
Mythos 被禁了。
Anthropic 那个让硅谷集体沉默的模型,美国政府不让卖给中国。X 平台上有人直接问马斯克:中国什么时候能追上?Musk 说九个月。智谱首席科学家唐杰回了一句:用不了那么久。

GLM-5.2 刚发布,评测全面逼近前沿,基座差距在肉眼可见地收窄。唐杰的底气大概率来自于此。但我们更关心另一个问题:追上 Mythos,光靠基座迭代够不够?
不够。OpenAI 从 GPT-4 到 o1,核心增量来自后训练。Anthropic 的 Constitutional AI,本质是后训练方法论。基座决定上限,后训练决定你能摸到上限的多少。事实上,GLM 从 5.1 到 5.2 的能力跨越,本身就是后训练的胜利。
而这恰好引出一个关键事实:恰好两周前,机器之心一家专门做大模型后训练的团队:Mind Lab,隶属于 Mindverse(心洲科技)。从 HuggingFace 的数据来看,他们目前是全球唯一一家完成了 GLM-5.1/5.2 系列后训练的外部团队。 他们基于 GLM-5.1 后训练的模型 Macaron-V1-Preview,评测结果已经超过了基座本身,提分幅度不小。
这意味着什么?如果 GLM 基座能力继续往上走,Mind Lab 在后训练上已经验证过的提分能力再叠加上去,通过后训练路线追平 Mythos 级别的智能,Mind Lab 同样有机会。
但这次看到唐杰那条回帖,我们重新去看了一眼 GLM 的后训练生态。发现的事情挺振奋人心的。
去 HuggingFace 上翻了一圈
从 HuggingFace 上看来,Mind Lab 目前仍然是全球唯一一家,完成了 GLM-5.1/5.2 系列模型后训练的实验室。 GLM-5.1 的 finetune 和 adapter 分类下,翻来翻去就是他们一家做完了全流程并公开发布。
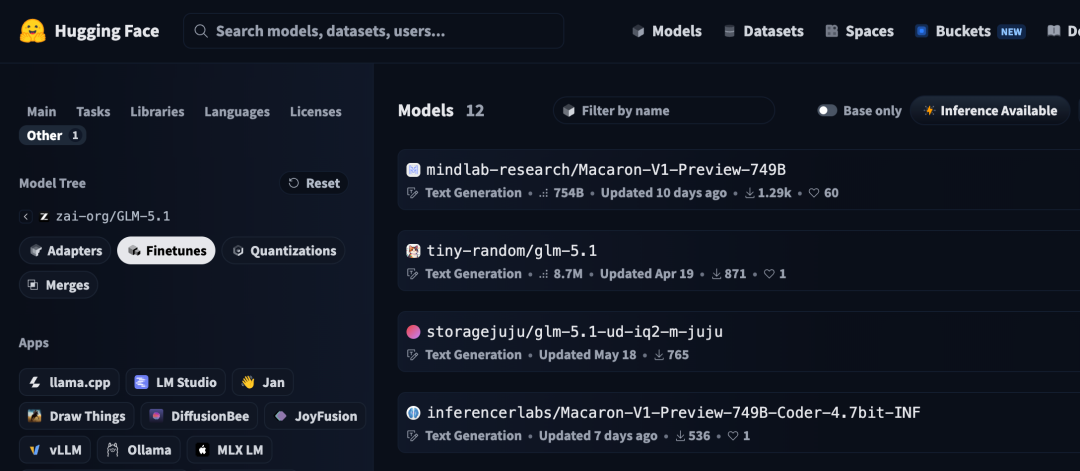
一个有意思的细节:HuggingFace 上 GLM-5.1 后训练模型下载量排第四的,其实是另一个团队(inferencerlabs)对 Macaron 做量化后可以直接运行在 Mac 上版本。别人的模型已经在被二次加工和传播了,生态影响力在自发形成。
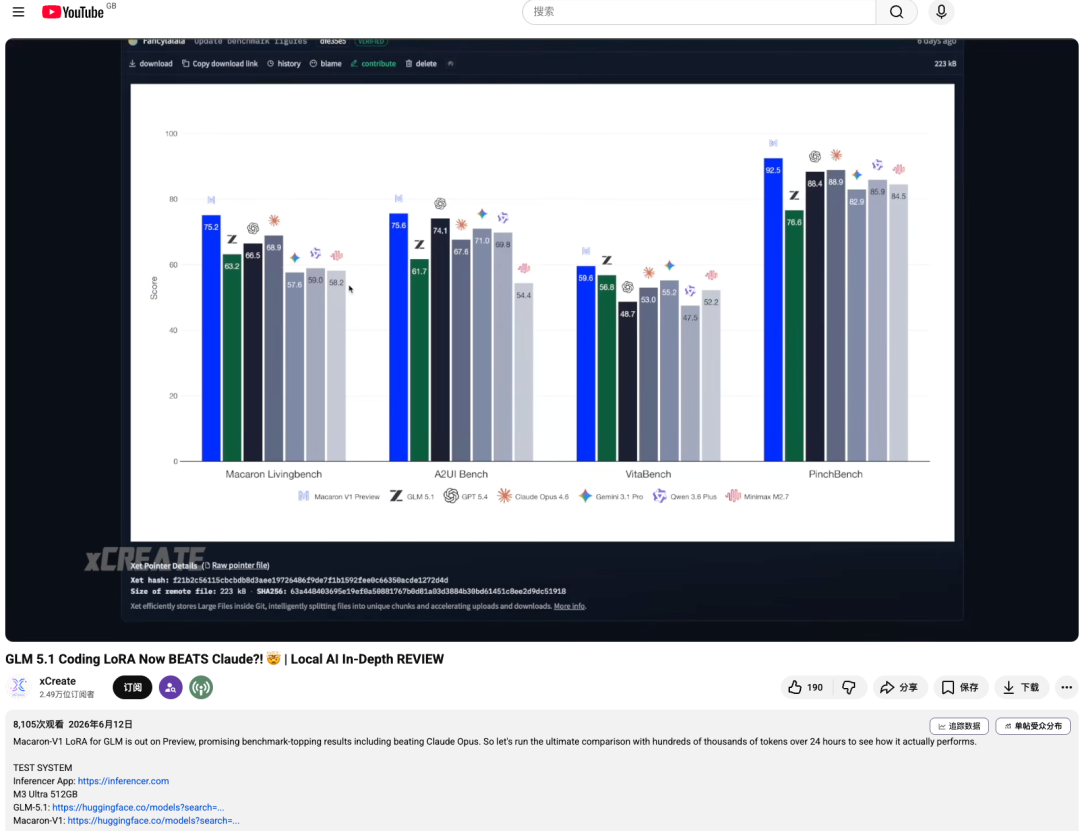
GLM-5.2 发布之后我们又去看了,Mind Lab 同样是第一个宣布支持并启动后训练的。值得一提的是,GLM-5.2 引入了一个全新的架构设计 IndexCache,这是该版本区别于 5.1 的核心技术变化之一。Mind Lab 已经完成了对 IndexCache 的完整适配,并将方案直接开源了出来。新基座刚发布,核心新架构的训练支持就已经到位并开源,这个响应速度本身就说明问题。更早之前,他们在技术博客里就披露了对 DSA(动态稀疏注意力)和 MTP(多 token 预测)这些 700B 以上模型特有架构模块的适配方案。
从架构适配到训练框架再到开源发布,每次 GLM 出新版,Mind Lab 跟进的速度都是按天算的,这不是临时抱佛脚能做到的事。

后训练提了多少分
上一轮的成绩单已经摆在那里了。
先前基于 GLM-5.1 的后训练,Mind Lab 的提分幅度相当可观:PinchBench 从 GLM-5.1 基座的 76.6 分提升到 Macaron-V1-Preview 的 92.5 分,涨了 15.9 分,相对提升约 20.8%;Terminal-Bench 2.0 从 63.5 分提升到 67.4 分,涨了 3.9 分。这个幅度说明一件事:GLM 系列的基座能力远没有被充分释放,后训练还有很大的提分空间。
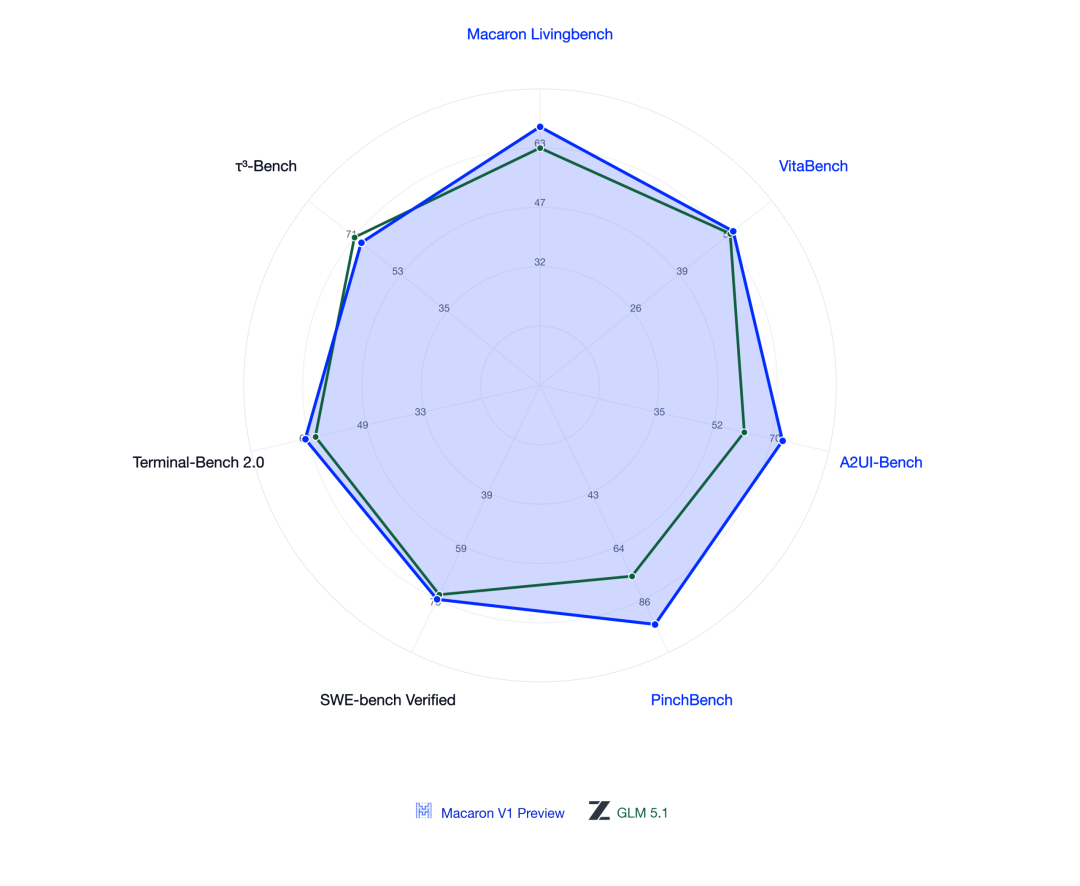
现在他们搬到了 GLM-5.2 上。5.2 比 5.1 基座能力有显著跃升,后训练能释放的空间也跟着变大。
GLM5.1 到 5.2 的跨越,本质上就是后训练的胜利。而 Mind Lab 是目前唯一具备 GLM5.1/5.2 后训练能力的外部团队,而且是目前唯一具备 GLM5 系列后训练能力的外部团队。智谱的基座能力还在持续往上走,年底大概率会发布新一代模型。到那个时候,基座本身的能力跨了一大步,Mind Lab 在后训练上积累的提分能力再叠加上去,逻辑链条是连续的,Mind Lab 同样有机会追平 Mythos 同等水平的智能。
而且有一点容易被忽视:做后训练的团队,迭代周期天然比做基座的短。基座训练动辄几个月,后训练的周期是按周算的。新基座一出来,后训练团队理论上可以比基座团队自己更快地把能力释放出来。在「从智谱新基座到 Mythos 级别产品」这段路上,Mind Lab 的节奏可能比你想象的快,因为他们只押这一件事。
除了智谱自己,只有他们
既然后训练价值这么大,为什么做的人这么少?
门槛不低。三个能力缺一不可:
对基座架构的深度理解。GLM 使用的 MTP 和 DSA 都是在 700B 以上模型才用到的技术,indexcache 更是支持 GLM5.2 训练到 1M 上下文的关键技术,不是拿开源训练框架直接跑得通的。
高质量训练数据的构造能力。后训练和预训练用的数据完全不同,不是规模取胜,而是质量和结构取胜。这部分的 know-how 在行业里高度不透明。
工程基础设施。大模型后训练同样吃算力,同样需要精细到每个超参数的训练策略管理。就在最近,Mind Lab 直接开源了一套支持 GLM-5.1 和 5.2 的 Megatron 训练框架。 这意味着他们不只是在现有框架上做适配,而是从训练基础设施层面把 GLM 系列的后训练链路打通了,而这个工程量本身就是一道很高的门槛。
GLM-5.1 发布到现在不短了,HuggingFace 上做完后训练并开源的只有一家。除了智谱自己以外,Mind Lab 是目前唯一展现出有能力在 GLM 最新基座上做后训练的外部团队。 这个位置本身就是稀缺的。

九个月够不够
Mythos 被禁,中国想用上同等能力只能靠自研。马斯克说九个月。唐杰说用不了那么久。
唐老师表示,做出中国的 Mythos,需要两条腿走路,即基座预训练迭代和后训练模型的自我迭代。智谱在前者的位置很明确,而后者的位置上,Mind Lab 是目前除智谱以外唯一交出公开成果、并且持续在 GLM 最新基座上迭代的团队。
后训练赛道在国内还没有得到足够关注。大部分讨论集中在基座之争:谁的参数多、谁的评测高、谁又发了新版本。但当基座差距逐渐收窄,后训练的质量会越来越成为产品体验的分水岭。
九个月够不够,我们不确定。但有一件事是确定的:在 GLM5.1/5.2 的后训练路线上,目前唯一看得到路径、并且已经用成绩证明过提分能力的外部团队,就是 Mind Lab。Mythos 级的智能不是只有预训练一条路能到,后训练这条路上,Mind Lab 已经站在了最近的位置。
这件事,振奋人心。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com










