各类万亿参数MOE(混合专家)大模型疯狂涌现的今天,算力需求已经不能单靠优化单个GPU来解决,而是需要将成百上千张GPU拧成一股绳。这股绳怎么拧?这就是AI超节点服务器要解决的核心问题。从Scale-up(垂直扩展)的视角来看,超节点正在经历一场从“物理大一统”向“光网络解构”的深刻变革。
在过去,超节点内部GPU之间的高速互联,最可靠、最经济的方式无疑是Copper Tray(铜缆互联)。通过密集的铜背板或铜缆,GPU之间可以实现极低延迟的Scale-up吞吐。然而,物理定律是残酷的。随着大模型参数突破万亿,MOE模型中的专家数量呈指数级增加,单一机柜已经塞不下所需的GPU数量(例如需求达到 128卡、256卡甚至更多)。更致命的是,GPU侧的SerDes速率正在从112G向224G飙升,未来甚至会演进到448G。铜缆就像高铁:高铁贴地飞行,受限于轨道、空气阻力和地面摩擦,时速到350-400 km/h 几乎就逼近了物理和经济成本的极限。SerDes速率越高,铜缆的信号衰减就越恐怖,传输距离被压缩到极致,连走出机柜都做不到。光网络就像飞机:飞机可以直接飞向万米高空,摆脱了地面的束缚,可以轻松达到 900 km/h甚至更快的速度。光子在光纤中的损耗极低,天然具备超大带宽和超长传输距离。因此,当超节点需求跨越机柜限制时,“铜退光进”成为必然,只能通过光互联来实现跨机柜的超级节点集群。
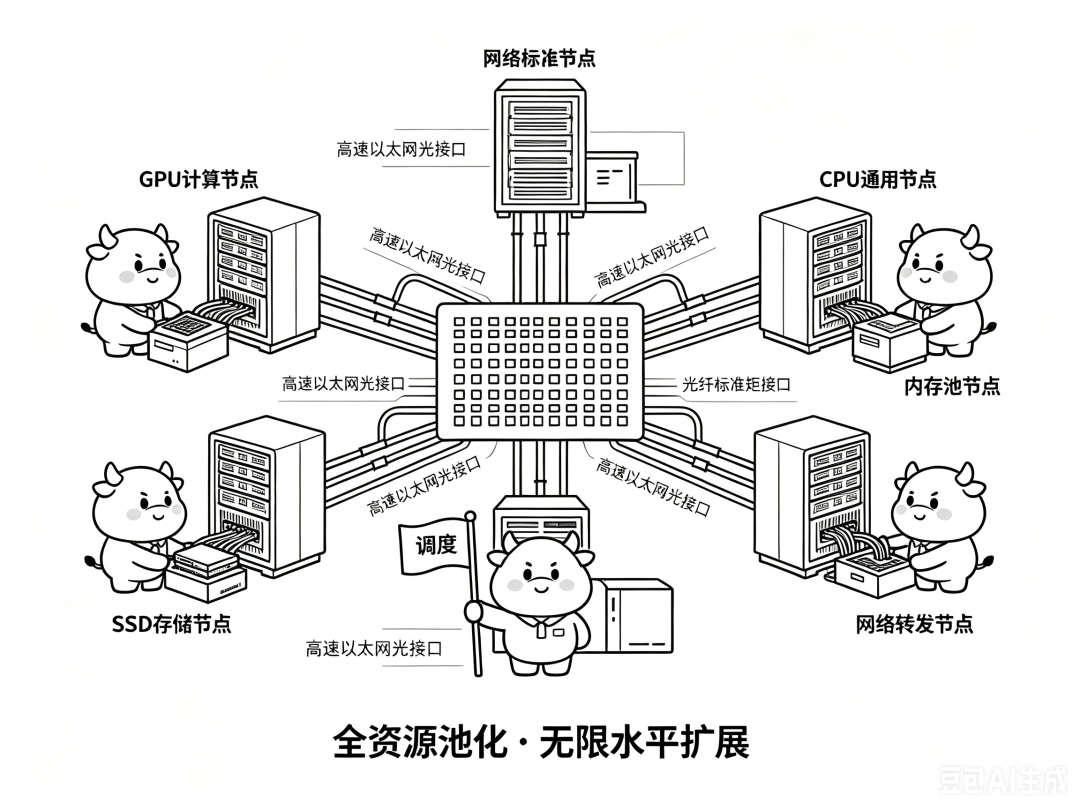
回顾计算机的发展史,我们会发现历史总是惊人的相似: 在大规模计算时代的早期,大型机(Mainframe)和小型机(Minicomputer)凭借高可靠性和强大的单机性能统治市场。但由于它们架构封闭、扩展昂贵,最终被高性价比、标准化的X86服务器分布式集群所取代。今天的AI超节点也正处于这个十字路口。传统的单机柜“大怪兽”由于散热、供电和空间限制,必然走向分布式解构架构。未来的超节点集群,将采用一种“对称型”的拓扑结构:中间:网络节点。放置高性能的光网络交换机(速率达400G、800G,甚至1.6T)。两边:计算节点。GPU/CPU服务器直接出以太网光接口(400G/800G/1.6T),不再通过复杂的中间层,直连中央的光交换机。通过这种解构,集群可以轻松突破物理机柜限制,实现256卡、512卡、甚至1024卡的超大规模高速低延迟互联。光模块的无DSP革命:
CPO、NPO、LPO与XPO
在光网络互联中,如何降低功耗和成本是重中之重。过去的光模块里都有一个号称“功耗大户”的芯片——DSP(数字信号处理器)。当前大热的几项前沿光技术:CPO、NPO、LPO以及XPO(液冷可插拔),它们最大的共同点就是:干掉(或极大地弱化)DSP!从而实现功耗和成本的双重暴降。| 技术方案 | 技术原理 | 核心特点 | 典型适用场景 |
CPO | 将光发动机(Optical Engine)和交换芯片(ASIC)直接共同封装在同一个基板上。 | 信号传输距离最短,损耗和功耗极低。但制造工艺极难,维护成本高。 | 适用于超高密度、对功耗极端敏感的超大型数据中心核心交换中心。 |
NPO | 光发动机不跟芯片挤在一起,而是放在芯片附近的PCB母板上。 | 介于CPO和传统模块之间,兼顾了性能与制造良率,折中的过渡方案。 | 适用于中短期内向高性能网络过渡的大带宽交换机节点。 |
LPO | 保持传统可插拔外形,去掉DSP,只使用高线性的驱动器(Driver)和放大器(TIAs)进行线性信号放大。 | 100%兼容现有插拔接口,成本低,时延极低(省去了DSP转换时间),但对系统协同测试要求高。 | 适用于AI集群中短距离(机柜间)的高速GPU直连通道,能极大降低整体算力延迟。 |
XPO | 液冷可插拔光模块。专门针对高密度液冷服务器设计,将光模块直接暴露或适配液冷环境。 | 解决去DSP后依然存在的高热密度问题,保障光器件在极高功率下的波长稳定性。 | 适用于未来全液冷AI超节点服务器内部及机柜边缘的高密互联。 |
超节点的分布式演进并不会止步于GPU的互联。未来的终极趋势是ALL in 高速以太网(全解构光网络)。传统的服务器是一个“偏科的整体”(紧耦合),而未来,GPU节点、CPU节点、内存节点、SSD存储节点、以及网络节点将全部被“大卸八块”(全解构)。它们各自独立存在,互不绑定,中间通过统一的、超高速的光网络以太网像搭积木一样串联起来。需要多少算力,就动态调度多少GPU;需要多少缓存,就一键直连内存池。光网络将化有形为无形,真正实现“网络即计算机”的算力自由。
智猩猩主办的2026中国AI智能体大会7月2-3日杭州举行,大会设有开幕式,企业级AI智能体、AI智能体产品创新2场论坛,以及Coding Agent、自进化智能体、深度研究智能体、Computer-Use Agent、多智能体协同、Agent Skills、Agent Harness7场技术研讨会。最终议程已公布。