

继布局通用计算 CPU核(X60/X100/X200)、智能计算 AI 核(A60/A100/A200)后,进迭时空迎来核心技术版图的重大升级——进迭时空的新一代自研互联总线 N200 正式完成研发。
随着 N200 的研发收官,进迭时空已完成通用计算、智能计算、计算互联三大核心技术板块的布局。互联总线 N200 将与通算 CPU 核 X200、智算 AI 核 A200 一起应用于进迭时空的下一代计算芯片中,并预计于 2027 年正式量产。

在数字化智能时代,如果把一颗多核 SoC 算力芯片比作一个"智能体",XPU 核是其"大脑"群,包括通用 CPU 核、AI 核、GPU 等,那么总线就是贯穿其间的"骨架"——它将多个大脑互联起来做算力协同扩展,将所有大脑与存储器互联起来做高速数据通信。总线虽不直接产生算力,却决定了所有算力能否有效发挥;虽不直接生产或存储数据,却决定了数据能否高速准确地传输。
随着多核、多 Chiplet、多 Chip 算力扩展成为高端 AI 算力芯片的主流路径,互联总线正在成为决定整系统性能上限的关键技术底座之一。N200 在多层次互联扩展、硬件 Cache 一致性覆盖范围、跨封装互联带宽等方面均实现大幅跃升,为下一代 AI 算力平台提供坚实的互联底座。

N200 支持:面向多核、多 Chiplet、多 Chip、多 Board 全栈互联能力
四层互联架构
无论是通用 CPU 算力时代,还是智能 AI 算力时代,算力芯片都沿着"由单到多"的路径演进——多核、多 Chiplet、多 Chip、多 Board。N200 围绕这一演进趋势,设计了四个层次的互联能力:
全层级硬件 Cache 一致性
降低多核软件编程复杂度是高端算力芯片的核心诉求之一,硬件 Cache 一致性是不可或缺的基础特性。N200 以 AMBA CHI 为一致性协议基础,面向云计算与 AI 推理场景,自研实现了以下一致性能力:
完善的工程化特性
N200 围绕芯片工程实践提供了完整的配套能力:
▲
支持 AXI2CHI、CHI2AXI 等各种协议转换桥,便于 PCIe、GPU 等各类 I/O 外设接入;
▲
支持多种类型的聚合节点,可有效节省 Ring 环节点,利于后端优化实现,提升整体性能;
▲
支持专有的消息与配置互联通路,与主通路解耦,用于中断传递、Trace 数据传输和寄存器访问;
▲
支持符合 RISC-V RERI 规范的端到端 RAS 实现;
▲
提供灵活的时钟结构,包括同步分频、异步桥接等,可满足各类场景需求;
▲
支持 Debug & Trace 能力;
▲
提供丰富的 PMU 性能统计接口;
▲
支持 Partial Good 设计,以提升芯片量产良率;
▲
提供完整配置 GUI,可灵活支持定制化生成需求,支持 RTL 分区分层自动生成与校验,降低物理实现难度,支持配置文档与集成测试集生成。
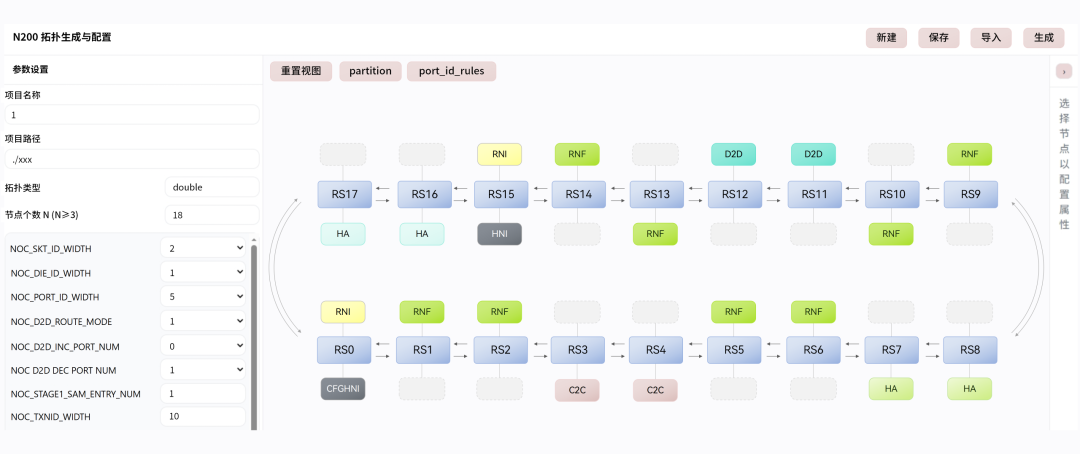
N200 GUI 配置界面
主要性能指标
研发进展:系统验证进行中,FPGA 平台已完成关键验证
N200 已完成整体架构设计、RTL 开发与验证、PPA Push、驱动开发与软硬件协同验证; 同时,基于 FPGA 原型平台,与 X200 构建面向下一代算力芯片的原型系统,现已完成多个关键验证。
以下 Demo 展示了 8 个 CPU Clusters(单 Cluster 集成 2 个 X200 核)通过 N200 互联的完整 SoC 系统在 FPGA 平台上成功运行 openRuyi 国产操作系统,并依托 PCIe NVMe 接口完成存储子系统的应用级功能测试,充分验证了多核互联与高速外设协同工作的稳定性与可靠性。
进迭时空 · 自研芯片技术矩阵
N200 是进迭时空新一代的自研互联总线,与通算 CPU 核、智算 AI 核共同构成下一代算力平台的核心技术底座。从高性能 CPU 核、AI 核到互联总线的全栈自研,是进迭时空在高端 RISC-V 算力芯片领域持续布局核心根技术的具体体现。


点击下方图标,关注进迭时空 SpacemiT 资讯平台
▼














![[生态进展] VSCode RISC-V 插件正式支持进迭时空(SpacemiT)AI 拓展指令集](https://xtechcon-static.oss-cn-chengdu.aliyuncs.com/xtimes/xtimes/images/2026-03-02/69a57ce3423bf.jpeg)