
主讲人:袁粒
智猩猩整理
编辑:六六
过去十年,我们几乎默认接受了一条简单的规律:数据越多,模型越强。这种“规模即能力”的信念,推动了深度学习一路从图像识别走向大语言模型,也塑造了今天生成式AI的基本形态。
但问题也在这里慢慢显现——当模型越来越“聪明地说话”,它是否真的更接近“理解世界”?
在2026中国生成式AI大会(北京站)上,一个看似抽象的问题被推向具体的技术分岔口:当下AI体系究竟在逼近世界本质,还是仅困于语言投影?北京大学深圳研究生院助理教授、博士生导师袁粒,以《多模态大模型走向原生统一:前景与挑战》为题,给出了他的系统性思考。
同样是一张“双手多指”的图像,语言模型GPT-5在“生成”上表现惊艳,却可能在“理解”上出错——例如数不清手指;而另一类多模态系统Gemini却能够给出正确答案。
差异并不在“模型更大或更小”,而在于它们理解世界的方式本身就不一样。
由此他提出了一个更直接的判断:今天以语言为中心的模型体系,本质上仍然是在“用语言理解世界”,而不是在“用世界理解世界”。
由此,他提出两个在报告中非常关键的判断。
首先,LLM已经逼近阶段性极限,而多模态原生统一才是未来方向。在他看来,智能体(Agent)更多是当前工程层面的主线,但真正决定下一代AI上限的,并不是工具链如何编排,而是多模态是否能够走向“原生统一”。
其次,他明确强调一个容易被误读的观点:“Pre-train结束”的判断,只成立于LLM。当我们把视角从语言扩展到多模态之后,一个更本质的事实是——多模态原生模型的大规模预训练阶段,甚至可以说“尚未真正开始”。这意味着,我们今天所处的位置,可能并不是某个技术周期的尾声,而是一个新范式的起点。
在这一逻辑下,“原生统一”不再是一个工程优化问题,而更像是一种架构层面的重新定义:All Modalities are Equal。
如果多模态原生统一无法实现,那么所谓“世界模型”,可能也只是一个更复杂的单模态模型集合,而不是对现实世界的真正抽象。
但问题也随之而来。统一听起来很理想,现实却很困难:不同模态的数据结构不同、训练目标不同、编码方式不同,甚至连“理解”和“生成”本身都存在方法论冲突。再叠加数据稀缺和标注成本,这条路显然远没有看上去那么顺滑。
如果说过去的AI进步依赖的是“把数据喂进去”,那么下一阶段更像是在追问:这些数据是否真的被放进了同一个“世界模型”里。
这也让一个更根本的问题浮现出来:当我们继续扩大数据规模时,我们到底是在更接近“智能”,还是只是让一个语言系统变得更会解释世界?
答案或许还没有定论,但方向已经开始变化——AI的竞争,正在从“谁能学得更多知识”,转向“谁能学得更像一个多模态世界”。
01
“我无法创造的,我便无法理解”
在这个报告之前,我先给大家一个很简单的例子。这两个手都是有六根手指,大家知道这是AI生成的。让模型去生成这张照片很容易,但是我让GPT-5去理解,我去问它图中每只手有几只手指?他的回答是五只手指。我把同样这张照片放给Gemini,大家会发现Gemini就能数对。

为什么GPT5能做对大部分竞赛难度的数学题,在这个大部分小学生都能做对的数手指任务上失败了?Richerd Feynman说过一句话“What I can not create,I do not understand”(我无法创造/生成的,我便无法理解)。
回到这个问题,会发现我们的大模型的创造性。六根手指的照片大模型创造出来了,但是它没有理解到。
但是为什么Gemini能理解到?其实背后是架构的问题,而这个架构就是多模态统一。Gemini架构虽然中间也是Transformer,但是它的一个核心是要把不同的模态融合在同一个框架里面,同时再输出出去。
所以以语言为中心的架构,或者甚至是说把token翻译成词元这种偏见的架构是无法真正的让大模型走向physical AI(物理AI)。
02
AI下半场真正的决胜:多模态原生统一
1.LLM它本身已经逼近于极限了,而多模态才是未来
当然今天的主场其实大家讨论很多是智能体,所以这句话我应该说是LLM是过去已经逼近极限,智能体是现在,但多模态统一是未来。

我认为,AI下半场真正的决胜,甚至未来5到10年决定“物理AI”能否真正实现的关键,在于多模态。
现在有大量不同的多模态模型,不同架构和功能,没有统一。大家可能会问,一定要统一吗?统一难道就一定那么重要吗?用智能体架构调度不同的模型去完成不同的任务不就行了吗?

其核心问题在哪里?举例来说,很多具身大模型也不是一个模型,都是多个模型。我认为这种范式可能在虚拟的这个数字世界可以,但是到物理世界里面必然存在很大的问题。
第一个问题是速度慢,高延迟。在线上一个文档或者PPT不要求实时性,但是真正落地到物理空间里做实事的时候,实时性要求很高的。因为有多个模型,不同的模型都是大模型,每一个大模型作为其中一个环节都很耗时,用Agent的方式把它串在一起,那几乎不可能做到实时。

World Model实际上是来自于心理学的一个概念。我们人在大脑里构建出了一个世界模型,然后我们在这个世界里面去执行的时候,我们会在我们的World Model大脑里面先思考一下。人类的World Model肯定是多模态原生统一的,而不是割裂的语言模型或者说视觉模型。
03
多模态原生统一的挑战与瓶颈
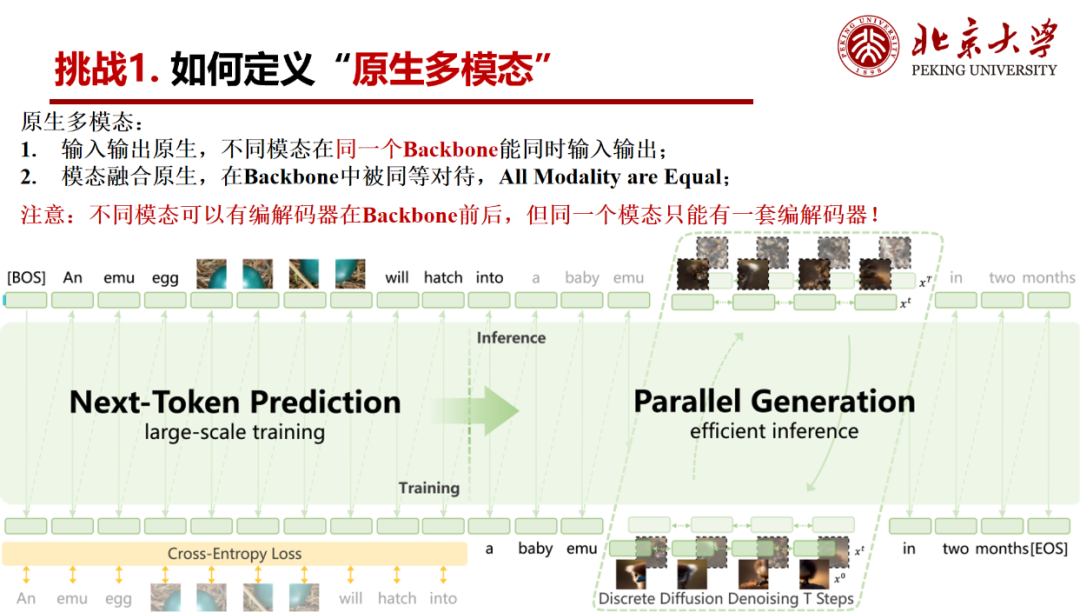
2.技术架构
扩散和自回归这两种多模态理解和生成的建模其实很难融合在一起。理解的建模其实更多的是next token prediction,这种范式实际上是自回归的因果建模;而diffusion建模是结构建模。

人其实是既需要因果又需要结构的。但是目前大家很难把这两种建模方式融合在以同一个backbone里面。
3.视觉的编码器没有统一

如果大家做多模态的会发现,在多模态理解里面用的编码器是CLIP以及它的变体,而在生成里面会用VAE和它的变体。CLIP是用来和语义对齐,VAE是在做压缩。也就是说视觉模态的编码器仍然没有被统一。
生成编码器是会保留low level的像素信息,而理解编码器是需要保留high level的语义信息。而同一个模态两套编码器会造成信息保留不一致,甚至有理解生成任务的冲突。也就造成了理解很难促成生成,而生成也很难辅助理解。
4.模态冲突
在原生多模态架构中,不同模态被统一融合到同一个backbone之后,会产生一个非常核心的问题——模态冲突(model conflict)。

5.数据挑战
我认为数据的挑战远远大于前面的架构的挑战,它需要整个业界去采集的是多种模态配对的数据,且这种多模态的scaling law目前仍然没有被探索。

04
课题组代表性工作:
多模态理解、生成和统一

第一个是原生实时视频生成架构 Helios。这个架构中,我们没有依赖类似KV cache加速技巧,而是从架构层面原生支持视频的实时生成能力。
整体方法采用的是Autoregressive + Diffusion的统一建模范式,也就是 Autoregressive Video Diffusion Transformer。


也就是说理解和生成统一之后,一个很核心的一个点就是大家会发现它会更符合你的需求和真正对物理世界的理解。
最后总结:

谢谢大家。
END
✦
✦
2026中国AI智能体大会
✦
智猩猩主办的2026中国AI智能体大会7月2-3日杭州举行,大会设有开幕式,企业级AI智能体、AI智能体产品创新2场论坛,以及Coding Agent、自进化智能体、深度研究智能体、Computer-Use Agent、多智能体协同、Agent Skills、Agent Harness7场技术研讨会。最终议程已公布。










✦
✦
入群申请
✦

点击下方名片 即刻关注我们










