新智元报道
新智元报道

【新智元导读】就在所有人还在为Claude Fable 5的突然消失而懵圈时,Sakana AI却高调宣布:我们的Fugu比肩Fable,还不怕出口管制。
Anthropic最强的模型Claude Fable 5全球禁用,还不知道何时解封。
前有,OpenRouter上线了Fusion功能,半价实现Fable级别智能。
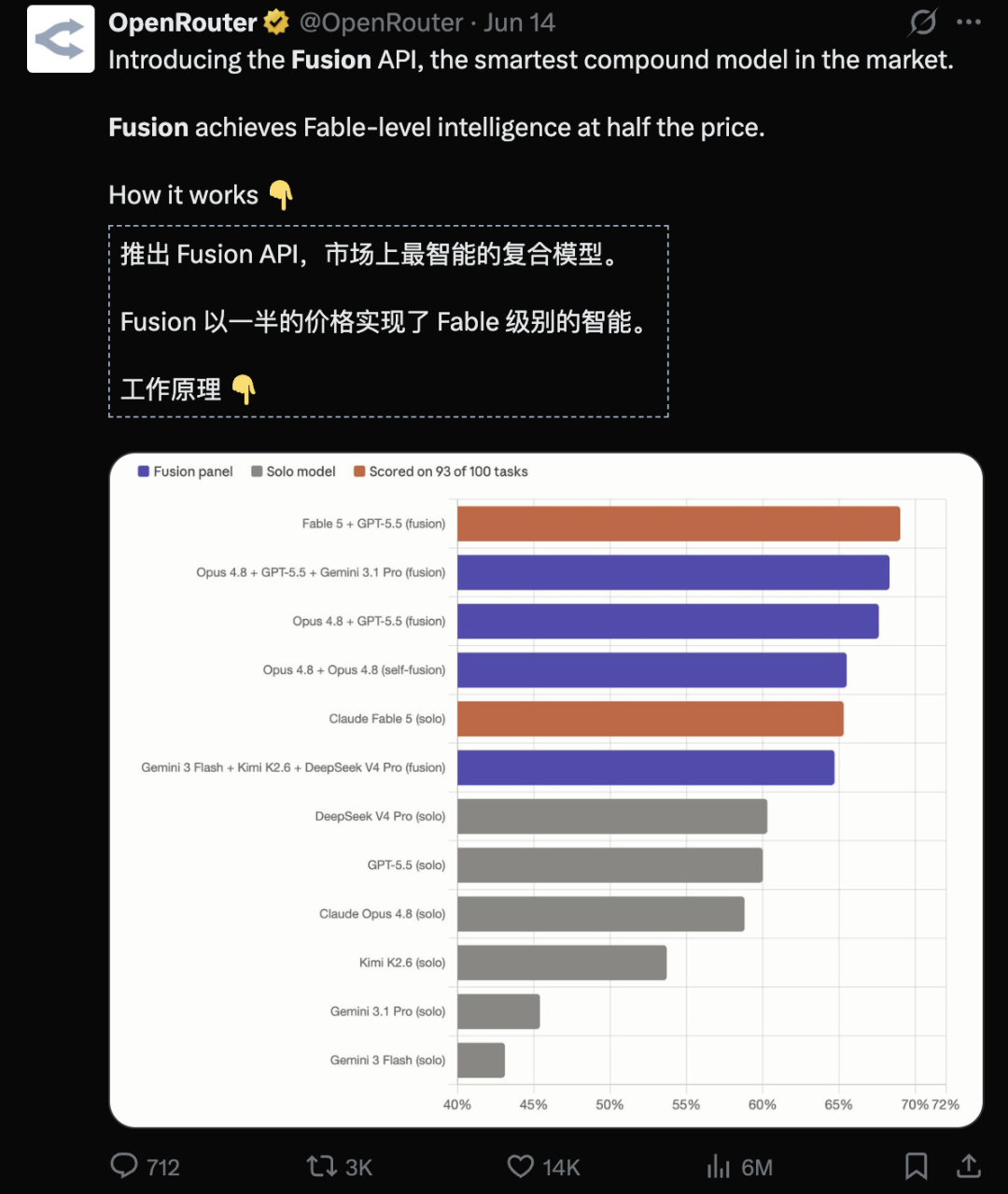
刚刚,Transformer发明者Llion Jones等共同创立的AI企业Sakana AI,把这招也学会了。
他们宣称,Fugu Ultra模型性能比肩Claude Fable和Mythos。


Fugu的声明中,明确将「无需承担出口管制风险的前沿能力」作为核心卖点,嘲讽拉满。
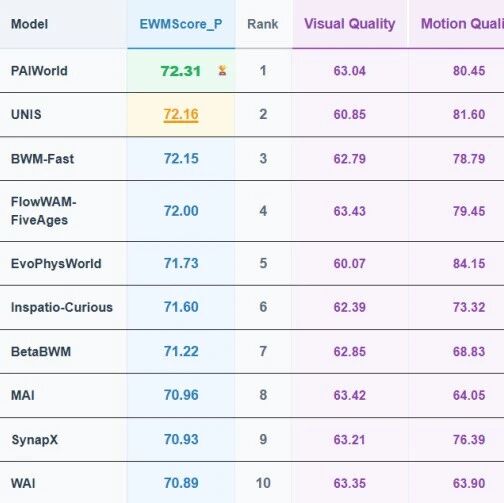
在行业最严格的工程、科学和推理基准测试中,Fugu与Fable、Mythos等领先模型并驾齐驱。

新潮流来了:Anthropic的Fable 5成了新的Benchmark。

6月9日Mythos发布,6月12日下线,仅存活72小时。
这是美国政府首次使用出口管制权威强制已部署的前沿AI模型下线:不仅限制境外用户,还包括美国境内的外国公民,甚至Anthropic自己的外籍员工。
访问权限说没就没,一夜之间就能切断。
这一棒子打懵所有Claude Fable 5用户。
如今,模型调度能力已不只是技术优化,而是刚需。
继OpenRouter之后,Sakana AI迈向AI下一个前沿,打破大模型霸权。

集体智能,正是对抗这种权力过度集中的最实用对冲。

Fugu的核心优势就在于:
它背后编排着一整个可自由切换的AI智能体池,碰到单一供应商限制时,能自动绕道、换模型继续跑,系统韧性大幅提升。
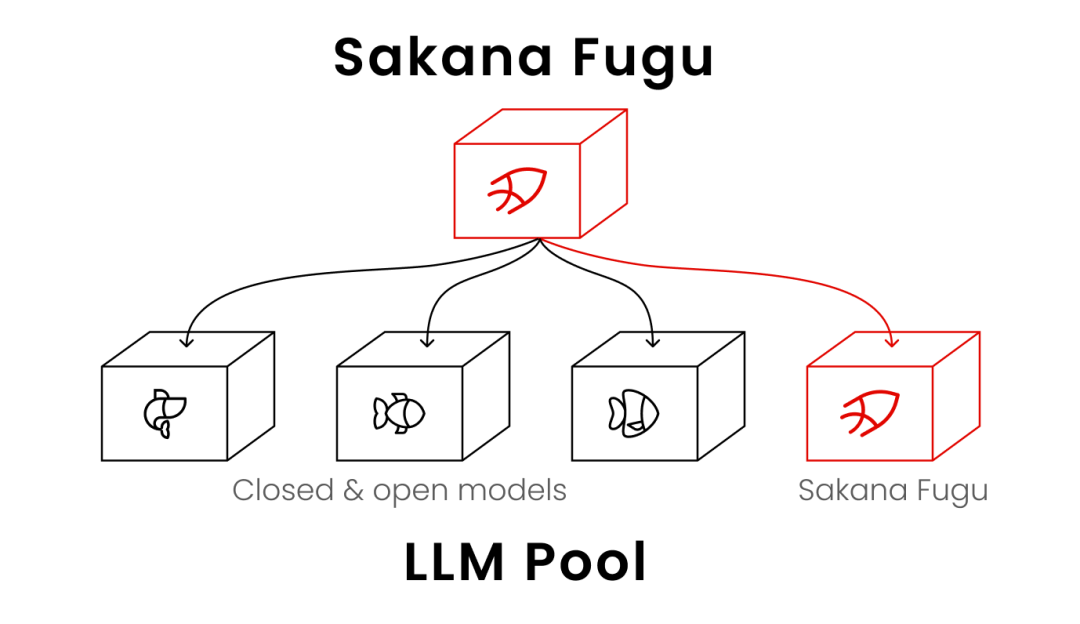
Sakana Fugu本身就是语言模型,经过训练后能够调用agent池中的各种大语言模型——其中也包括以递归方式调用它自己的实例。
Fugu会动态编排全球最顶尖的模型,来完成复杂的多步骤任务。
未来不是比谁的模型更大,而是看谁能把全球的模型「编排」得更好、更稳、更自主。
单一模型的智能上限依旧重要,Scaling Law依旧重要,但「调度模型」(Orchestration Models)时代来了。

Fugu并非传统意义上的AI模型。
它是多智能体系统,利用并放大它们不同的技能组合,指明了AI能力跃升的新路径。

Fugu与Fable 5和Mythos Preview水平相当、不相上下。
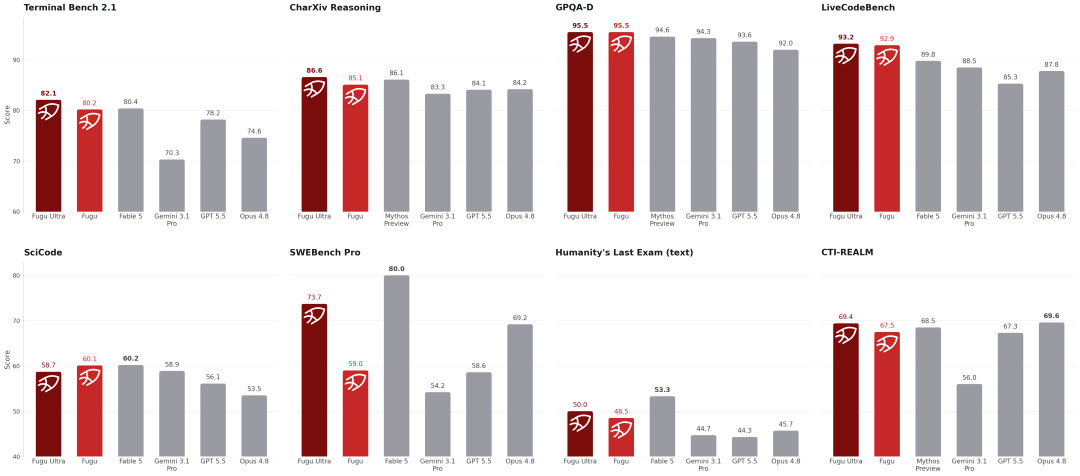
在智能体编程和软件工程方面,Fugu-Ultra表现尤为突出,在SWE Bench Pro和Terminal Bench 2.1两个测试基准上,都达到了当前最优水平,且性能均有大幅跃升。
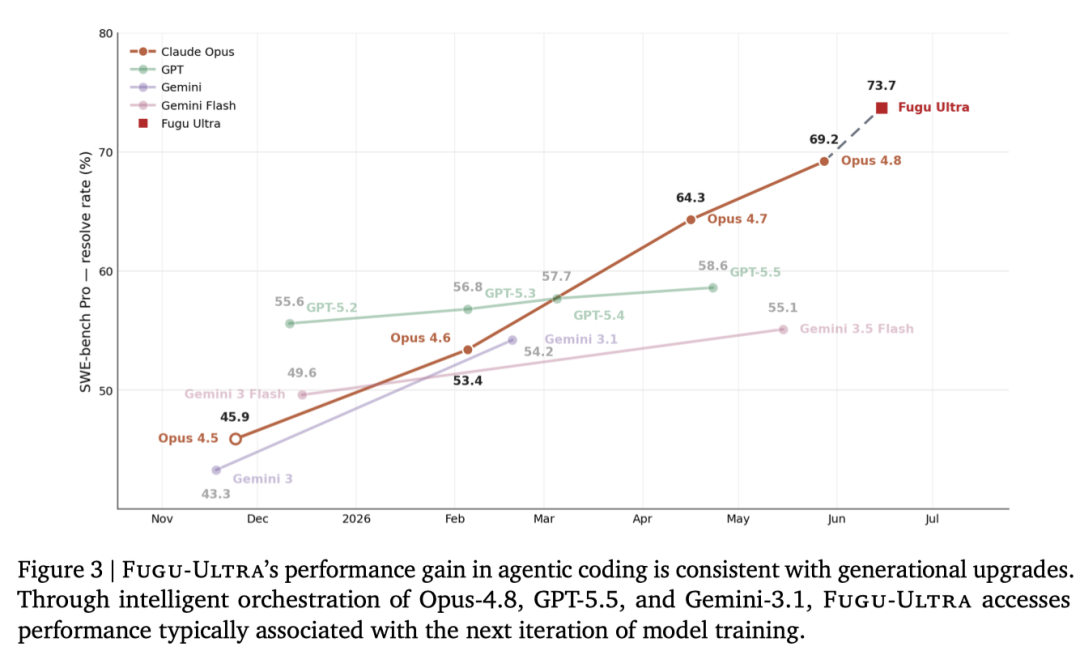
在这两个基准上,Fugu-Ultra相较于次优模型的提升幅度均达到5%–6%。
这与这些前沿模型供应商的整个大版本升级所带来的提升相当。
在科学推理方面,Sakana Fugu模型同样表现出了显著的能力提升,甚至超过了Mythos Preview和Fable 5。

这一发现进一步印证了训练Sakana Fugu的核心动机之一:
智能调度应该成为提升性能的另一个维度,而不必依赖增加训练算力。
智能调度器的一个标志性特征是自适应性。
在整个评估过程中,Fugu模型在其路由分配上展现出持续且多样化的自适应性。
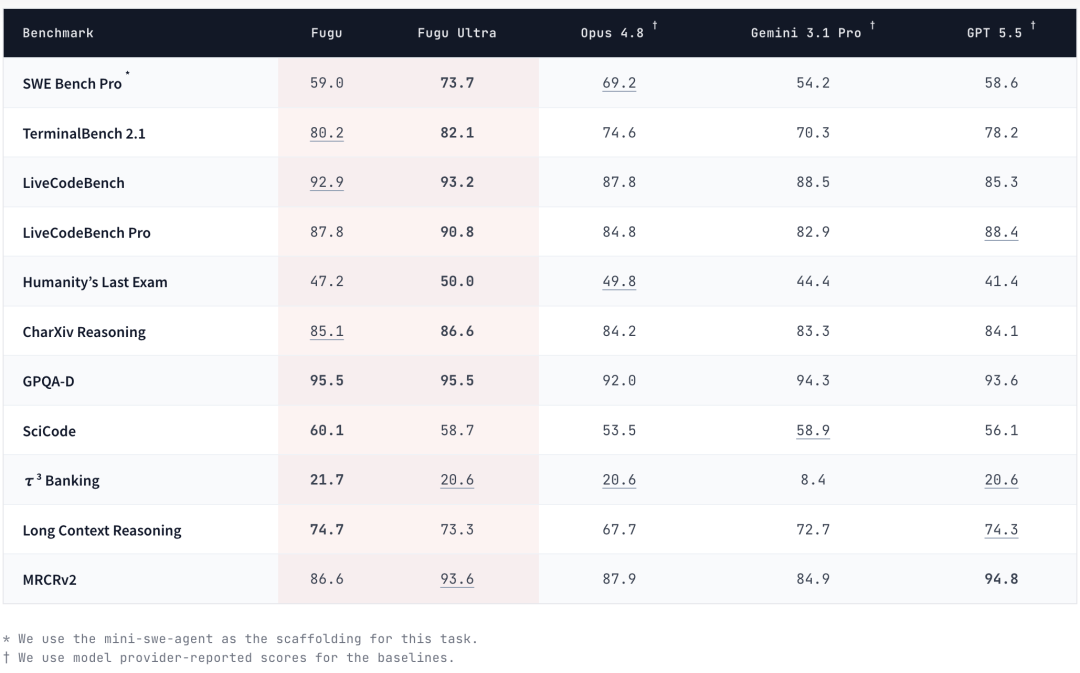
这表明新模型能够准确地学习到模型团队中各成员的不同技能,并根据这些专业特长来有针对性地调用相应模型。
为了补充整体基准测试分数,Sakana Fugu模型对比了三个前沿基线模型:Gemini 3.1 Pro(high)、Opus 4.8(max)和GPT 5.5(xhigh)(被随机匿名化为模型A、模型B和模型C)。
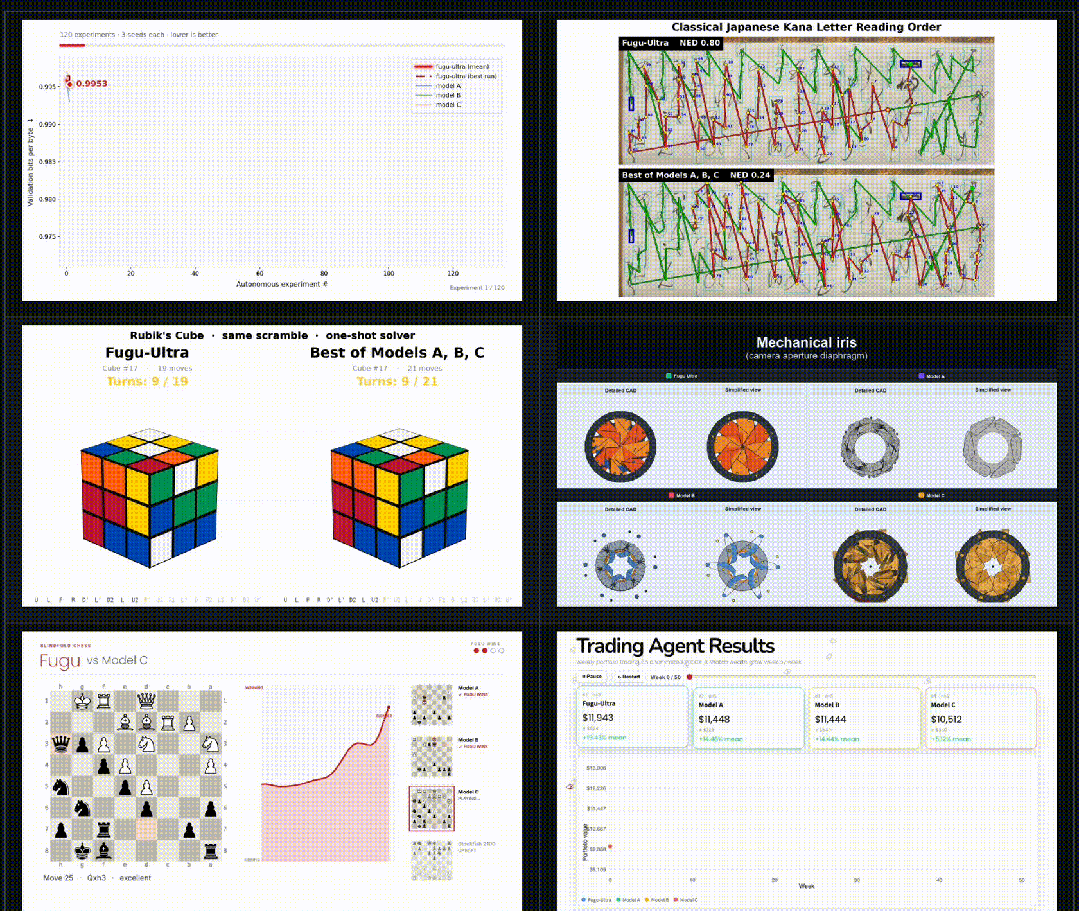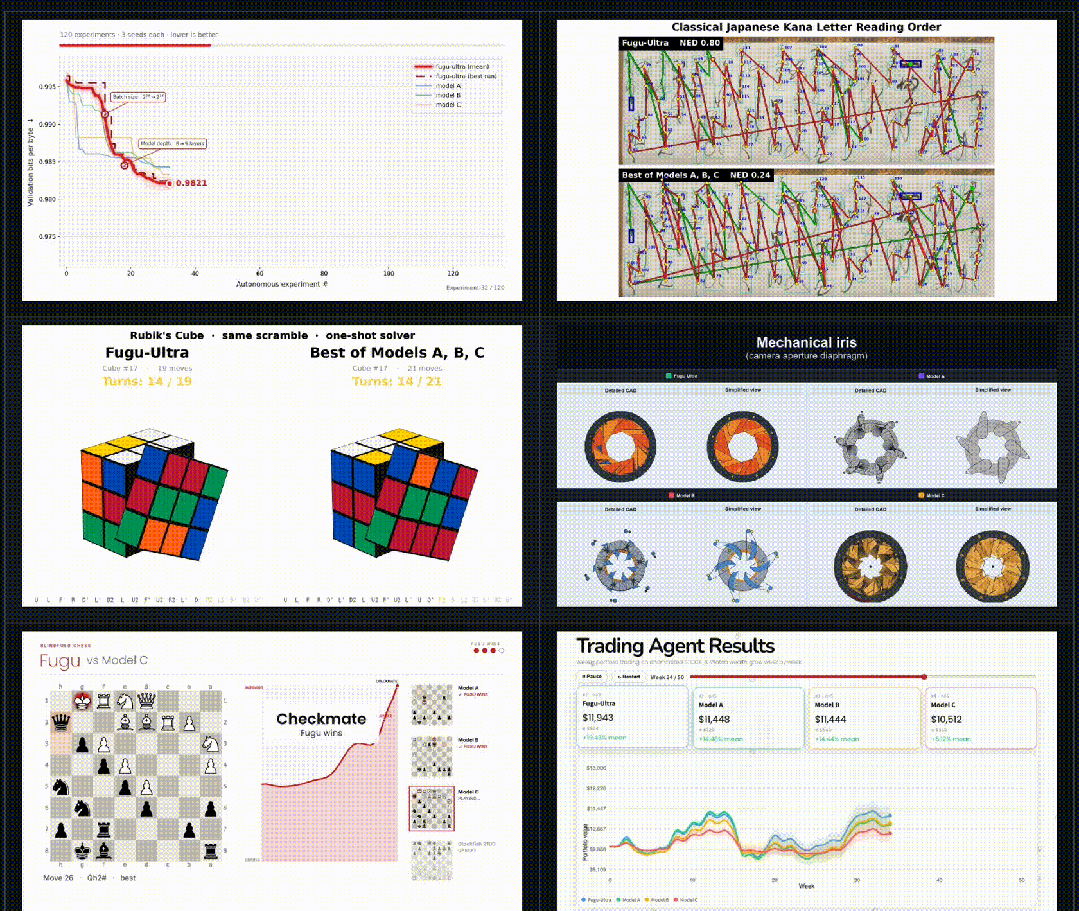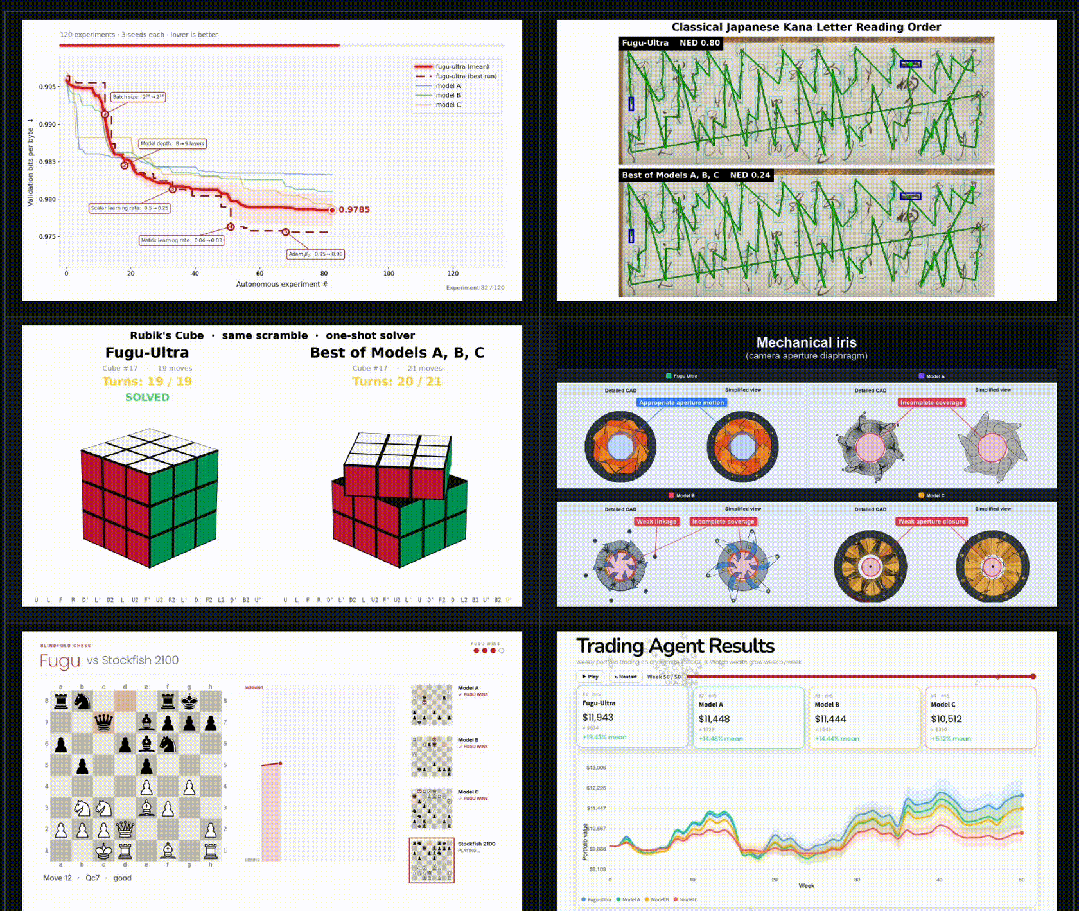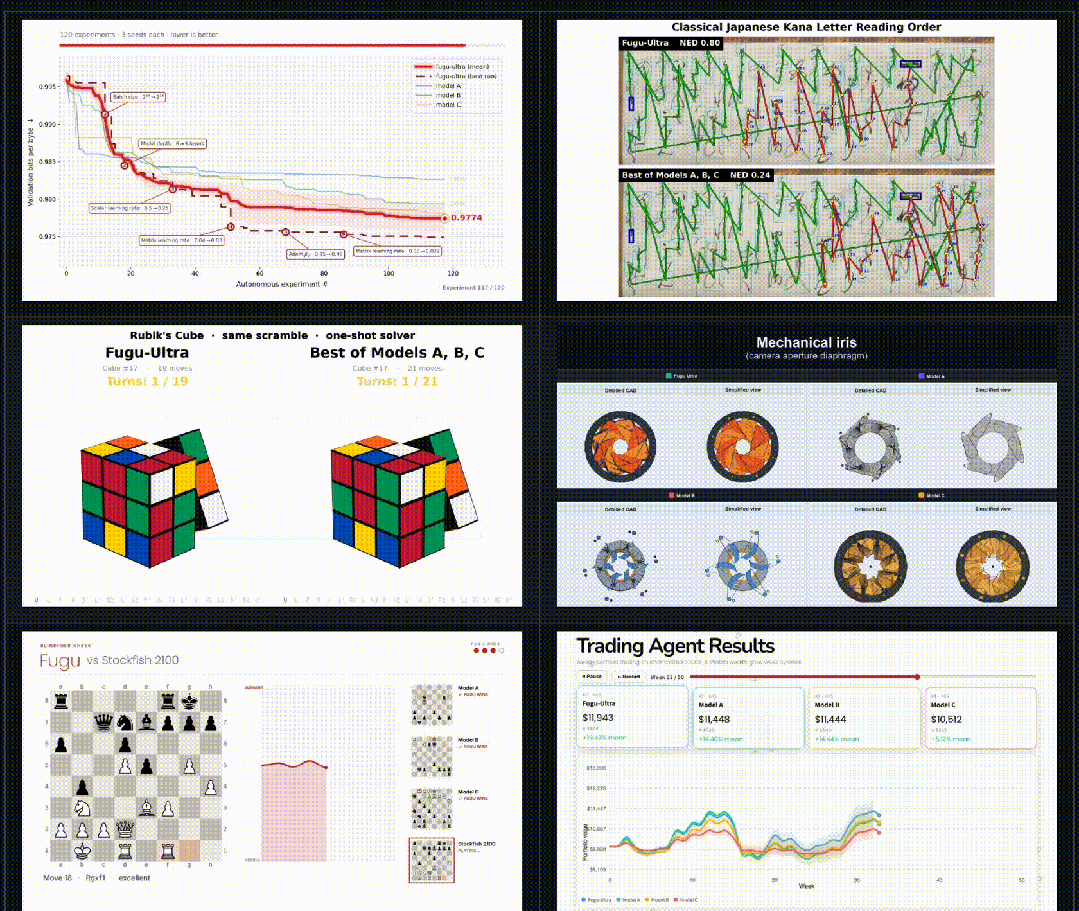
这些任务强调真实的智能体行为,例如长周期研究、程序合成、优化、CAD生成等。

Fugu会动态调度全球顶尖模型,攻克复杂的多步骤任务。
只需一个 API,今天就能把集体智能直接接入你的工作流。
上线时,Sakana Fugu将提供两个模型,并通过OpenAI兼容API访问:
• Fugu在日常工作中兼顾强大性能和低延迟。
• Fugu Ultra是旗舰模型,专门针对困难的多步骤问题调优,追求最高答案质量。
Fugu Ultra会协调一个更深入、更强大的专家智能体池,处理AI研究、网络安全分析和专利调查等高要求工作。
Sakana Fugu主要基于两篇ICLR 2026论文。
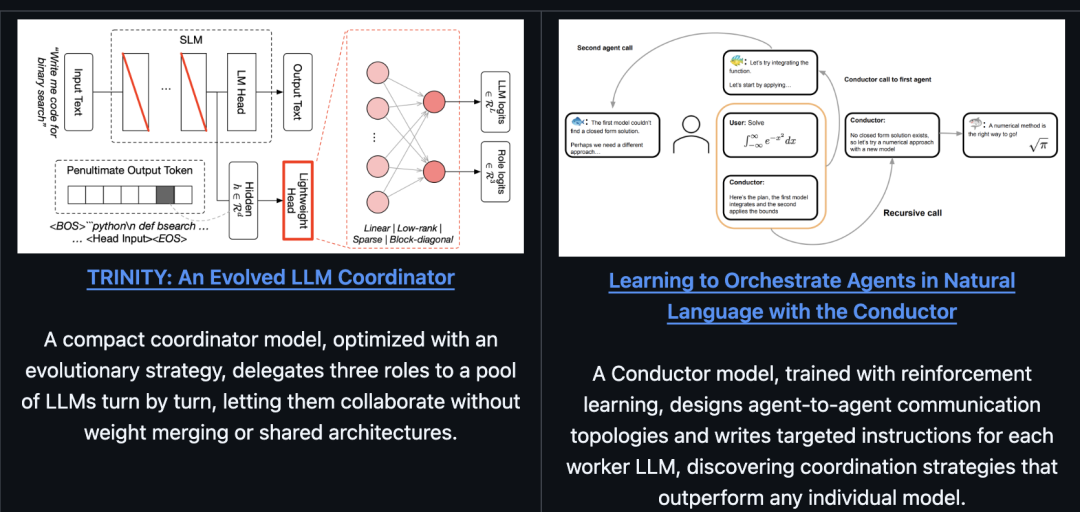
针对每个任务,Fugu学会了自行组装、调度和协调多个专家模型,而不需要依赖人工设计的工作流程。
Fugu使用一个预训练语言模型作为骨干,并基于自身的隐藏状态来协调工作模型池。
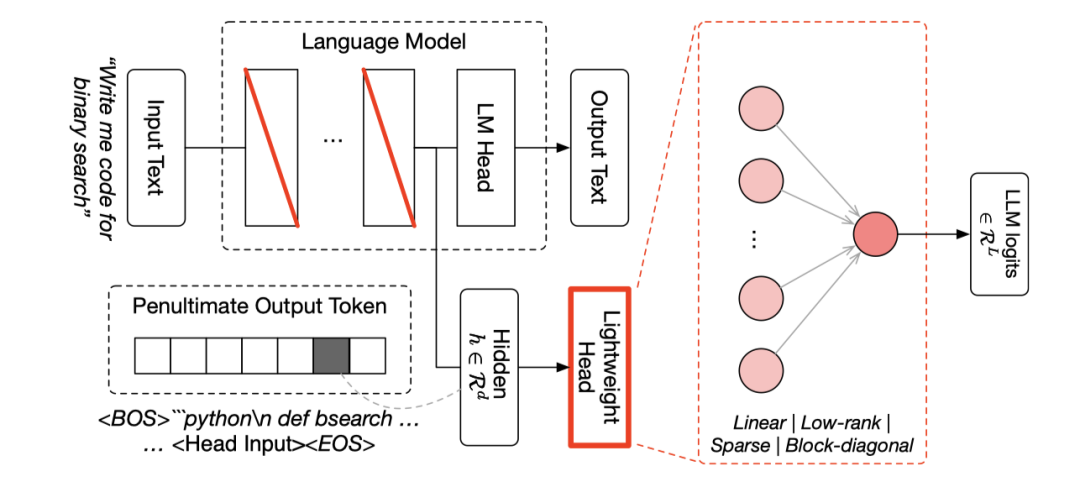
Fugu并行运行一个轻量级的选择头与基础模型的语言模型头。
它从骨干网络中接收一个隐藏状态ℎ作为输入,并为池中的每个工作模型输出𝐿个logits。
选定的模型总是作为工作模型被调用,这减少了协调空间并降低了编排延迟。
研究团队还对LM层中选定参数矩阵的奇异值尺度进行微调,这些参数矩阵由红色的对角线指示。
在上图中,标记为<Head Input>的位置的隐藏状态是轻量级头部的输入。
需要注意的是,轻量级头在内部隐藏状态上运行,而不是在最终的解码文本上。
Fugu采用两阶段方法来训练。
首先进行大规模的监督式微调(SFT)。
此阶段汇集了众多单步任务,覆盖了编程、数学、推理、语言理解以及多种智能体使用场景。
在单步任务上进行监督式微调之后,通过在端到端任务上应用进化策略进一步优化Fugu。
从不同的编码助手环境(如Claude Code、Codex和OpenCode)中,他们收集了真实世界的多轮轨迹,并构建了涉及仓库上下文、迭代编辑、工具调用、执行反馈和最终任务完成的端到端任务。
这一阶段将训练分布从静态问题扩展到更好地反映生产使用的智能体工作流程。
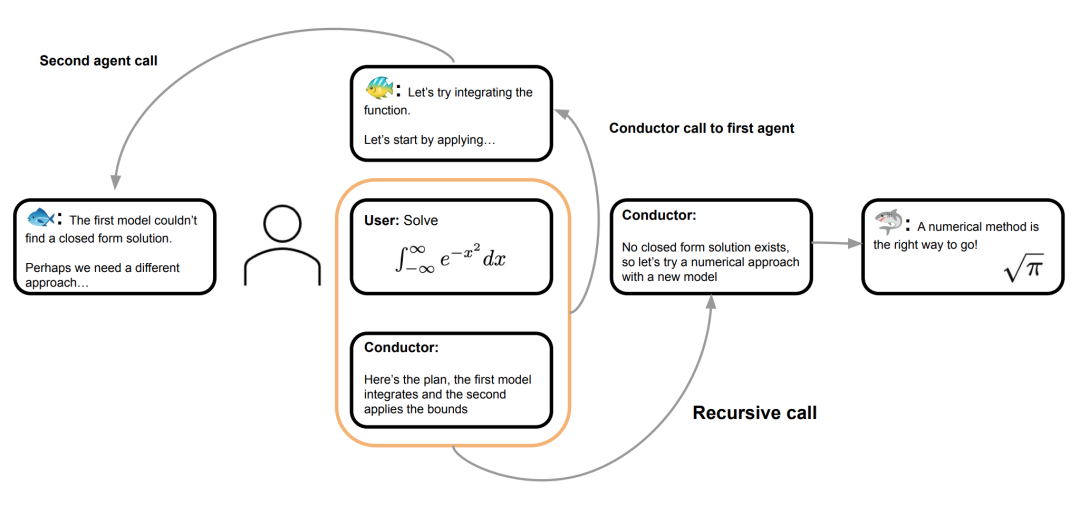
Conductor是用强化学习训练出来的,它能自己摸索出怎么用自然语言来协调不同模型之间的配合,包括安排它们怎么交流、给它们设计更精准的提示。这样一来,多个大模型一起干活,比单独用任何一个模型都更擅长处理高难度的推理题目。
这次最重要的可能不是跑分,而是展示了一种新的趋势:大模型称霸终将过去,调度为王才是未来。
参考资料:
编辑:大卫