点击下方卡片,关注“具身智能之心”公众号
作者丨Hongyu Ding 等
编辑丨具身智能之心
本文只做学术分享,如有侵权,联系删文
>>
更多干货,欢迎加入国内首个具身智能全栈学习社区:(戳我),这里包含所有你想要的。
做具身导航,是否一定要训练一个 VLA 大模型? Uni-LaViRA 给出的答案是:不一定。
过去两年,这个方向的主流做法是把视觉-语言-动作(VLA)基础模型不断做大,用几百万到上千万条机器人轨迹、数千 GPU 小时训练,靠数据规模换泛化。南京大学、中科院自动化所等团队的最新工作 Uni-LaViRA 选择了另一条路:不训练任何参数,把导航拆成大模型本就擅长的三步翻译,零样本就在六大权威基准上取得免训练方法中的最好成绩,并在其中四个基准上反超了训练型 SOTA。仿真与真机代码均已开源。
论文标题:Uni-LaViRA: Language-Vision-Robot Actions Translation for Unified Embodied Navigation 作者:Hongyu Ding*, Sizhuo Zhang*, Ziming Xu*, Jinwen Guo, Hongxiu Liu, Xingzhi Cheng, Zixuan Chen, Haifei Qi, Duo Wang, Hao Xu, Jieqi Shi†, Yifan Zhang†, Jing Huo†, Jian Cheng, Yang Gao, Jiebo Luo 单位:南京大学,中科院自动化所,北京航空航天大学,宝马(南京)信息技术有限公司,美国罗切斯特大学 论文链接:https://arxiv.org/abs/2605.27582 项目主页:https://xetroubadour.github.io/Uni-LaViRA/ 开源代码(仿真 + 真机):https://github.com/NJU-R-L-Group-Embodied-Lab/uni-lavira-code

为什么导航或许不需要"专门训练"
具身导航如今分出四条主线——VLN-CE(连续环境指令导航)、ObjectNav(开放目标检索)、EQA(边走边答的具身问答)、Aerial-VLN(无人机三维导航)。任务形态不同,内核相通:看懂场景、理解指令、给出移动动作。
主流做法是训练一个大型 VLA 基座,靠规模堆出泛化。但这条路代价不小:训练数据两年里从不到 100 万条增长到 1600 万条以上,成功率才从不足 40% 提升到约 70%;而且模型与任务、硬件强绑定,换场景、换机器人往往要重新训练,长指令容易丢失中间目标,走错后也只能重试。对多数高校和实验室来说,门槛偏高。
Uni-LaViRA 的出发点是:日常导航本质上是"无接触"的空间移动——智能体不与物体发生复杂接触,只是在空间中穿行、做推理。这类动作的语义(往哪走、看哪个目标),正是预训练多模态大模型(MLLM)平时大量生成的内容。既然导航决策本就落在大模型的能力范围内,就不必再用机器人数据重新训练它;只要把任务结构拆解得当,现成的推理能力即可胜任。
把导航拆成三级"动作翻译"
Uni-LaViRA 把每一步决策拆成三级翻译,从"语义"逐级落到"坐标",每一级交给最合适的模型,全程没有任何需要训练的参数。
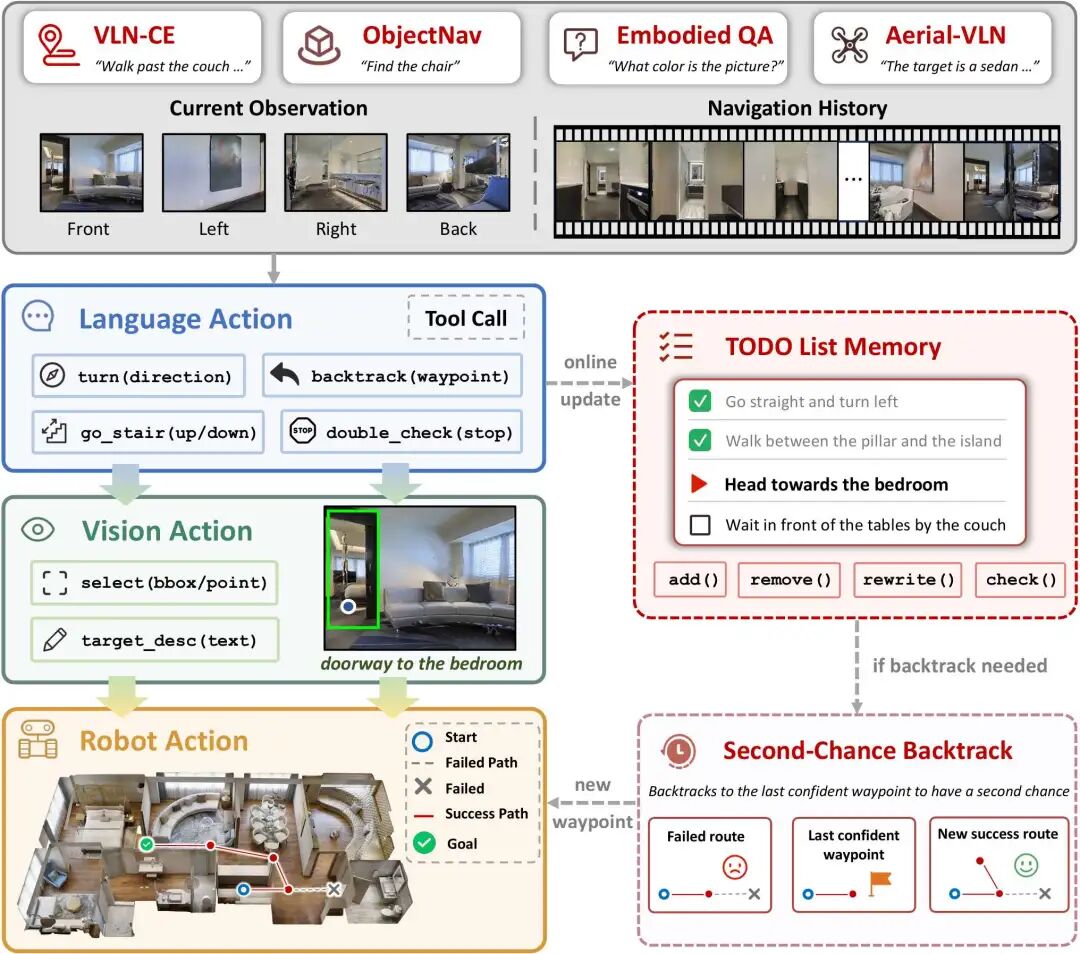
语言层(Gemini-3.1-Pro):读取指令、观察四周,输出"前/左/右/后转、回退、上下楼、是否停止"等高层决策,并维护整体规划,相当于系统的决策中枢。 视觉层(Qwen3.5-27B):根据方向,在第一视角图像中框出目标,给出边界框和一句描述。它直接在原始像素上定位,无需额外的预训练路点预测器,并天然支持开放词汇目标。 几何层(确定性控制器):把 2D 框结合深度和相机内参反算成 3D 坐标,地面用快速行进算法规划路径,无人机用体素网格与可视性图。这是框架中唯一与硬件相关的一层,换机器人只需替换它,上面两层保持不变。
两个关键机制:TDM 与 SCB
三级翻译解决了"怎么走",但长指令容易走偏、岔路容易选错。Uni-LaViRA 为此加了两个纯推理期、不引入训练的智能体循环:
TDM(待办清单记忆):把指令拆成一份"待办/已完成"清单,每步先回看、更新清单再决策,相当于不断把未完成的子目标提示给大模型。对 RxR 这类平均 120 词(约为 R2R 四倍)的长指令、以及无人机多阶段飞行,它能稳定地锚定全局目标。 SCB(二次机会回溯):走进死胡同时,不是简单后退重试,而是回到出错前的航点,并把失败的那段轨迹作为上下文交给大模型,让它先分析"上一步为什么错"再重新选择方向。错误由此成为有用的判断依据,而不是被直接丢弃。
两者相互独立:回退之后清单依然保留,可以协同工作。
实验结果:六个基准,零训练,四项反超
评测覆盖六大榜单:地面任务在 Habitat、无人机在 AirSim,包含 VLN-CE R2R/RxR、HM3D-v2、HM3D-OVON、MP3D-EQA、OpenUAV;均在 val-unseen 上抽取分层 100 子集、3 个种子取均值。骨干为 Gemini-3.1-Pro 与 Qwen3.5-27B,纯 API 推理、不做微调。
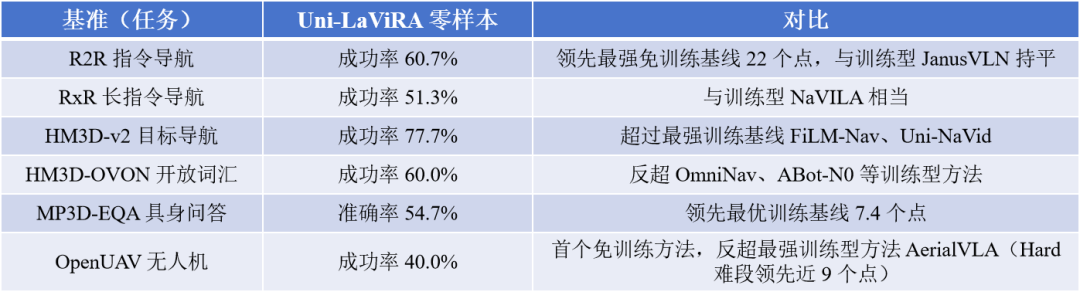
总体来看,Uni-LaViRA 在六个基准上都是表现最好的免训练方法,并在 HM3D-v2、HM3D-OVON、MP3D-EQA、OpenUAV 四项上超过了最强的训练型基础模型;仅在两个 VLN-CE 任务上,体量更大的多任务 VLA 仍保持领先。



消融实验显示两个机制缺一不可:全开与全关相比,六基准平均成功率从 48.6% 提升到 57.4%;其中 TDM 在长指令、远距离无人机任务上贡献更大,SCB 在室内多房间检索时更关键,二者互补。

对 1800 条轨迹的失败归因显示,前三类约占九成:误判目标提前停止 45.8%、到达后未触发停止 24.7%、问答细节识别错误 19.5%,这也是后续改进的重点。

下面是六大基准的决策轨迹示例:

成本:从训练开销转为推理开销
成本是 Uni-LaViRA 的一个突出优势。一个 NavFoM 量级的训练型基座,需要 56 张 H100 连续运行约 72 小时才能训出;Uni-LaViRA 没有前置训练,只有按调用计的推理开销。训练样本上差距更明显:训练型方法从 0.95M 增长到近 1700 万条,而它是 0 条、0 GPU 小时。一套大模型 API,普通实验室即可开展研究。

真机部署:四台机器人,共用一套上层模型
团队进一步把同一套框架部署到四款形态不同的真机上,覆盖室内办公、室外走廊与野外空地:


零适配是这里的关键:三台地面机器人的语言、视觉骨干完全复用,换机器人只需替换最底层的控制器与推理目标,上面两层不做改动。工程成本也较低:新增一台机器人约需 2 小时传感器标定加 4–6 小时控制器适配,四台合计约 40 人时,远低于"每台机器人单独训练一个 VLA"的数百 GPU 小时。
总结与展望
Uni-LaViRA 提出的,是一条以结构换数据的思路:三级动作翻译加 TDM、SCB 两个推理期机制,在不训练、不预建地图、自由指令输入的前提下,实现跨任务、跨机器人的即插即用,仿真上达到甚至超过多数训练型基座,真机上落地四类机器人。
论文也坦率列出了几点局限:
最强骨干(如 Gemini-3.1-Pro)仍是闭源,开源替代尚有差距,计划将闭源模型的推理轨迹蒸馏到开源骨干,实现全栈私有化; 大范围场景中"走廊"这类大目标的全局定位仍不够稳定,计划在置信度低时让视觉层调用 SAM、Grounding DINO 辅助; 上百词的超长指令仍略逊于定制训练的 VLA,计划为 TDM 增加层级子目标压缩并使用更长上下文的骨干; 动态行人与障碍目前只靠底层被动避障,后续计划把行人意图推理引入语言层,实现社交导航。
推荐阅读 :