大家对 Stable Diffusion 应该不陌生——作为文生图扩散模型的代表,不管是学术研究还是艺术创作,它都是最常用的工具之一。甚至掀起了一波"炼丹"热潮,社区里各种各样的玩家都在给底模做风格化微调。
现在这个领域早就过了能不能跑的阶段,大家开始关心:能不能在更小的设备、更低的功耗、更稳定的环境里长期跑? 这次瑞莎 AI 团队把 Stable Diffusion 1.5 / 2.1 移植到了 Fogwise® AIRbox Q900 (以下简称 Q900) 上,还把 Civitai 社区里几个热门的高质量底模转换成了 Qualcomm QNN 模型,直接在 Q900 的 NPU 上做硬件加速 推理。
Fogwise® AIRbox Q900 是瑞莎推出的工业级嵌入式 AI 微型服务器,内置 Qualcomm Dragonwing IQ-9075 芯片,双核 Hexagon Tensor 处理器提供 50–100 INT8 TOPS 的 AI 算力,机身采用耐腐蚀铝合金材质,整体尺寸仅 104 × 84 × 52 mm,巴掌大小就能放下,支持 12V/5A DC 供电,可在工业温度范围稳定工作,定位就是面向边缘 AI 场景,可以长期部署、低功耗运行的小型计算设备,预装 Linux 系统,天生适合本地部署隐私优先的生成式 AI 模型。

先看效果:Q900 上生成的图片
下面这 6 张图就是直接用 Q900 的 NPU 推理生成的:

目前我们已经把这几个在 Civitai 上用户分享的热门 SD 1.5 底模完成了 QNN 移植:Q900
DreamShaper_8 epiCRealism_Natural_Sin_RC1_VAE majicMIX_realistic_v7 Lucky_Strike_Mix_Lovely_Lady_V1.05
比起原始 SD 1.5 checkpoint,这些社区底模审美更成熟,出片更稳定,细节也更丰富。比如同一个提示词:
8k, best quality, masterpiece, ultra highres, watercolor,a beautiful woman, shoulder, spaghetti straps, hair ribbons, by agnes cecile,half body portrait, extremely luminous bright design, pastel colors, ink,autumn lights
翻译成中文是: 8K 画质,水彩风格,一位穿细肩带的漂亮姑娘,发带,Agnes Cecile 画风,半身像,明快柔和的色彩,水墨感,秋日光线。
不同底模出来的光影、色彩、人物风格各有特色:

为什么这件事值得做?
之前 Stable Diffusion 这类模型一直跟大显卡、 高功耗、 工作站绑定。但生成式 AI 要真的落地到更多边缘场景,这几个问题绕不开:
能不能在小型设备上跑? 能不能长期稳定运行? 低功耗下能不能保持可接受的生成速度? 能不能支持大家真实在用的社区模型,不只是跑 demo 里的玩具模型?
性能:16W 整机功耗,5.5 秒出一张 512×512 图
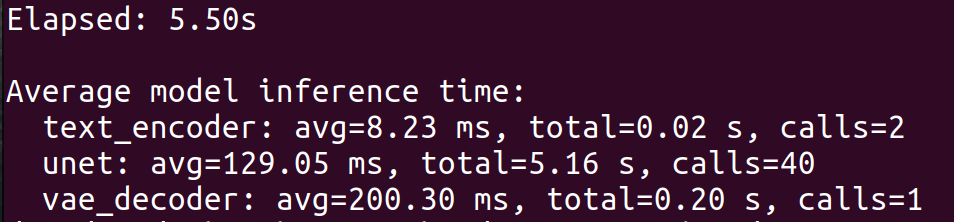
用 NPU 推理 SD 1.5 QNN 模型的时候,整机功耗大约是 16W。一张 512×512、20 步的图,平均生成时间大概 5.5 秒。 完整推理流程其实拆成了这几个部分:
两次 Text Encoder 推理:处理正向和反向提示词 四十次 UNet 推理:每一步分别跑无条件和条件分支 一次 VAE Decoder 推理:把 latent 解码成最终图片
算下来单张图的能耗:16 W × 5.5 s = 88 J / 张
也就是说,一张 20 步的 SD 1.5 图,整台机器才耗 88 焦耳,这个数字其实挺夸张的。

和 Q900 CPU 推理比:速度快 39 倍,能耗降 45 倍
我们也测了同一台机器用 CPU 推理的情况,同样是 512×512、20 步:
CPU 推理时间:215.1 秒 CPU 整机功耗:18.5 W 单张能耗:约 3979 J
对比 NPU 的数据:
速度提升:215.1 / 5.5 ≈ 39 倍 能耗降低:3979 / 88 ≈ 45 倍
NPU 不只是跑得快这么简单,单张图的能耗降了几十倍,这对边缘设备来说太重要了。偶尔跑一次,速度够就行;但要长期部署、批量生成、放在角落里没人管,能耗和稳定性才是关键。


和 x86 + RTX 4090 比:功耗不在一个量级
我们也拿 i9-14900KF + RTX 4090 的桌面主机做了对比。同样步数下,原始 SD 1.5 平均出图时间大概 1.3 秒,确实快很多,4090 还是桌面端的性能怪兽。 但从功耗看,GPU 满载的时候光显卡就差不多 372W,还没算 CPU、主板这些其他配件的功耗。
粗略算单张图能耗:372 W × 1.3 s ≈ 484 J / 张


Q900 NPU 整机才 88 J,对比一下:
RTX 4090 速度是 Q900 NPU 的 4.2 倍 但光显卡功耗就是 Q900 整机的 23 倍 单图能耗也大概是 Q900 NPU 的 5.5 倍
这里得说清楚,这个对比不是说 Q900 比 4090 强——两者定位完全不一样。4090 面向高性能桌面工作站,追求极致速度;Q900 是给低功耗边缘部署做的,要的就是能效、体积、能长期跑。 要是追求最快出图,桌面高端 GPU 肯定还是首选。但你要是想找个十几瓦功耗的小机器,蹲在角落里一直稳定跑文生图,那 Q900 这种 NPU 设备就非常合适。
技术干货:Stable Diffusion 是怎么移植到 NPU 上的?
Stable Diffusion 由一整条完整的生成 pipeline 组成。拿 SD 1.5 来说,推理主要分这几个模块:
Text Encoder:把提示词转成文本特征 UNet:每一步去噪都要预测噪声 VAE Decoder:把 latent 解码成 RGB 图 Scheduler:控制每一步去噪的步长和 latent 更新
传统 PyTorch / Diffusers 环境里,这些模块都靠 Python 框架统一调度,但直接把整个 pipeline 打成一张大图往 NPU 上塞不现实。我们的做法是把它们拆成多个 QNN 子模型: Text Encoder → UNet → VAE Decoder Scheduler、种子、提示词、分类器自由裁量权这些控制逻辑都留在 CPU 侧,这么做好处很多:
算力密集的模块都交给 NPU 跑 控制逻辑留在 CPU 方便调试,后续加功能也容易 每个子模型可以单独转换、校准、部署
最关键的改造:把 UNet 的 timestep 输入拆出来
这次移植最麻烦的技术点,是给 UNet 的 timestep 输入做了改造。 原始 Diffusers UNet 接收的输入是:sample + timestep + encoder_hidden_states,其中 timestep 就是当前去噪步,一般就是个标量。原版 UNet 会在模型内部把这个 timestep 转成 sinusoidal embedding,再经过 MLP 得到最终的时间步特征。 我们把这一步拆到了模型外面——也就是说,导出的 UNet 不再直接接收 timestep,而是直接吃我们预先算好的 1×1280 embedding。最终 UNet 的输入就变成了:sample + emb + encoder_hidden_states。 这么改主要有三个好处:
减少 UNet 图里的动态逻辑,降低 ONNX/QNN 转换的坑 避免 timestep 相关的小算子、shape 广播或者类型处理影响 NPU 执行稳定性 UNet 主体图更干净,更适合量化、编译,长期部署也更靠谱
完整转换链路
整个转换流程大概是这样:
PyTorch / Diffusers checkpoint↓拆分 Text Encoder / UNet / VAE Decoder↓UNet 外置 timestep embedding 计算↓导出 ONNX↓Qualcomm AI Runtime / QNN 工具链转换↓QNN context binary↓qai_appbuilder Python API 调用推理
代码和模型都开源了
现在在 Q900 运行 Stable Diffusion QNN 模型的代码和转换好的模型已经全部开源:
GitHub 仓库:https://github.com/ZIFENG278/qai-stable-diffusion 模型下载:https://modelscope.cn/collections/radxa/stable-diffusion-v1-5-v73-qnn
最后,如果你正好在找低功耗边缘部署 Stable Diffusion 的方案,欢迎拉取代码到 Fogwise® AIRbox Q900 上体验。同时如果你有想要转换的 Civitai 社区模型,或者自己训练的 Stable Diffusion 1.5 / 2.1 模型,也欢迎在 GitHub Issues 或者评论区里提出需求,我们一起把 Q900 的文生图生态做得更丰富。
点击下方原文链接跳转 Fogwise® AIRbox Q900 详情页