和评测构建的完整工具链。对于后续课程来说,我们不仅需要让模型“能跑起来”,还需要继续完成数据集构建、LoRA/QLoRA 微调、推理加速、API 服务化以及模型发布等流程。因此,从这一节开始切换到 ms-swift,也更符合后续实战的整体路线。
简单来说,transformers 更适合用于理解模型最基础的加载和推理流程,而 ms-swift 更适合承接完整的工程化训练与部署流程。
4.2.1 TransformersEngine 调用
在 ms-swift 中,最基础、最直观的推理方式是使用 TransformersEngine。它本质上仍然基于 Transformers 后端完成模型加载与推理,因此兼容性较好。
下面我们通过前面的视频理解任务来演示 TransformersEngine 的基本用法:
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
os.environ['VIDEO_MAX_TOKEN_NUM'] = '128'
os.environ['FPS_MAX_FRAMES'] = '16'
from swift.infer_engine import TransformersEngine, InferRequest, RequestConfig
engine = TransformersEngine("/root/autodl-tmp/qwen3-vl-2b-instruct")
infer_request = InferRequest(
messages=[{
"role": "user",
"content": "<video>描述一下这个视频。",
}],
videos=['https://modelscope-open.oss-cn-hangzhou.aliyuncs.com/images/baby.mp4']
)
# 非流式
request_config = RequestConfig(max_tokens=128, temperature=0)
resp_list = engine.infer([infer_request], request_config=request_config)
print(resp_list[0].choices[0].message.content)
这段代码的整体流程可以分成三步理解。
第一步,通过环境变量指定显卡和视频输入的处理限制:
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
os.environ["VIDEO_MAX_TOKEN_NUM"] = "128"
os.environ["FPS_MAX_FRAMES"] = "16"
其中,CUDA_VISIBLE_DEVICES="0" 表示当前程序只使用第 0 张 GPU;VIDEO_MAX_TOKEN_NUM 用于限制视频被编码后占用的视觉 token 数量;FPS_MAX_FRAMES 用于限制视频最多抽取多少帧。
对于视频模型来说,这两个参数非常重要。因为视频不是一张静态图片,而是由多帧画面组成。如果抽取的帧数过多,或者每一帧分辨率过高,都会显著增加显存占用。因此,在课堂演示或单卡环境中,通常建议先使用较小的设置跑通流程,再根据显存情况逐步调整。
第二步,创建 TransformersEngine:
engine = TransformersEngine("/root/autodl-tmp/qwen3-vl-2b-instruct")
这里传入的是本地模型路径。模型会从该目录中加载权重、配置文件、tokenizer 以及视觉处理相关组件。
第三步,构造推理请求:
infer_request = InferRequest(
messages=[{
"role": "user",
"content": "<video>描述一下这个视频。",
}],
videos=[
"https://modelscope-open.oss-cn-hangzhou.aliyuncs.com/images/baby.mp4"
]
)
这里需要注意,ms-swift 的多模态输入方式和原生 transformers 略有不同。
在 messages 中,我们使用 <video> 作为视频占位符。它的作用是告诉模型:当前位置需要接入一段视频内容。而真正的视频路径或视频 URL,则通过 videos 参数传入。
也就是说 <video> 负责在文本提示词中标记视频位置,而 videos 负责提供真实的视频文件或视频链接。如果后续要处理图片,写法也是类似的,只需要将 <video> 和 videos 替换为图片对应的形式即可。
接下来通过 RequestConfig 控制生成参数:
request_config = RequestConfig(
max_tokens=128,
temperature=0
)
其中,max_tokens=128 表示模型最多生成 128 个 token;temperature=0 表示使用更稳定、更确定的输出方式。对于课堂演示、实验复现和结果对比来说,temperature=0 通常更合适,因为它可以减少随机性,让多次运行的结果更加稳定。
如果代码运行成功,终端中会先输出模型加载、视频处理和模板构建相关日志,随后输出模型对视频的描述结果。例如:
[INFO:swift] Setting torch_dtype: torch.bfloat16
[INFO:swift] Setting max_ratio: 200. You can adjust this hyperparameter through the environment variable: `MAX_RATIO`.
[INFO:swift] Setting frame_factor: 2. You can adjust this hyperparameter through the environment variable: `FRAME_FACTOR`.
[INFO:swift] Setting fps: 2.0. You can adjust this hyperparameter through the environment variable: `FPS`.
[INFO:swift] Setting fps_min_frames: 4. You can adjust this hyperparameter through the environment variable: `FPS_MIN_FRAMES`.
[INFO:swift] Using environment variable `FPS_MAX_FRAMES`, Setting fps_max_frames: 16.
[INFO:swift] Setting image_max_token_num: 16384. You can adjust this hyperparameter through the environment variable: `IMAGE_MAX_TOKEN_NUM`.
[INFO:swift] Setting image_min_token_num: 4. You can adjust this hyperparameter through the environment variable: `IMAGE_MIN_TOKEN_NUM`.
[INFO:swift] Setting spatial_merge_size: 2. You can adjust this hyperparameter through the environment variable: `SPATIAL_MERGE_SIZE`.
[INFO:swift] Using environment variable `VIDEO_MAX_TOKEN_NUM`, Setting video_max_token_num: 128.
[INFO:swift] Setting video_min_token_num: 128. You can adjust this hyperparameter through the environment variable: `VIDEO_MIN_TOKEN_NUM`.
[INFO:swift] model_kwargs: {'device_map': 'cuda:0', 'dtype': torch.bfloat16}
Loading weights: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████| 625/625 [00:00<00:00, 725.51it/s]
[INFO:swift] Create the template for the infer_engine
[INFO:swift] default_system: None
[INFO:swift] max_length: 262144
[INFO:swift] response_prefix: ''
[INFO:swift] agent_template: hermes
[INFO:swift] norm_bbox: norm1000
[INFO:swift] Setting ROOT_IMAGE_DIR: None. You can adjust this hyperparameter through the environment variable: `ROOT_IMAGE_DIR`.
[INFO:swift] Setting QWENVL_BBOX_FORMAT: legacy. You can adjust this hyperparameter through the environment variable: `QWENVL_BBOX_FORMAT`.
qwen-vl-utils using decord to read video.
[INFO:swift] Successfully registered `/root/miniconda3/envs/ms-swift/lib/python3.12/site-packages/swift/dataset/data/dataset_info.json`.
视频展示了一个小女孩坐在床上,她戴着一副黑色的太阳镜,穿着浅蓝色的上衣和粉色的裤子。她正专注地阅读一本打开的书,书页上印有文字。她用双手翻动书页,动作轻柔而专注。背景中可以看到一个木质的床头柜,上面放着一些物品,包括一个蓝色的布料和一个白色的布料。床头柜旁边还有一个小桌子,上面放着一个蓝色的布料和一个白色的布料。房间的墙壁是白色的,墙上挂着一个蓝色的布料和一个白色的布料。房间的
从这个结果可以看出,模型已经能够完成基本的视频理解任务。到这里为止,我们已经通过 ms-swift 的 TransformersEngine 成功跑通了 Qwen3-VL 的视频推理流程。
4.2.2 VllmEngine 调用
除了 TransformersEngine 之外,ms-swift 还支持接入其他推理后端,例如 vLLM、LMDeploy 和 SGLang 等。这些后端更偏向推理加速和服务化部署,适合在模型已经能够正常运行之后,用来提升吞吐、降低延迟,并支持后续的 API 服务调用。
在上一节本地 Windows 环境中,我们没有重点演示 vLLM 和 SGLang,主要是因为这类推理加速框架通常对 Linux 环境支持更好。而本节课程使用的是云服务器环境,因此可以进一步演示如何通过 VllmEngine 调用 Qwen3-VL。
假如要使用 vllm 的话需要从 swift 里获取 VllmEngine 来使用:
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
os.environ["VIDEO_MAX_TOKEN_NUM"] = "128"
os.environ["FPS_MAX_FRAMES"] = "16"
def main():
from swift.infer_engine import VllmEngine, InferRequest, RequestConfig
model_path = "/root/autodl-tmp/qwen3-vl-2b-instruct"
engine = VllmEngine(
model_path,
max_model_len=8192,
limit_mm_per_prompt={
"video": 1,
"image": 0,
},
max_num_seqs=1,
gpu_memory_utilization=0.6,
)
infer_request = InferRequest(
messages=[{
"role": "user",
"content": "<video>描述一下这个视频。",
}],
videos=[
"https://modelscope-open.oss-cn-hangzhou.aliyuncs.com/images/baby.mp4"
]
)
request_config = RequestConfig(
max_tokens=128,
temperature=0
)
resp_list = engine.infer(
[infer_request],
request_config=request_config
)
print(resp_list[0].choices[0].message.content)
if __name__ == "__main__":
main()
创建 VllmEngine 时额外设置了一些和推理性能、显存控制相关的参数:
engine = VllmEngine(
model_path,
max_model_len=8192,
limit_mm_per_prompt={
"video": 1,
"image": 0,
},
max_num_seqs=1,
gpu_memory_utilization=0.6,
)
其中,max_model_len=8192 表示当前推理时允许的最大上下文长度。对于视觉语言模型来说,视频帧、图片内容和文本提示词都会占用上下文长度,因此这个值不能设置得过小;但如果设置得过大,也会增加显存压力。
limit_mm_per_prompt 用于限制每个请求中允许包含的多模态输入数量。这里设置为:
limit_mm_per_prompt={
"video": 1,
"image": 0,
}
表示当前每个请求最多包含 1 个视频,不包含图片。这样设置可以让 vLLM 更明确地知道本次推理任务的多模态输入规模,也有助于控制资源占用。
max_num_seqs=1 表示同时处理的请求序列数量。当前我们只是做单条视频推理演示,因此设置为 1 即可。如果后续要做批量推理或并发服务,可以再根据显存和吞吐需求进行调整。
gpu_memory_utilization=0.6 表示允许 vLLM 使用大约 60% 的 GPU 显存。这个参数可以根据实际显存情况调整。如果显存比较充足,可以适当调高;如果启动时出现显存不足,则可以适当降低。
最后需要特别注意的是,使用 VllmEngine 时,建议把模型加载和推理逻辑放到 main() 函数中,并通过下面这种方式启动:
if __name__ == "__main__":
main()
这是因为 vLLM 底层会启动额外的推理进程。如果直接把 VllmEngine 写在脚本最外层,可能会导致 Python 多进程在启动子进程时重复导入当前脚本,从而出现启动失败的问题。因此,在使用 vLLM 后端时,采用这种标准写法会更加稳妥。
代码运行成功后,可以得到类似下面的输出:
视频展示了一个婴儿坐在床上,戴着一副黑色的太阳镜,专注地阅读一本书。婴儿穿着浅蓝色的上衣和粉色的裤子,坐在一张铺有花纹床单的床上。床头有一个深色的木制婴儿床,床边放着一件白色的衣物。背景中可以看到一个条纹的床单和一个带有条纹的枕头。婴儿的双手在书页上翻动,似乎在认真地阅读。整个场景显得温馨而宁静,婴儿的专注和认真阅读的神情让人感到温暖。
需要说明的是,VllmEngine 在第一次启动时可能会花费更长时间,因为它需要初始化 vLLM 推理后端、分配显存、构建执行环境。这个启动过程通常比普通 Transformers 推理更复杂。但是一旦启动完成,在多请求、批量推理或服务化场景中,vLLM 的优势会更加明显。
4.4 命令行调用
除了 Python 脚本之外,ms-swift 还提供了更加直接的命令行调用方式,也就是 swift infer。
这种方式特别适合刚开始验证模型时使用,因为不需要自己写完整的 Python 推理脚本,只需要在终端中执行一条命令,就可以进入交互式对话界面。
4.4.1 使用 transformers 后端进行命令行调用
CUDA_VISIBLE_DEVICES=0 \
IMAGE_MAX_TOKEN_NUM=1024 \
swift infer \
--model /root/autodl-tmp/qwen3-vl-2b-instruct \
--stream true \
--infer_backend transformers \
--max_new_tokens 512
这条命令中:
CUDA_VISIBLE_DEVICES=0表示使用第 0 张 GPU;IMAGE_MAX_TOKEN_NUM=1024表示限制图片输入转换后的最大 token 数;swift infer表示启动 ms-swift 的推理命令;-model用于指定本地模型路径;-stream true表示开启流式输出;-infer_backend transformers表示使用 transformers 后端进行推理;-max_new_tokens 512表示最多生成 512 个新 token。
启动后,就可以在命令行中直接输入问题。例如,可以先测试纯文本对话:
<<< 你好,你是谁?
你好!我是Qwen,是阿里云研发的超大规模语言模型。我是一个多模态大模型,可以回答问题、创作文本、进行逻辑推理、编程、写作、翻译等任务。我可以帮助你解决各种问题,无论是学习、工作还是生活中的需求。有什么我可以帮你的吗?
此时模型是能够正常与我们进行一问一答对话的。除此之外,我们还可以尝试加入图片内容进行对话,此时会要求我们传入图片路径或者地址:
<<< <image>请详细描述这张图片里的主要内容
Input an image path or URL <<< https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/tests/data/tiger.jpeg
好的,这张图片的主要内容是一只老虎正躺在草地上。
- **主体**:图片的中心是一只成年老虎,它正以一种放松的姿态趴卧在草地上。
- **姿态**:老虎的身体舒展,前爪向前伸展,头部微微抬起,目光直视着镜头,显得非常警觉和专注。
- **毛色与花纹**:它的毛皮是橙黄色的底色,上面覆盖着深黑色的条纹,条纹从头部延伸至身体,形成了鲜明的对比。脸部和颈部的毛发颜色较浅,显得很蓬松。
- **环境**:老虎所处的环境是绿色的草地,阳光照射在草地上,形成了一些斑驳的光影,增加了画面的层次感。
- **整体氛围**:整张照片给人一种宁静、威严的感觉,老虎看起来既威武又安详。
同样的也可以通过 <video> 传入视频:
<<< <video>请描述一下这个视频呢。
Input a video path or URL <<< /root/VLM/baby.mp4
好的,这是一段关于一个孩子在阅读的视频的详细描述。
视频中,一个年幼的女童正坐在一张铺着花纹床单的床上,专注地阅读着一本打开的书。她戴着一副黑色的儿童眼镜,穿着一件浅蓝色的短袖上衣和粉色的裤子。她的头发是浅色的,看起来很短。
女孩的动作非常专注,她用双手翻动着书页,手指在书页上滑动,似乎在寻找特定的字词。她的眼睛紧紧盯着书本,全神贯注。她的表情非常认真,似乎完全沉浸在书中的世界里。
在她身后,可以看到一个深色的木制婴儿床,床单是花纹的。床的旁边还放着一些衣物,包括一件白色的衬衫和一件蓝白条纹的衬衫。整个画面给人一种温馨、宁静的感觉,展现了孩子在家中安静阅读的场景。
当然多个视频或者图片的话也是需要逐个传入的。
4.4.2 使用 vLLM 后端进行命令行调用
如果希望进一步提高推理性能,也可以尝试使用 vLLM 后端。vLLM 更适合高并发推理和服务化部署场景,在后续部署章节中会继续使用。
可以输入以下命令:
CUDA_VISIBLE_DEVICES=0 \
IMAGE_MAX_TOKEN_NUM=1024 \
VIDEO_MAX_TOKEN_NUM=128 \
FPS_MAX_FRAMES=16 \
swift infer \
--model /root/autodl-tmp/qwen3-vl-2b-instruct \
--stream true \
--infer_backend vllm \
--max_new_tokens 512 \
--vllm_gpu_memory_utilization 0.5 \
--vllm_max_model_len 8192
这样我们就可以像上面一样使用 vllm 进行推理对话了。
阶段小结
到这里,我们已经完成了视觉大模型实战的前半部分:先从 VLM 的基本概念出发,理解它和传统视觉模型、普通文本大模型之间的区别;再以 Qwen3-VL 为例,梳理模型能力演进、环境配置、ModelScope 下载、图片/视频推理以及 ms-swift 命令行调用方式。
也就是说,前四章解决的是“视觉大模型是什么,以及如何把模型稳定跑起来”的问题。下一篇会继续进入更偏工程落地的部分:数据集准备、LoRA 微调、adapter 推理、模型合并、FP8 量化、API 部署、效果测评与 ModelScope 上传,把整个视觉大模型调优与部署链路真正跑完整。
-- 完 --
关注机智流并加入 AI 技术交流群,不仅能和来自大厂名校的 AI 开发者、爱好者一起进行技术交流,同时还有与、、、、等。
cc | 大模型技术交流群 hf | HuggingFace 高赞论文分享群 lc|LangChain 技术交流群 code | AI Coding 交流群 具身 | 具身智能交流群 硬件 | AI 硬件交流群 推理 | AI 推理框架交流群 智能体 | Agent 技术交流群