
近日,来自英国南安普顿大学(University of Southampton)和广州大学的研究者团队提出 SlaClip,一种用于差分隐私随机梯度下降(DP-SGD)[1] 的自适应梯度剪裁方法。该工作 “SlaClip: Gradient Norm Slacks can be Indicator for Adaptive Clipping in DP-SGD” 被 ICML 2026 接收为 Spotlight。

论文标题:SlaClip: Gradient Norm Slacks can be Indicator for Adaptive Clipping in DP-SGD
代码链接:https://github.com/ZsyRock/SlaClip
关键词:Differential Privacy, DP-SGD, Gradient Clipping, Adaptive Clipping
为了介绍 SlaClip,我们先讲解传统的 DP-SGD 以及现有的经典自适应剪裁阈值的方法。
传统 DP-SGD 与自适应剪裁阈值方法
DP-SGD 是深度学习中实现差分隐私训练的经典方法。它通过 “逐样本梯度剪裁 + 高斯噪声” 的方式限制单个样本对模型更新的影响。DP-SGD 的基本流程可以概括为三步,如下所示:

(I) 剪裁:在每个训练迭代中,DP-SGD 会对当前小批量中的每个样本梯度做 ℓ₂ 范数剪裁,使其范数不超过预设阈值 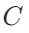 ;
;
(II) 聚合:DP-SGD 对剪裁后的梯度进行聚合平均;
(III) 加噪:在聚合梯度上加入经过校准的高斯噪声,并使用这个带噪梯度更新模型参数。
这一流程可以提供形式化的差分隐私保证,但也带来一个实际困难:剪裁阈值  很难选择。如果
很难选择。如果  太小,许多原本有用的梯度方向会被过度剪裁,导致模型更新偏离真实梯度方向;如果
太小,许多原本有用的梯度方向会被过度剪裁,导致模型更新偏离真实梯度方向;如果  太大,单个样本梯度的敏感度上界也会变大,最终可能使有效梯度信号被更大的噪声淹没。
太大,单个样本梯度的敏感度上界也会变大,最终可能使有效梯度信号被更大的噪声淹没。
为了解决固定剪裁阈值的局限,已有研究 Adap-Clip [2] 提出了一个自适应剪裁阈值的方法,其思路是追踪当前批量中未发生剪裁的梯度占比,并将剪裁阈值调向一个固定目标比例,例如 50%,这类自适应裁剪思想也已经进入主流差分隐私训练工具链,例如 Meta 的 PyTorch Opacus 和 Google 生态中的 TensorFlow Privacy。
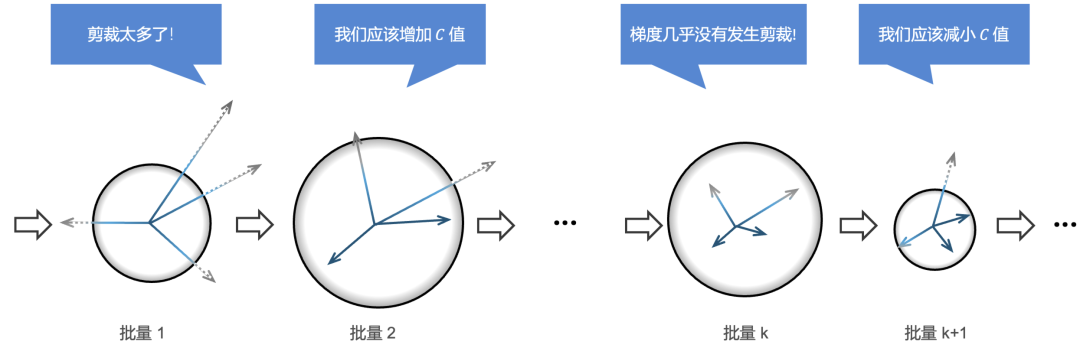
这一思路直观有效,但在差分隐私训练中会带来两个问题:
第一,估计当前批量中未剪裁比例通常需要额外的隐私评估。这将消耗更多隐私预算或者加入更强的噪声。
第二,固定的目标未剪裁比例并不一定总是合适。由于梯度范数分布会发生变化,在训练后期出现的大量小范数梯度对聚合更新的贡献可能很小,甚至容易被 DP 噪声淹没。机械地维持固定未剪裁比例,剪裁阈值可能会持续下降。
这引出了 SlaClip 试图回答的问题:能否在不引入额外隐私查询的情况下,获得类似梯度范数分布信息,用于自适应调节剪裁阈值?
SlaClip 的核心观察:剪裁的 “slack” 不是无用信息
SlaClip 从一个简单但容易被忽视的观察出发:梯度剪裁过程中产生的梯度范数 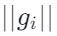 与剪裁阈值
与剪裁阈值 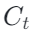 之间的差值
之间的差值  天然包含了梯度范数的部分信息,称之为剪裁的 “slack”。直观地说,slack 描述了一个梯度距离当前剪裁阈值还有多远。
天然包含了梯度范数的部分信息,称之为剪裁的 “slack”。直观地说,slack 描述了一个梯度距离当前剪裁阈值还有多远。
SlaClip 通过在每个样本梯度  后面附加一个维度为 K 的向量
后面附加一个维度为 K 的向量 ,并且将 slack 编码进
,并且将 slack 编码进 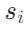 中,使扩展后的梯度
中,使扩展后的梯度 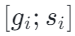 仍然满足与原始 DP-SGD 相同的 ℓ₂ 范数约束,得以在继续保持与传统 DP-SGD 相同敏感度约束的前提下,获得一个用于调节剪裁阈值
仍然满足与原始 DP-SGD 相同的 ℓ₂ 范数约束,得以在继续保持与传统 DP-SGD 相同敏感度约束的前提下,获得一个用于调节剪裁阈值  的指示器(Slack Indicator)。与传统 DP-SGD 相同,SlaClip 也保证每个样本梯度经过剪裁后依然被限制在范数不超过
的指示器(Slack Indicator)。与传统 DP-SGD 相同,SlaClip 也保证每个样本梯度经过剪裁后依然被限制在范数不超过  的球内,因此从差分隐私机制的角度看,聚合查询的全局 ℓ₂ 敏感度仍然与传统 DP-SGD 保持一致,编码 slack 以及敏感度不变的证明如下所示:
的球内,因此从差分隐私机制的角度看,聚合查询的全局 ℓ₂ 敏感度仍然与传统 DP-SGD 保持一致,编码 slack 以及敏感度不变的证明如下所示:


在这种设计下,SlaClip 不需要额外的隐私消耗,就能获得关于梯度范数分布的有用反馈信号。
Slack Indicator 得到的到底是什么信息?
经过聚合、高斯噪声和归一化后,SlaClip 得到的 Slack Indicator 可以被理解为一个带噪声的、分箱的累积分布函数(cumulative distribution function, CDF)估计,如下所示。

换句话说,Slack Indicator 不只是告诉我们 “有多少梯度被剪裁”,而是提供了更细粒度的分布信息:哪些梯度接近当前阈值,哪些梯度集中在较小范数区域。
其中,靠近阈值的坐标可以提供类似未剪裁比例的反馈,功能上接近 Adap-Clip 所使用的剪裁 / 未剪裁统计。SlaClip 还额外利用 CDF 中靠近零的坐标来估计小梯度比例,来动态调节目标未剪裁比例,使剪裁阈值更新更符合当前训练阶段的梯度分布。这个过程在整个训练过程中持续,如下图所示,从而可以实时地动态调节剪裁比例。
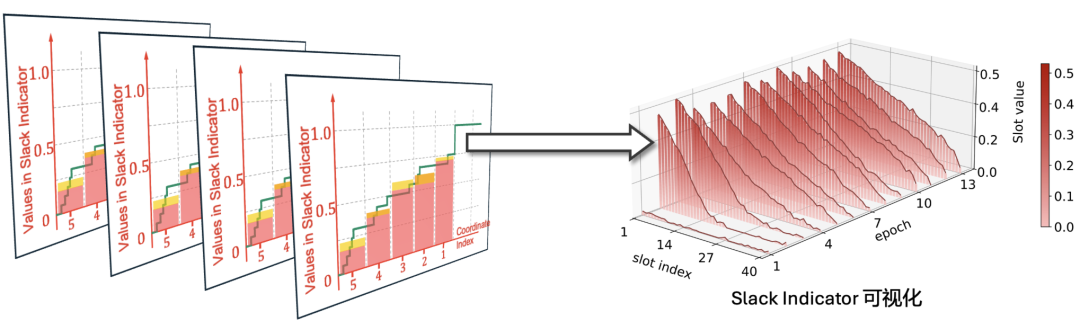
因此,SlaClip 同时克服了上文提到的现有 adaptive clipping 方法中的两个问题:(I) SlaClip 无需额外的隐私评估,获得更丰富的 CDF 信息; (II) SlaClip 动态调节了未剪裁比例,避免了训练后期的剪裁阈值不断下降的问题。
实验设计:相同参数池下的公平比较
为了比较不同剪裁方法,论文采用了匹配相同隐私预算下的公平调参协议对比实验,对每个方法、数据集和隐私预算都在相同的超参数池中进行网格搜索(grid search)。实验结果表明,SlaClip 在多个数据集和隐私预算设置下取得了有竞争力的结果,经常达到最佳或第二好的差分隐私训练准确率。

除了最终精度对比,论文还通过网格搜索热图分析了不同方法对学习率和初始剪裁阈值 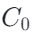 的敏感性。
的敏感性。

在 F-MNIST 上,热图展示了不同基线方法在不同学习率和不同  组合下的最优准确率。结果显示,SlaClip 在常见学习率区间附近形成了更宽的高精度区域,并且对多个
组合下的最优准确率。结果显示,SlaClip 在常见学习率区间附近形成了更宽的高精度区域,并且对多个 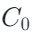 取值保持相对稳定。
取值保持相对稳定。
相比之下,一些传统自适应剪裁阈值方法的高精度区域更加集中,对学习率和初始阈值的组合更敏感。这说明 SlaClip 的 Slack Indicator 能够在一定程度上缓解初始剪裁阈值选择带来的不稳定性。
总结
总体而言,SlaClip 的特点可以概括为三点:
第一,SlaClip 不引入额外隐私查询;
第二,SlaClip 是 “即插即用” 的方法,并且额外计算开销较低;
第三,SlaClip 提供了比单一剪裁 / 未剪裁统计更丰富的信息。
作者简介
本文由英国南安普顿大学与广州大学合作完成,第一作者为英国南安普顿大学计算机学院博士生 Shuyan Zou。通讯作者为南安普顿大学助理教授 Han Wu 与广州大学王绍蔚副教授。论文核心成员包括来自英国南安普顿大学的 Vladimiro Sassone 教授和 Zhanxing Zhu 副教授,以及广州大学的董长宇教授和李进教授。相关团队长期从事人工智能与网络安全交叉方向研究,重点关注隐私保护机器学习、差分隐私优化、可信 AI 训练机制以及大模型安全等方向。
[1] Abadi, Martin, et al. "Deep learning with differential privacy." CCS 2016.
[2] Andrew, G., Thakkar, O., McMahan, B., & Ramaswamy, S.(2021). Differentially private learning with adaptive clipping. Advances in neural information processing systems, 34, 17455-17466.

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com










