vivo BlueImage Lab团队 投稿
量子位 | 公众号 QbitAI
AI学会新本领,就很容易忘掉之前学过的知识。
这就是困扰业界很久的「灾难性遗忘(Catastrophic Forgetting)」难题。
想让多模态大语言模型(MLLM)具备持续学习(Continual Learning) 的能力,过去往往要留存海量历史数据,既耗算力,又有隐私泄露风险。
现在,上海交通大学与vivo团队拿出了全新解法:一种全新的持续学习框架——Octopus。
该方法首创无需历史数据的梯度正交化(History-Free Gradient Orthogonalization,HiFGO)技术。模型无需获取任何历史任务数据,即可精准捕捉不干扰旧知识的“安全更新方向”,精准刻画并规避任务间的参数干扰。
实验表明,在权威的多模态增量学习基准UCIT上,Octopus的平均性能(Avg)和最终性能(Last)分别超越此前SOTA方法2.14%和6.82%,并且在不依赖旧数据的情况下罕见地实现了“正向后向迁移(Positive Backward Transfer)”。目前,该论文已被计算机视觉顶级会议CVPR 2026接收。

背景:大模型的“灾难性遗忘”困境
近年来,多模态大模型(MLLM)在各项任务中展现出卓越的性能。但在实际业务部署中,模型需要像人类一样进行“终身学习”——不断掌握新技能并适应新数据分布。
然而,当大模型在新数据上进行微调时,参数的更新往往会不可逆地抹除模型先前学到的旧知识,引发“灾难性遗忘”。
目前主流的MLLM持续学习方法存在难以逾越的瓶颈:
基于架构的方法(Architecture-based):为每个任务分配特定的LoRA模块以存储任务专属信息。虽然能缓解遗忘,但会割裂任务间的知识共享,削弱模型对未知任务的泛化能力,并降低推理阶段的计算效率。 基于重放的方法(Rehearsal-based):通过维护记忆模块存储历史任务信息。但在实际应用(尤其在端侧设备)中,历史数据往往涉及隐私或不可获取;同时,维护经验回放缓冲区也会带来额外的存储开销。 基于正则化的方法(Regularization-based):通过添加约束项限制参数更新的范围。然而前沿研究表明,现有方法所依赖的“参数空间正交”并不足以完全防止知识干扰,且难以在“学习新知识(可塑性)”和“保留旧知识(稳定性)”间找到最佳平衡。
这引出了一个核心问题:是否存在一种方法,既不需要访问历史数据,也不增加推理阶段的参数负担,同时还能高效保留模型的旧知识?
Octopus的核心洞悉正源于此:仅在参数层面进行正交约束是局限的,梯度层面的正交才是避免参数冲突的关键。更重要的是,研究团队证明了在缺乏旧数据的情况下,依然可以推导出这一“安全更新方向”。
核心机制:Octopus框架的关键创新
为实现上述目标,Octopus框架引入了两项核心创新设计:HiFGO约束与两阶段微调策略,在可塑性与稳定性之间构建了精妙的平衡。

△多模态大模型持续学习的整体流程(左)与本文所提Octopus框架的结构(右)
无需历史数据的梯度正交化(HiFGO)
研究团队在理论层面指出,遗忘的本质新旧任务在优化流形(Optimization Manifold)上的梯度方向冲突。为保护旧知识,新任务的更新方向应与旧任务的“关键梯度空间”严格保持正交。
最大的挑战在于:如何在不使用旧数据的情况下,计算出旧任务的敏感梯度?为此,研究团队提出使用GPWC(Gradients of Previous parameters Within Current data distribution) 作为旧任务敏感梯度方向的合理代理(Proxy)。
该机制创造性地利用“历史任务的模型参数”在“当前新任务数据”上进行梯度计算,从而高效近似旧任务的关键梯度方向。
GPWC的有效性建立在坚实的理论基础之上:研究证明,GPWC等价于旧任务Hessian矩阵在新任务数据流形切向空间上的投影。
换言之,Octopus成功提取了“新任务数据分布下旧任务的敏感方向”,从而在训练中实现了参数更新的高效解耦。
研究团队通过两任务序列微调测试验证了GPWC的有效性。结果显示,传统无约束微调会导致前一个任务的性能遭遇断崖式下跌;而在引入基于GPWC的HiFGO约束后,前一个任务的性能得到了有效提升,几乎恢复到了单一任务独立训练的理想水平。
下图为基于GPWC的HiFGO约束的有效性验证。结果展示了单任务微调、双任务顺序微调,以及在顺序微调后加入HiFGO约束进行微调的性能(数值越高越好)。

Hessian矩阵二次型分析进一步证实:相比标准序列微调,GPWC约束下的参数增量在旧任务Hessian上的二次型显著更小。这意味着Octopus能够成功引导模型避开旧知识的“高曲率区域”,从最底层的几何优化机制上锁定了旧记忆。
下图为Seq.FT与本文方法在两个任务上的Hessian二次型对比。

两阶段微调策略(Two-Stage Finetuning)
在序列学习中直接引入正交约束,往往会限制模型吸收新知识的能力(即“可塑性”下降)。受优化理论启发,Octopus提出了一种两阶段解耦微调策略:
第一阶段(充分学习):模型在无约束状态下,于新任务数据上自由微调,充分学习新知识,迅速逼近局部最优; 第二阶段(约束巩固):引入HiFGO约束进行第二轮微调。此阶段旨在利用正交约束,将参数“拉回”到一个既能维持新任务高性能、又与旧知识不冲突的安全流形区域。
这种“先适应、后巩固”的策略显著提升了正则化方法的性能上限。

△Octopus算法流程
实验验证:全面刷新多模态持续学习SOTA
研究团队在多模态持续学习权威基准UCIT上进行了严格的评估。该基准包含图像描述、视觉问答、数学推理等6个分布迥异的连续任务。
全面超越基线,突破正则化方法瓶颈
Octopus在实验中展现出显著的性能优势:
综合能力领先:相比此前的最优方法(如O-LoRA,HiDe-LLaVA),Octopus在平均性能(Avg)和最终性能(Last)上分别达到71.08%和71.01%,显著领跑基线模型。 逼近理论上限:在ArXivQA、CLEVR-Math等任务中,Octopus的表现比肩甚至超越了通常被视为理论上限的“全数据联合训练(Multi-task)”。 超越数据回放方法:作为一个无回放(Rehearsal-free)的正则化方法,Octopus的表现甚至优于依赖真实历史数据的重放方法(Vanilla Rehearsal),证明了其参数空间解耦的高效性。

△在UCIT数据集上,本文方法与多种对比方法在Avg和Last指标上的对比
罕见的正向后向迁移(Positive Backward Transfer)
对抗遗忘通常是“止损”,而Octopus不仅有效抑制了负向迁移,还成功实现了正向后向迁移(BWT=+0.41)。作为对比,传统的参数正交约束会导致BWT下跌至-2.51。这表明得益于高质量的梯度解耦,Octopus能够从新任务中提取并反哺旧任务的通用表示,真正实现了“温故而知新”。
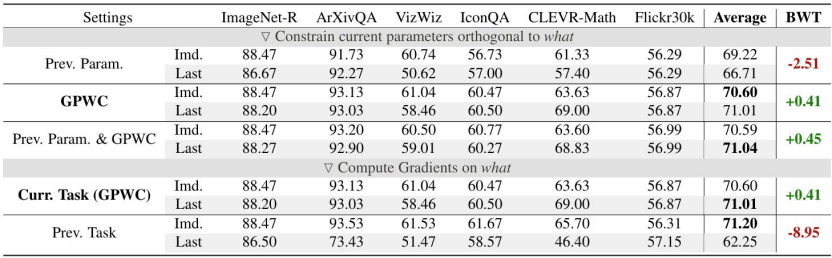
△不同正交方法的性能对比
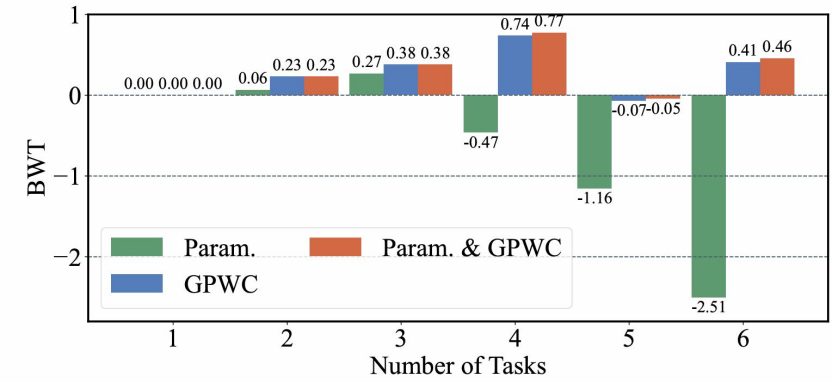
△采用不同正交化方法对模型在每个任务上微调后的反向迁移性能(BTW)
卓越的鲁棒性与泛化能力
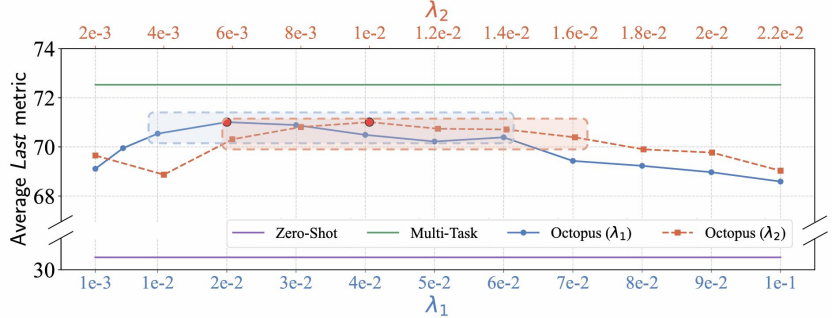
超参数稳定性:敏感性分析表明,在较宽泛的超参数区间内(如  ),模型核心指标未出现显著衰减。这极大降低了实际业务部署中的调参成本。
),模型核心指标未出现显著衰减。这极大降低了实际业务部署中的调参成本。
任务顺序鲁棒性:在面对非平稳数据流时(即使多次随机重排任务序列),Octopus的最终性能均表现出高度一致性。这种优异的“顺序免疫”特性,从经验层面证实了HiFGO能够从容应对未知数据流的冲击。

△UCIT基准测试中不同任务顺序下的实验结果

△不同任务顺序下,在每个任务微调后的平均性能
高效的推理与部署
在推理阶段,相较于基于专家路由(MoE)的方法需要随任务增加加载冗余参数,Octopus始终维持单一的LoRA模块,实现了零额外推理开销,极其适合端侧或资源受限场景下的大模型部署。

△推理阶段所需额外参数量的对比
Octopus框架通过其创新的无需历史数据的梯度正交化(HiFGO)约束和两阶段微调策略,为多模态大模型的持续学习问题提供了一个高效、安全且性能卓越的解决方案。它证明了,在保护隐私(无需历史数据)和控制模型规模(无需动态扩容)的前提下,我们依然能够构建出“过目不忘”的智能系统。
更重要的是,它为大模型在真实世界中的部署和持续迭代提供了技术支撑——在数据隐私日益重要的今天,一个无需访问历史数据的终身学习系统,无疑拥有更广阔的应用前景。
论文链接:https://arxiv.org/pdf/2605.14938
论文主页:https://fxmangd26.github.io/Octopus/
代码链接:https://github.com/Fxmangd/Octopus
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
【学术投稿】请在工作日发送邮件至:ai@qbitai.com,标题注明【投稿】,并告诉我们:你是谁,从哪来,投稿内容附上项目/主页链接,以及联系方式。
🌟 点亮星标 🌟










