点击下方卡片,关注“具身智能之心”公众号
折毛巾时,物理世界不会停下来等待机器人思考。
布料会滑动,褶皱会改变,前一秒还合适的抓取点,下一秒可能已经偏离。真实机器人做动态操作时,“想象未来”不能停留在离线视频生成里。它必须进入控制回路,在动作还来得及调整时,给策略一个可用的未来线索。
一个直接的想法,是让模型先生成未来画面,再让机器人根据这些画面行动。但对控制系统来说,有用的未来不一定是一段完整视频。机器人真正需要的是一个能被动作策略立刻读取的未来子目标。这个子目标应当保留物体将如何移动、接触区域将在哪里、当前动作会把场景推向什么状态,同时省掉纹理、光照和背景这些对控制帮助有限的细节。
围绕这个问题,清华大学团队与正行创新(Striding AI)联合提出了隐空间世界动作模型(Latent World Action Model, LaWAM)。这是一种更适合实时控制的世界动作模型(World-Action Model, WAM)。它绕开未来视频生成,在视觉隐空间中预测动作相关的未来子目标,再把这个隐空间视觉子目标(latent visual subgoal)交给动作生成策略使用。
这样做带来的低延迟很重要,但它只是结果之一。更值得关注的是,隐空间让三件事有了共同的表达方式。人类动作中蕴含的意图、场景随动作变化的规律,以及机器人最终要执行的控制动作,都可以先在这个更紧凑的空间中对齐。换句话说,LaWAM 试图把人类和机器人视频中的视觉转移,变成当前策略可执行的未来子目标。
这也契合正行创新正在推进的技术方向。要把物理智能做成可闭环、可部署的机器人系统,模型需要理解任务意图,学习动作如何改变世界,并在真实反馈中持续改进。LaWAM 对应其中的预训练和基座模型架构问题,是这条技术路线中的一个关键尝试,核心是从人类和机器人视频中的视觉转移里学习物体受动作影响后的变化规律,以及可迁移的隐动作表征,再把这些规律和表征变成当前策略可执行的未来子目标。

论文题目为 LaWAM: Latent World Action Models for Efficient Dynamics-Aware Robot Policies。作者来自清华大学、正行创新等机构。
如果想进一步查看论文原文、实验可视化、代码和模型权重,可以从以下资源进入。
论文链接: https://arxiv.org/abs/2606.15768
项目主页: https://rlinf.github.io/LaWAM/
代码仓库: https://github.com/RLinf/LaWAM
Hugging Face 模型合集: https://huggingface.co/collections/jialei02/lawam-checkpoints
这段折毛巾对比展示了延迟的代价。高延迟的未来生成会让机器人基于过时的布料状态行动。LaWAM 把未来压缩成策略可直接使用的隐空间子目标,因此能更快进入下一段动作。
01.
机器人需要可行动的未来
像素空间 WAM 的路线很直观。模型先生成未来图像或视频,再让策略根据这些画面输出动作。人容易看懂这种未来,但机器人真正用来控制动作的信息,往往只占其中一小部分。
对动作系统来说,关键问题更具体。毛巾下一步会折到哪里,抽屉把手会沿哪个方向移动,夹爪应该靠近哪个区域。这些信息主要存在于空间结构、物体状态和交互区域中。背景纹理是否重建得细腻,光照是否逼真,对下一段动作的帮助有限。
LaWAM 因此把未来预测整体迁移到视觉隐空间。系统直接预测动作相关的未来特征,形成一个专门交由动作专家解析的隐空间视觉子目标。它像一张面向策略的“未来动作提示图”,保留空间结构和交互区域,同时避免逐像素重建。
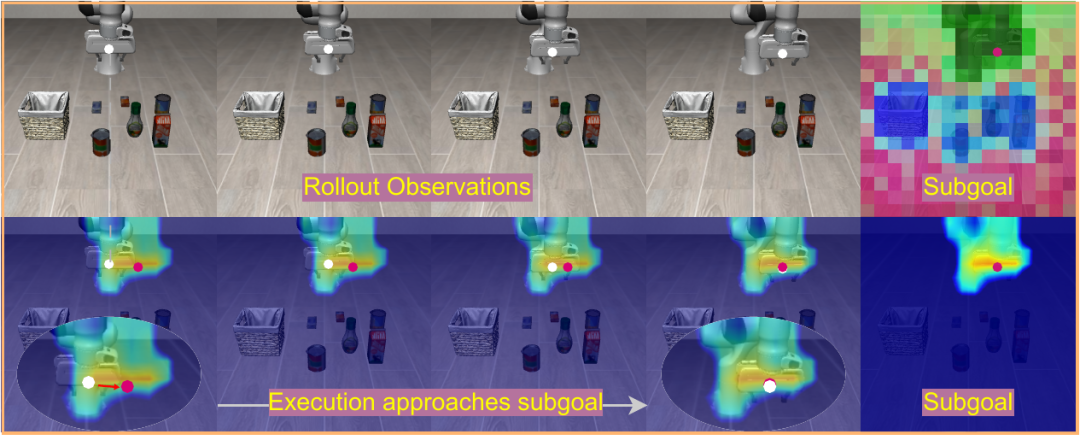
LIBERO 动作块可视化。预测出的隐空间子目标通过热力图标示动作将要接近的交互区域,引导执行轨迹逐步推进。
02.
先学动作意图,再预测场景变化
如果希望机器人从人类视频中学习动作规律,首先要避开一个直接翻译的陷阱。人手的关节、机器人手臂的关节、夹爪的形态和控制频率都不一样,视频里的“把物体往那里移动”很难直接变成某台机器人的底层指令。
更可行的做法,是先学习一种抽象的动作意图。它不描述某个关节该转多少度,而描述当前画面到未来画面之间发生了什么变化。这就是隐动作模型(Latent Action Model, LAM)要解决的问题。LAM 会看一对当前视觉状态和未来视觉状态,从中推断一个隐动作(latent action),再用解码器预测未来状态。
过去许多工作更关注隐动作本身,把它当作跨机器人本体的抽象动作表示。LaWAM 的关键一步,是把注意力放到 LAM 的解码器上。这个解码器已经学会根据当前视觉特征和隐动作,预测下一段时间后的视觉特征。
LaWAM 保留这个解码器,把它变成策略可调用的隐空间世界模型(Latent World Model, LaWM)。隐动作表达抽象动作意图,LaWM 负责把这个意图放回当前场景,展开成具体的隐空间视觉子目标。这样一来,人类视频中的动作规律无需硬翻译成机器人关节命令,可以先变成“当前场景会怎样变化”的隐空间预测,再交给动作专家生成真实的动作块。

LaWAM 两阶段框架。第一阶段学习 LaWM,第二阶段将 LaWM 预测出的隐空间视觉子目标交给动作专家使用。
从数学角度看,常见的视觉-语言-动作模型(Vision-Language-Action, VLA)直接学习当前观测和语言到动作块的映射。
WAM 进一步把未来状态交给策略,其联合概率分解如下。
如果 代表高维像素视频,第一项会非常昂贵。LaWAM 保留未来条件生成的结构,同时把未来状态映射到冻结视觉编码器的特征空间中。令 ,,第一阶段学习如下关系。
其中 是隐空间逆向动力学模型(latent inverse dynamics model),从当前和未来特征中推断隐动作。LaWM 作为前向解码器,结合当前视觉特征与隐动作来预测未来视觉特征。训练目标包含未来特征预测误差、KL 正则项,以及轻量的末端执行器状态预测辅助损失。辅助损失让隐动作更偏向具身运动,减少纯视觉外观变化的干扰。
部署时真实未来特征 尚未发生,策略需要先根据当前观测和语言预测隐动作,再驱动 LaWM 产生子目标。
也就是说,策略先验先预测 ,冻结的 LaWM 解码出 ,动作专家再基于当前上下文和隐空间子目标生成动作块。第二阶段通过隐动作蒸馏让策略学会稳定驱动 LaWM;知识隔离则在策略训练中保护 LaWM,避免动作专家的梯度破坏它已经学到的场景变化规律。
LaWAM 的预训练利用约 3,000 小时机器人视频和 1,500 小时第一视角人类视频。人类视频提供大量手与物体交互的视觉转移,机器人视频则把这些变化规律连接到具身控制。这里的关键在于,人手动作轨迹不需要被翻译成机器人关节命令。它可以先在隐空间中表现为一种视觉状态转移,再由 LaWM 根据机器人当前看到的本体和场景,把这种转移展开成机器人策略可用的未来子目标。
03.
同一段隐动作,适配不同场景和机器人
下面这组实验是理解 LaWAM 的关键。研究者先从源视频中推断一段隐动作轨迹,然后把同一段隐动作放到不同初始画面、不同场景,甚至不同机器人本体中,让 LaWM 在不接收后续真实画面的情况下自己往后预测。论文把这种分析称为开放环展开。

同一隐动作轨迹在不同本体和场景下生成因地制宜的隐空间展开,其中 (d) 和 (e) 测试了来自未见场景的数据。
这张图传达的信息很直接。同样的抽象动作意图,在手持工具、双臂机器人、折毛巾等不同场景中,会被 LaWM 结合各自的空间结构重新展开。它没有复刻源视频的像素外观,也没有把某个固定动作轨迹硬套到新机器人上。它学到的是“这个动作意图会让当前场景怎样变化”,再把变化后的状态呈现为动作专家可解析的隐空间视觉子目标。
这也解释了为什么隐动作不能单独作为最终输入。隐动作擅长跨本体表达抽象转移,LaWM 则负责把这个抽象转移放回当前视觉状态中。两者合在一起,才形成从人类交互视频到机器人动作生成的中间层。
04.
低延迟来自更合适的表达方式
当未来被表示成隐空间视觉子目标,每个动作块只需要一次隐空间子目标预测,无需迭代生成整段视频。换句话说,模型把算力集中在动作真正需要的未来状态上,省去了重建整段画面的开销。
在 LIBERO 基准上,2.3B 参数规模的 LaWAM 每次动作块推理仅耗时 187 ms。论文在相同评估设置下报告,LingBot-VA 需要 4482 ms;总体来看,LaWAM 的端到端推理延迟相比像素空间 WAM 最高降低 24 倍。
这项效率收益来自模型分工的改变。世界模型从像素视频生成器,转向提前为策略准备下一步所需的未来子目标。LaWM 只有 230M 参数,相比 5B 参数的视频世界模型底座显著降低了系统开销。
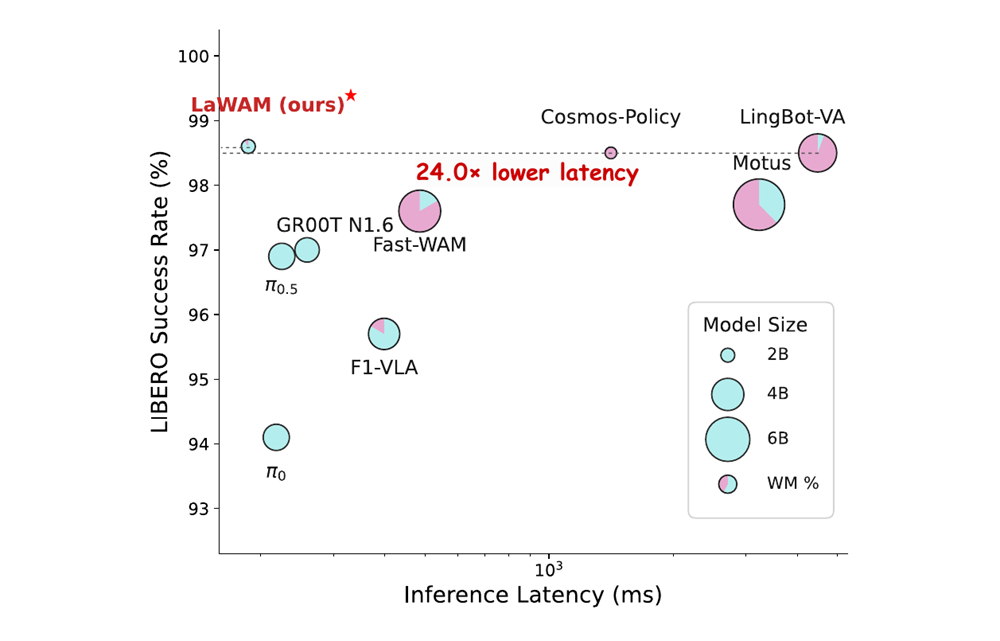
LIBERO 上的延迟-成功率权衡(latency-success trade-off)。LaWAM 位于高成功率、低延迟区域,在维持强劲表现的同时大幅缩减动作块推理耗时。
这张图说明,LaWAM 的优势不只来自更快。它在减少推理延迟的同时,仍保持了很高的任务成功率。后面的仿真和真机实验进一步说明,这种隐空间子目标既轻量,也能支撑复杂操作。
05.
在复杂双臂场景中的泛化能力
在广泛使用的 LIBERO 基准测试中,LaWAM 在四个标准套件上取得 98.6% 的平均成功率,超过或匹配现有强 VLA、隐动作方法以及传统 WAM 基线。
LaWAM 还在 RoboTwin 2.0 上验证了复杂双臂操作能力。在覆盖 50 个双臂任务的测试中,LaWAM 在 clean setting 下达到 92.64%,在 random setting 下达到 89.80%,平均为 91.22%。这说明隐空间子目标可以支撑复杂的双臂协同控制。

06.
真实机器人上的物理预期
LaWAM 进一步在真实机器人上评估了三类极具代表性的物理任务。
抓取放置(pick-and-place),基础的刚体交互。
开抽屉(drawer opening),带有约束的关节物体操作。
折毛巾(towel folding),长时程、双臂协作的可变形物体操作。
实验部署在两套物理平台上,Franka Emika Panda 用于单臂操作,Quanta X1 双臂机器人用于折毛巾。

LaWAM 在真实机器人任务中的代表性执行轨迹。

折毛巾任务尤其能说明隐空间子目标的实战价值。布料状态会随着动作持续改变,如果策略被像素生成延迟拖住,动作很容易对不上当前褶皱。LaWAM 的隐空间特征预测能立即进入动作流,使机器人及时响应动态变化。
07.
消融实验说明 LaWM 是关键
消融实验进一步说明,性能增益来自完整的未来特征推断流程。移除 LaWM 会导致明显性能下降,尤其是在 LIBERO-Long 这类长程任务中。去掉隐动作蒸馏也会削弱策略稳定驱动 LaWM 的能力。知识隔离和蒸馏一起作用时,LaWM 既能被对齐的隐动作驱动,又能避免被动作专家梯度破坏。
真实机器人推理可视化。RGB 画面与子目标可视化展示了 LaWAM 如何把未来状态变化编码成动作专家可即刻调用的视觉指导信号。
限制与展望
目前的 LaWAM 架构在相机视角相对固定的操作任务中表现最优。如果场景中的视觉变化主要来自剧烈相机运动,而非物体物理交互,隐动作空间会更难学习。处理极其细微的可变形物体动态,也需要更丰富的数据分布支撑。
因此,引入更大规模、更多样化的真实交互数据,并增强隐空间世界模型对移动相机和微小接触状态的处理能力,是自然的下一步。
结语
在具身智能中,让机器人“想象未来”的目标,是建立可行动的物理预期。LaWAM 的关键贡献不止是更快的推理。它重新定义了未来预测进入策略的形式,让系统可以从人类交互和机器人视频中学习动作相关的视觉转移,再把这些转移结合当前机器人本体和场景,生成可执行动作所需的隐空间视觉子目标。
这也契合清华大学团队与正行创新共同推进的方向。物理智能的长期竞争力来自数据、模型、系统基础设施与真实场景的共同演进。LaWAM 作为这条路线中的基座能力之一,让世界动作模型更接近真实机器人需要的形式,在可实时处理的隐空间中学习物理状态变化,并为人类动作规律向机器人动作生成的迁移提供中间表示。