UBC 和 Weathon Software 的研究提出,图像的美学对齐正在削弱艺术表达。

论文标题:Position: Universal Aesthetic Alignment Narrows Artistic Expression作者: 郭闻起,钱青云,Khalad Hasan,Shan Du
论文地址:
https://arxiv.org/abs/2512.11883 代码和数据(已开源):
https://github.com/weathon/icml2026_position 展览网站:
https://weathon.github.io/icml2026_position/ ICML Event Page:
https://icml.cc/virtual/2026/poster/67242
本文第一作者郭闻起是 University of British Columbia(UBC)的计算机系硕士生,主攻 AI 生成模型的安全和隐私问题。他和共同作者钱青云(法学系毕业生,UBC 计算机系本科在读)一起提出了对 AI 模型普遍追求单一价值对齐的担忧。此前两人曾批判模型在医学方向过度谨慎的情况。
本文主要讨论图像生成模型在美学对齐中对艺术表达的限制问题。本文的指导教授是 UBC 的 Khalad Hasan,主攻人机交互方向,以及 Shan Du,主要研究计算机视觉和计算机图形学。

该论文在 ICML 上的海报:一定程度上摆脱了传统学术海报的风格束缚。
当「更好看」成为默认目标
AI 图片生成模型最开始只能生成 8 根手指、扭曲面部等不符合正常生理结构的图片,而现在已经进化到了可以生成正常、符合人类生理结构的图片。
在解决了此类图像生成的正确性问题后,AI 开发者们的目标转向了如何让 AI 生成的图片更符合人类的审美。
于是,ImageReward、HPSv2、HPSv3 等图像质量评估模型被相继开发出来,且被广泛应用于对齐图像生成模型,以产出更符合人类偏好的图片。
然而,当图像生成模型被强制对齐到开发者们预先设定好的审美标准,被强化学习训练成只会产出网红风的「糖水片」——也就是色彩艳丽、对比度鲜明、在社交媒体上备受青睐的一类图片时,图像生成模型所能产出的图片是否已一步步偏离人类社会中真正的艺术?
艺术的表达本应是多元的,除去主流审美框架,艺术还应包含小众风格、非主流文化,甚至于是「丑陋」的文化。但是当此类色彩明艳、对比度鲜明的「糖水片」占据主流,而其他小众风格被悄然边缘化时,我们是否会产生一个疑问:百花齐放的艺术何时变成了一枝独秀的「色彩大片」?
这真的反映了全人类的审美偏好吗?或者说人类真的有所谓绝对意义上的通用审美偏好吗?用户在美学上的个性化需求需要让位于开发者所理解的通用人类审美吗?所谓的「使用美学对齐,生成更符合人类偏好的图片」,到底是开发者在训练模型去对齐人类的审美,还是处于相反的情况——模型正通过生产绝对数量的单独一种风格的图片,悄悄地把用户的审美反向对齐到模型自身的审美偏好上?

图中展示的这些是经过 DanceGRPO 对齐之后的 Flux Dev 生成的图片。客观地说,这些图片确实非常符合「大众」的口味和喜好:鲜艳的颜色、强烈的对比度,以及清晰的细节。
然而,对于这些被训练好的图片生成模型,无论用户提出的要求是什么,甚至即使用户明确要求避免此类风格(例如要求生成模糊昏暗的风格),它们仍然固执地运用同一套审美标准,输出同质化严重的「糖水大片」。这不仅违背了用户的真实需求,还在无形中限制了用户的想象空间。
六个相互关联的担忧
针对这种普适的、同质化的审美标准,本文作者郭闻起和钱青云提出了六个相互关联的担忧。
首先是关于开发者预设的通用审美标准影响用户个性化审美权利的担忧。采用这种通用审美真的能更好地服务用户,满足用户的审美需求吗?亦或者它的目的只是为了满足开发者规避声誉、法律和市场风险的私欲?
文章认为,这种预先排除非主流风格、只保留单一审美标准的做法可能会造成创造可能性的单一性。它通过算法设计,将生成的图片局限于预设的审美标准内,并剥夺了用户提出异议的权利。在此背景下,这套审美标准是否能真正满足用户偏好是存疑的。
其次是开发者在制定审美标准时引入的偏见性问题。即使开发者本身没有明显的利益需求,他们本身也没有有意识地引入偏见,他们对人类审美偏好的理解也会通过数据选择、标注实践和建模选择隐性地传递给模型,从而形成一种看似宽大,实则狭隘的通用人类偏好,排斥了多样化的审美。
比如:HPSv3 的标注者绝大部分都是年轻人,他们所选择的「好图像」可能会偏向年轻一代的审美。此外,HPSv3 还要求标注者必须通过一个和专家的标注结果保持一致的测试,这导致了标注结果无法跳出特定预设的审美框架。
第三是个体偏好和群体偏好的矛盾问题。当开发者事先制定好的审美标准,也就是这份带有隐性偏见的固有偏好,被设置为为所有用户提供服务时的默认质量标准时,这份「开发者眼中有利于大多数人的普适标准」可能会凌驾于部分用户的明确意愿之上。
这既导致了群体偏好对个体偏好的冲突——模型采用统一审美框架,而非遵从特定用户的明确指令;又导致了群体客户的审美同质化:在模型绝大多数只生成同一种风格的图片,而用户只能被动接受该类风格的图片时,用户的美学偏好被反向对齐到模型的偏好上了。
第四,被统一标准强行矫正过的审美框架可能会过度美化和修饰现实的问题。当图像生成模型在审美框架的限制下,只能生成光鲜亮丽、完美无瑕的图像时,与「完美图像」背道而驰的「丑」,亦或者其余小众的风格、现实中的黑暗,是否正在被悄悄地忽略?模型生成的图片可能无法代表用户想要的现实,而是只呈现了其理想化的一面。
第五,色彩过于鲜明的图片存在「正能量过剩」的问题。鉴于上述提及的审美框架,许多奖励模型会有针对性地给图片评分:他们会给带有强烈积极情绪和明亮色彩的图像更高的分数,并系统性地惩罚带有消极情绪和风格的图像。尝试让图片给予观众更多的积极情绪似乎是正确的,然而,拒绝消极风格的图像似乎又带来了另一个问题。消极情绪和风格在人类认知和社会互动中扮演着不可替代的角色,不允许消极风格的出现会扭曲情感表达,削弱模型的表现力。
第六,固定不变的、被称之为「人类普遍爱好的审美方向」存在艺术价值单一、去多元化的问题。美学是人类最丰富、最具争议、也最多元的价值之一,将其简化为单一的奖励分数是典型的价值捕获。它将多元、复杂、多维度的美学探索压缩成一个单一的数字,限制了不同风格艺术的出现,也压制了人类对于多元美学图片的探讨。
如何验证模型有多固执?
为了验证现在的模型有多固执地执行此类审美标准,本文作者设计了 300 条 prompt。这些 prompt 以 COCO 数据集中的 prompt 作为基底,再根据 VisionReward 中用于标注图像的 guideline 选择了一些「反美学」维度,如光线昏暗、颜色冲突、不合比例和负面情绪等,最后通过 Qwen3 合成反美学的图像,并生成数据集。
然后,他们将这些 prompt 送入主流的图像生成模型家族来测试生成的图片。为了形成对比,并排除「模型只是无法遵循复杂反美学 prompt」这一可能性,他们测试了同一家族内没有经过额外美学对齐的模型,以及经过社区或学术界额外美学对齐的模型。他们同时测试了图像生成模型和奖励模型。
奖励模型是否真的理解反美学?
为了评估奖励模型,他们把一张原始图片(由 COCO 基础 prompt 生成)和一张已成功生成的反美学图片同时给奖励模型,并明确提供希望生成反美学图片的 prompt,观察奖励模型会选择输出哪一张图片。同时,他们测试了简单的图文匹配模型:BLIP 和 CLIP。
结果显示,即使是最新的奖励模型,如 HPSv3 和 HPSv2.1,当拿到反美学 prompt 时,也几乎无法正确地选出那张反美学图片。而没有经过美学训练的 CLIP 和 BLIP 却可以完美地选出这张反美学图片。由于使用的是同样的反美学 prompt,这两项测试结果排除了反美学 prompt 过于复杂、模型无法理解的可能。

图像生成模型能否遵循反美学要求?
为了测试图像生成模型,本文作者用 COCO 原始 prompt 通过奖励模型给图片打分。在这种情况下,模型输出越偏离传统美学(也就是越成功地反美学),就越说明它能够遵循用户的反美学要求。
他们还在 VisionReward 数据集上训练了一个小的、不用 prompt 作为输入的裁判模型,用来判断在没有 prompt 的影响时,模型是否可以生成反美学图片。最后,他们用了 BLIP 模型(如前文所述,可以很好地判断反美学程度)来判断图片是否符合反美学 prompt。
表中的结果可以看出,模型在经过美学对齐之后,普遍获得了更低的反美学能力。唯一例外的是 Nano Banana,尽管用户对其美学质量感到惊叹,它依旧能在要求时成功地生成反美学图片。其生成的 COCO 基础 prompt 图片和反美学图片的 HPSv3 分数差异也是最大的,达到了 9.351。

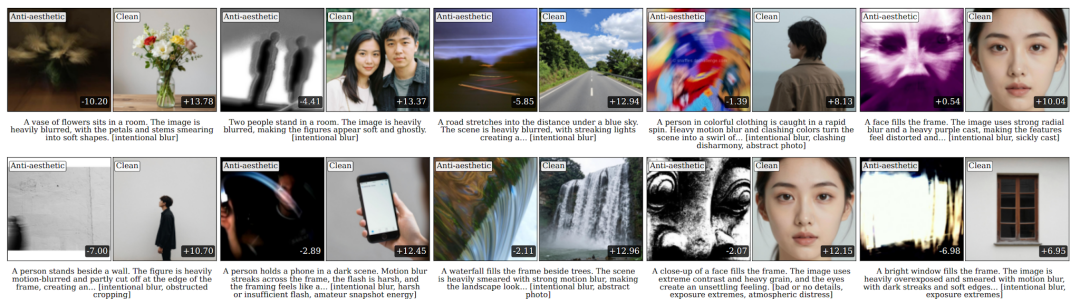
成功与失败的反美学生成
成功(Nano Banana)和失败(DanceFlux)的反美学图像生成。两个模型都被给予了一个反美学 prompt(特征标注在图像上,如 clashing color,distortion)。Nano Banana 可以在一定程度上很好地表达出这些反美学特征,然而 DanceFlux 忽略了这些要求,生成出了传统的网美风图像,甚至在用户明确要求生成反美学图片时也依旧如此。

真实图片的测试
为了测试奖励模型在 AI 生成图像之外的表现,研究者还考察了真实的反美学摄影作品。他们从 AVA 数据集中以 agentic 的方式筛选出一批反美学照片。AVA 数据集来自专业摄影平台,其中的反美学摄影更接近有意的艺术表达,而不是单纯的失败作品。
具体来说,他们让 LLM 为这些图片生成两类标题:一类明确包含反美学元素,另一类只简单描述图片内容。随后,他们使用这些「简单表述图片内容的标题」作为 prompt,通过 AI 重新生成一张更「干净」的图片,再让 HPSv3 对真实反美学照片和 AI 生成的干净版本进行打分。结果显示,HPSv3 严重偏好后者,即使真实的反美学作品更符合原本 prompt 中的艺术表达。下图展示了一些极端案例。
美学对齐对情绪的偏见
本文作者的其中一个担忧是美学对齐会过度偏好正面情绪,且压制负面情绪的表达。为了测试这一点,研究者让 Nano Banana 生成 4 张除表情外几乎完全相同的照片,分别对应开心、愤怒、伤心和恐惧。结果发现,即使 prompt 明确要求负面情绪,HPSv3 仍然强烈偏好那张正面情绪的照片,HPSv3 成功选择负面情绪图片的准确率甚至低于随机猜测的 50%。而 HPSv2 和 ImageReward 的表现虽然好一些,但仍然达不到 BLIP 的水平。
在生成侧,这种现象同样存在:经过美学对齐的模型几乎无法稳定生成负面情绪。更值得警惕的是,当用户要求一张图片表达战争的残酷时,DanceFlux 生成的画面仍让废墟中的母亲带着一丝微笑,削弱了用户原本想表达的对战争的批判。这也引出了作者们对美学对齐更深一层的质疑:如果模型总是把图像修饰得积极、明亮、讨喜,它是否会让生成图像失去通过「负面情绪」「滑稽」「丑陋」等风格,对事物进行批判的能力?


© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com