
AI 读论文这件事,正在进入下一个阶段。
最近,alphaXiv 推出了一个面向 arXiv 论文的 autoresearch 功能。

来源:https://x.com/askalphaxiv/status/2067593673072877833
它的使用方式非常直接:当用户看到一篇论文时,只需要把论文 URL 里的「arxiv」改成「autoarxiv」,系统就会:
修复代码库配置问题:自动处理依赖、运行环境和配置问题。
运行最小化复现:执行一个简化版实验,确认论文结果是否真的能够被复现。
估算完整复现成本:告诉用户如果要完整复现整篇论文,大概需要多少计算资源。

AI 开始帮你复现论文
官方还放出了一段完整的演示视频,更直观地展示了 autoarxiv 背后的工作流程。
在演示中,系统首先根据论文的 arXiv ID,自动在 GitHub 上搜索对应的开源代码仓库,并将其导入到 AI 智能体的开发环境里。随后,用户向智能体提出了一个很具体的请求:能否实现一个端到端、可以完整跑通的最小化复现?
任务启动后,智能体没有直接运行代码,而是先自动克隆仓库,阅读 README.md,检查项目结构,并分析原始实验的运行要求。它很快发现,论文对应的完整实验规模并不小:原始配置需要 4 张 H100 显卡,运行约 15 分钟,完成 100 步迭代,同时还依赖特定的本地数据集路径。
这也是论文复现中最常见的现实问题:代码虽然开源了,但默认配置往往面向作者自己的实验环境。对于普通研究者或工程团队来说,完整复现实验的硬件门槛、路径依赖和环境差异常常会成为第一道障碍。
为了把这个实验压缩到单张显卡也能运行的范围内,智能体开始自主制定「最小化复现」方案。
模型替换:将基座模型从较大的降级为更轻量的。
参数压缩:将训练步数限制为 40 步,每 20 步保存一次。
资源优化:将 num_processes(进程数)设为 1,关闭 DeepSpeed 等多卡并行加速,并开启 LoRA 训练以节省显存。
编写脚本:智能体自动编写或修改了启动脚本 run.sh 以及用于提取和分析日志结果的 summarize_eval.py。
视频最后展示了智能体对代码所做的修改对比,清晰地列出了它新写入的 run.sh 和 summarize_eval.py 的具体代码行。
这段演示的重点也正在这里:autoarxiv 里的 AI 智能体并不只是「读懂论文」。它更像是一个论文复现助手,能够根据当前算力资源,对复杂的开源 AI 训练代码进行降维裁剪、环境适配和调试。
这类能力对科研和工程团队都很有价值。因为在真实研发流程里,团队往往并不需要一开始就完整复现论文里的全部结果,而是先要判断代码能不能跑起来,完整复现大概要投入多少算力和时间?
我们也亲自上手体验了一下。以 2017 年的经典论文《Attention Is All You Need》为例,按照官方给出的方式,将论文 URL 中的「arxiv」替换为「autoarxiv」后,页面随即跳转到 autoarxiv 的任务界面。
系统很快识别到了这篇论文对应的代码仓库,并给出提示:「我们找到了这篇论文对应的代码。请确认要导入的代码仓库,或者将其替换为其他仓库。」
也就是说,用户进入 autoarxiv 后,第一步并不是手动查找代码、配置环境,而是由系统先自动关联论文与代码仓库,再让用户确认是否基于该仓库继续执行后续复现流程。
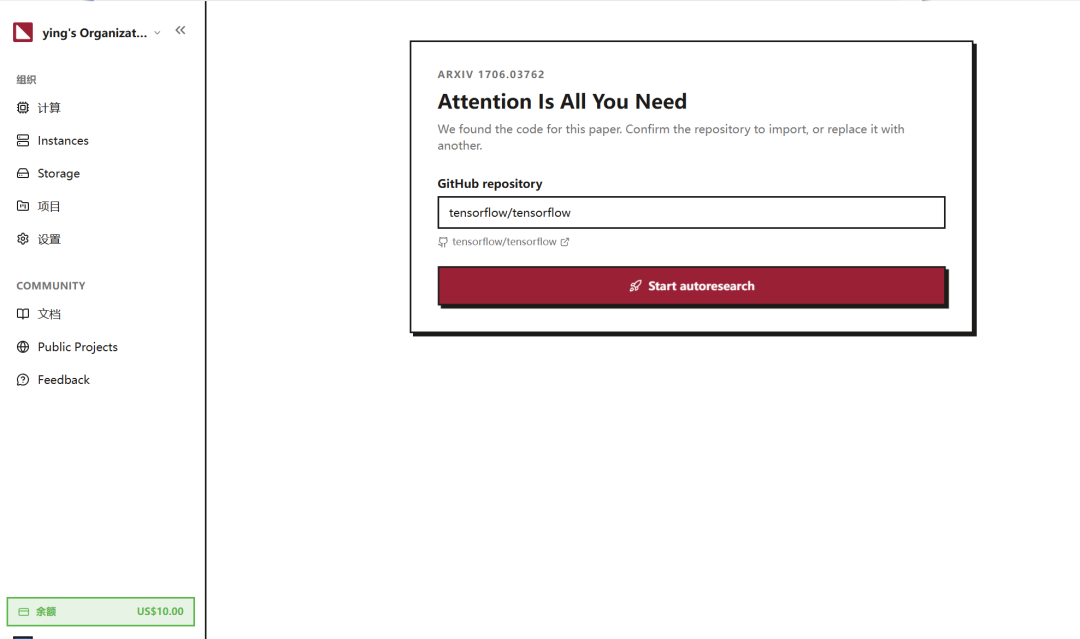
接着出现正在导入代码仓库提示,显示为「正在导入 tensorflow/tensorflow 并配置运行环境,这需要几秒钟。」

不过这个过程实在是太慢了,大家可以亲自去试一下。
不用自己准备 GPU,也能复现和迭代论文
有人在评论区直呼「太酷了」,并祝贺 alphaXiv 正式发布这一能力。


「复现并迭代 AI 论文,甚至不需要自己准备 GPU。」

也有人很快关注到一个关键问题:这样的复现环境究竟由平台统一托管,还是用户也可以接入自己的算力基础设施?
对此,alphaXiv 官方给出了明确回应:用户可以使用自己的计算资源和智能体。
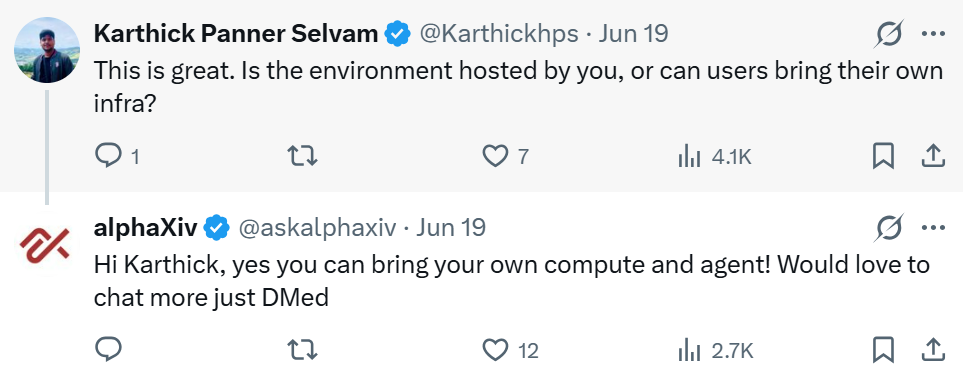
对于普通用户来说,它降低了论文复现的启动门槛;对于实验室和企业团队来说,它也留下了接入自有算力、私有代码库和自定义 Agent 的空间。
以后读论文,不用光总结,也可以先跑跑看了。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com










