论文作者均来自北京大学王选计算机研究所,第一作者为吴将凯博士,第二作者为本科生任致远,第三、第四作者为博士生钟俊权、刘黎明,通讯作者为张行功副教授。
从 ChatGPT、Gemini Live、豆包到智能眼镜,AI 正在从「文字聊天」走向「边看边聊」。但当视频通话的另一端不再是人,而是部署在云端的多模态大模型时,传统实时视频通信系统遇到了一个根本错位:它仍在努力让「人眼看得更舒服」,而新的目标其实是让「AI 答得更准确、响应更及时」。
北京大学团队提出 Artic,一套面向 AI 的实时视频通信框架,系统性重构了 AI 视频助手场景下的码率自适应、视频编码、反馈控制和评测基准。实验结果显示,在真实移动上行网络轨迹下,Artic 相比现有框架显著提升 15.12% 准确率,并降低 135.31 ms 延迟。
一句话概括:Artic 不是让视频一味更清晰,而是让网络传输学会服务大模型的「理解状态」。
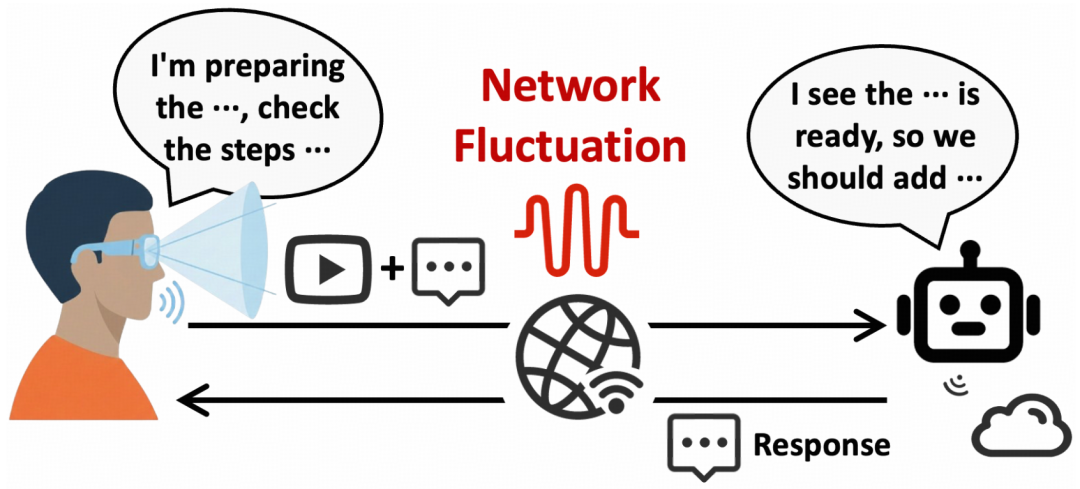
图 1:AI 视频助手是一种新的实时通信范式,用户将视频和音频传给云端大模型,AI 返回语音或文本响应。

论文题目:Artic: AI-oriented Real-time Communication for MLLM Video Assistant
作者:Jiangkai Wu, Zhiyuan Ren, Junquan Zhong, Liming Liu, Xinggong Zhang
单位:Peking University
会议:ACM SIGCOMM 2026(已接收)
原文链接:
https://arxiv.org/abs/2602.12641 代码:
https://github.com/pku-netvideo/Artic 基准:
https://github.com/pku-netvideo/DeViBench
引言:视频通信,
正在从「给人看」转向「给 AI 理解」
过去二十多年,实时视频通信的优化目标非常清楚:让人看得清、看得流畅、不要卡顿。因此,无论是拥塞控制、码率自适应,还是视频编码,大多围绕画面质量(PSNR、SSIM、VMAF)、帧率、分辨率和卡顿率等「人眼体验」指标展开。
但 AI 视频助手改变了这个前提。用户拿着手机或智能眼镜走在路上,摄像头持续把第一视角画面上传到云端大模型;模型并不需要「欣赏」整个视频,它只需要抓住足够回答当前问题的关键信息。例如用户在商场里问「这个商品是什么」、在展馆里问「这块导览牌写了什么」,模型真正需要看清的是商品标签、导览牌文字等局部细节,而不是包含背景区域的整张画面。
这带来两个直接变化。第一,体验质量的核心指标变了:传统实时视频通信关心的是人眼感知画质、流畅度和稳定性;AI 视频助手更关心模型回答是否正确、是否能及时触发响应。因此,视频允许在非关键区域变糊或不流畅,但关键区域一旦看不清或卡顿,就会直接变成回答错误或响应滞后。
第二,网络条件也变了。AI 视频助手常运行在手机、智能眼镜等移动终端上,服务导览、购物识物等随身场景。用户边走边用时,终端位置、朝向和人体遮挡关系持续变化,还可能在不同 Wi-Fi 接入点、不同基站覆盖区域,或 Wi-Fi 与移动网络之间切换;这些物理链路和接入路径变化会直接改变上行信道质量。因此,相比视频会议、远程桌面等更偏静态使用的传统实时视频通信场景,AI 视频助手面对的上行带宽波动更大、发生得更频繁。
论文中的生产原型测量给出了一个直观例子:当用户从稳定环境进入电梯时,可用带宽在约 1.5 秒内从 5 Mbps 跌到 1.23 Mbps。传统实时视频通信的拥塞控制来不及收缩码率,造成最高 1389 ms 的延迟尖峰;随后码率被大幅压低,又会让关键视觉信息变糊,直接导致大模型回答错误。
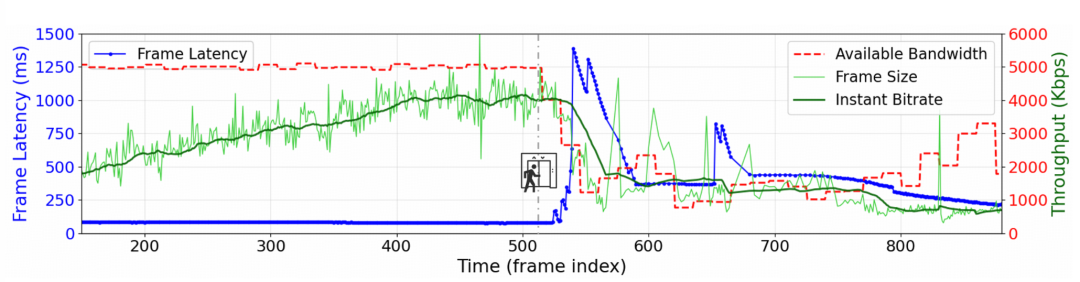
图 2:真实移动场景中,带宽突降会导致传统实时视频通信出现严重延迟尖峰。

图 3:当关键区域被低码率压糊,大模型可能从正确回答变成错误回答。
研究内容:Artic 如何让通信系统「懂 AI」
Artic 的核心思想,是把大模型的感知状态纳入实时通信闭环(整体架构如图 4 所示)。传统实时视频通信看到网络有余量,就倾向于把码率继续拉高;Artic 则会追问另一个问题:当前视频质量对模型回答来说是否已经足够?如果答案是足够,就不必继续填满带宽,而应该把余量留给下一次网络波动。
围绕这一思想,Artic 包含三个模块:响应能力感知码率自适应(ReCapABR)负责「何时不再加码率」,零开销上下文感知流传输(ZeCoStream)负责「有限码率应该给哪里」,退化视频理解基准(DeViBench)则负责「如何评测视频退化对模型理解的影响」。
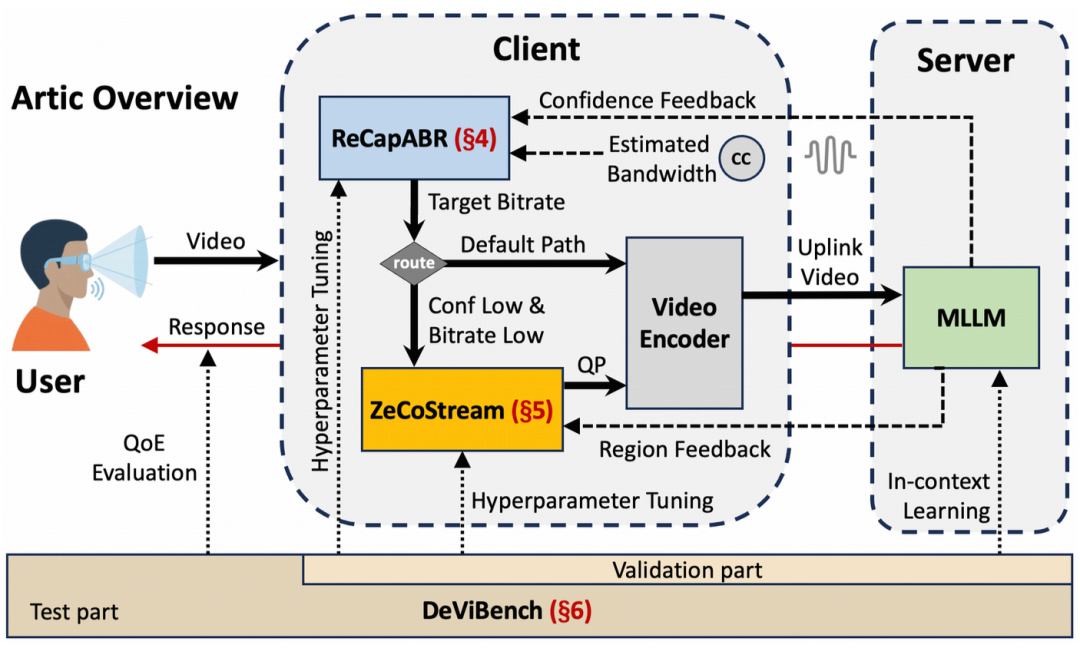
图 4:Artic 总体架构,包括 ReCapABR、ZeCoStream 和 DeViBench 三个核心部分。
1. ReCapABR:当模型已经看懂,就不要继续抢带宽
在传统实时视频通信中,带宽越高通常画质越好,因此拥塞控制会尽可能把可用带宽用满。但在 AI 视频助手里,这个逻辑并不总成立。大模型的回答准确率存在「饱和」现象:当画面质量达到足以支撑当前回答的水平后,继续提高码率,准确率提升可能很小。
ReCapABR 利用大模型反馈的响应置信分数判断当前回答能力是否已经饱和。如果模型已经有足够信心,Artic 就主动限制码率,即使底层拥塞控制认为还可以继续加码,也会保留一部分带宽余量,用来吸收之后可能发生的网络波动。
这是一种很有意思的反直觉设计:在网络还不错的时候主动「少发一点」,反而可以在网络变差的时候「少卡很多」。
2. ZeCoStream:把有限码率花在模型真正关心的位置
如果网络带宽确实不足,单纯降码率会让整幅画面一起变糊。对人类观众来说,这也许只是画质下降;但对大模型来说,某个局部文字、商品标签、车牌或仪表盘一旦糊掉,就可能直接导致答案错误。
ZeCoStream 的做法是让云端大模型反馈当前对回答最重要的区域,客户端再根据这些区域动态调整编码器的量化参数(QP),把更多比特分配给关键区域,把更少比特分配给无关背景。相比在客户端额外部署轻量模型来做区域识别,这种方式几乎不增加端侧计算开销,因为「哪里重要」本来就是大模型在理解视频时已经具备的能力。
为了抵消反馈延迟,ZeCoStream 还让大模型同时预测当前和未来可能重要的区域,使客户端不只是被动追随,而是提前保护接下来可能影响回答的视觉信息。
3. DeViBench:为 AI 视频助手建立「退化视频理解」基准
现有视频传输评测多关注人类感知质量,现有视频理解基准又往往默认输入视频质量较高。两者都无法回答一个新的系统问题:实时视频通信引入的视频质量下降,究竟会怎样影响大模型的回答准确率?
为此,Artic 提出 DeViBench。它并不只问粗粒度问题,而是专门构造对视频质量敏感的问答样本:同一问题在高码率视频上能答对,在低码率退化视频上会答错,才真正能暴露通信质量对模型理解的影响。DeViBench 的自动构建流水线包含视频收集、退化编码、问答生成、敏感样本筛选与交叉验证等步骤(见图 8)。最终包含 1,968 个问答样本,总视频时长 88,680 秒,覆盖 6 * 2 类场景,并提供测试集和验证集。这使它不仅可以评估系统体验质量,也可以用于 Artic 的超参数调优和大模型的 in-context learning。
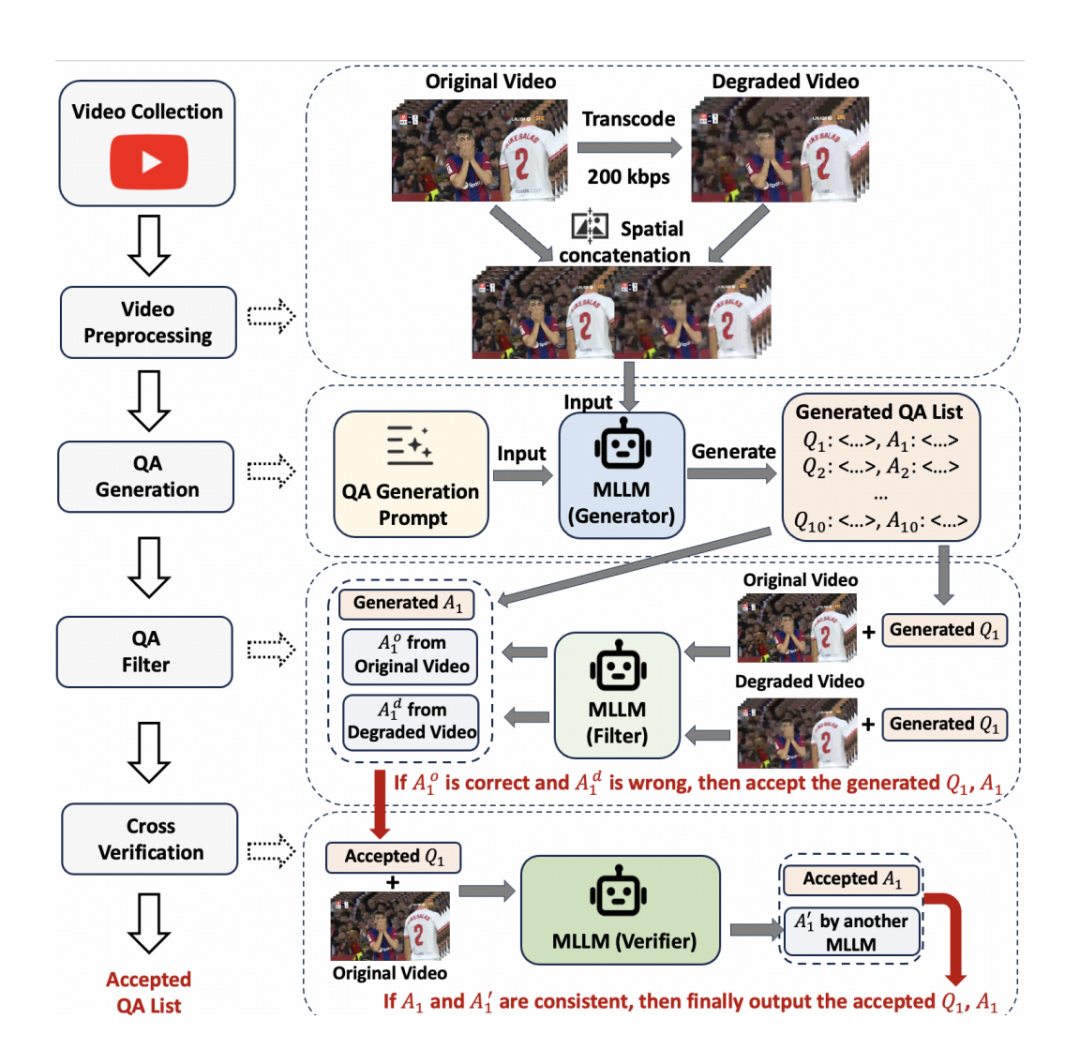
图 8:DeViBench 自动问答样本构建流水线,通过高码率视频与低码率退化视频的回答差异筛选退化敏感问答样本。
实验评估:更低延迟、更高准确率、更可控开销
研究团队使用 C++ 和 Python 实现了 Artic 原型,并与传统 WebRTC 以及不同组件组合进行对比。实验分为三个层面:组件级实验分别验证 ReCapABR 的延迟收益和 ZeCoStream 的准确率收益;基于真实网络轨迹的仿真实验评估了端到端体验质量;系统开销分析则考察客户端计算、服务端成本。
在延迟方面,ReCapABR 在带宽波动越剧烈时收益越大。当每分钟 1 次带宽波动时,平均延迟降低 23.7 ms;当每分钟 4 次波动时,平均延迟降低扩大到 148.4 ms。
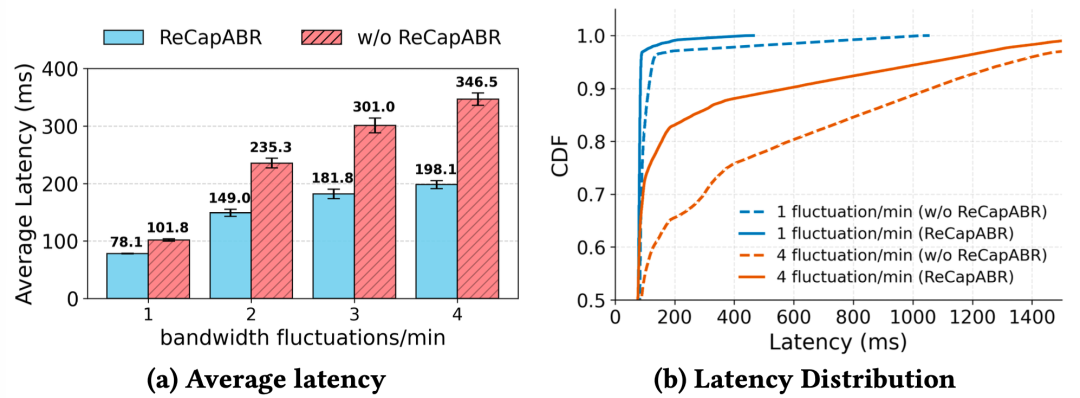
图 5:ReCapABR 在带宽波动越频繁时,延迟收益越明显。
在准确率方面,ZeCoStream 在低码率下优势明显。以 290 Kbps 为例,普通编码准确率仅为 0.39,而 ZeCoStream 可维持在 0.60。若要达到 0.9 的准确率,普通编码需要超过 3171.37 Kbps,ZeCoStream 只需要 907.60 Kbps。
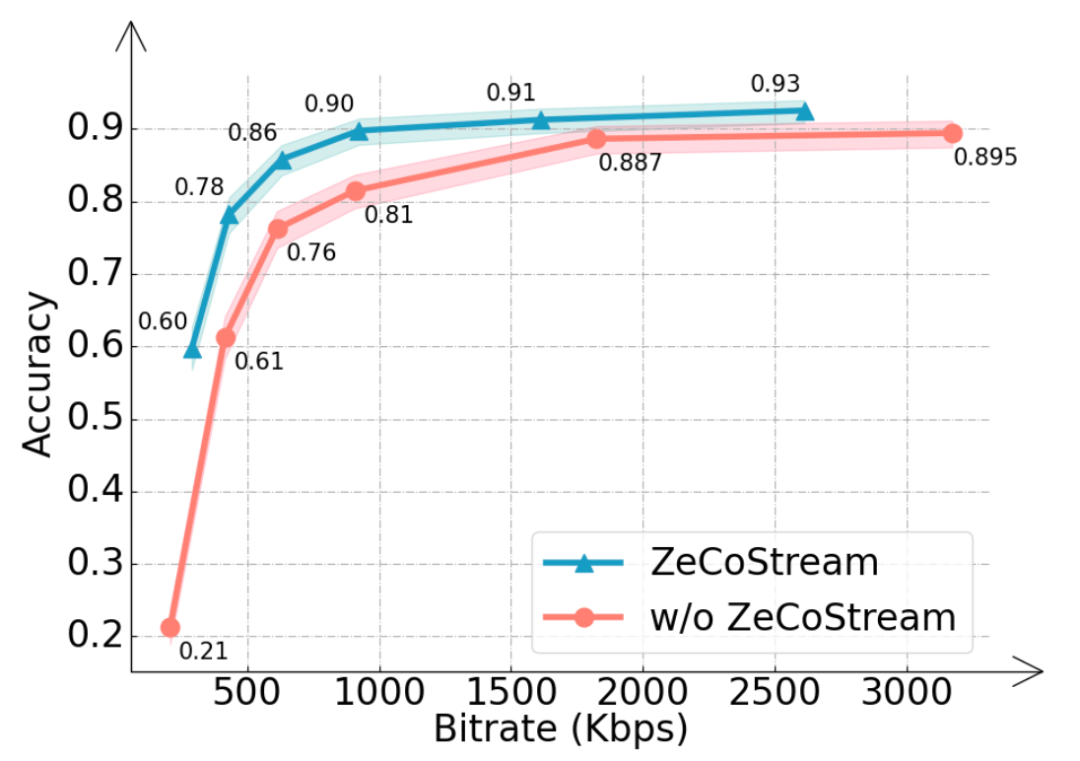
图 6:ZeCoStream 在低码率下显著提升回答准确率,并降低达到高准确率所需的带宽。
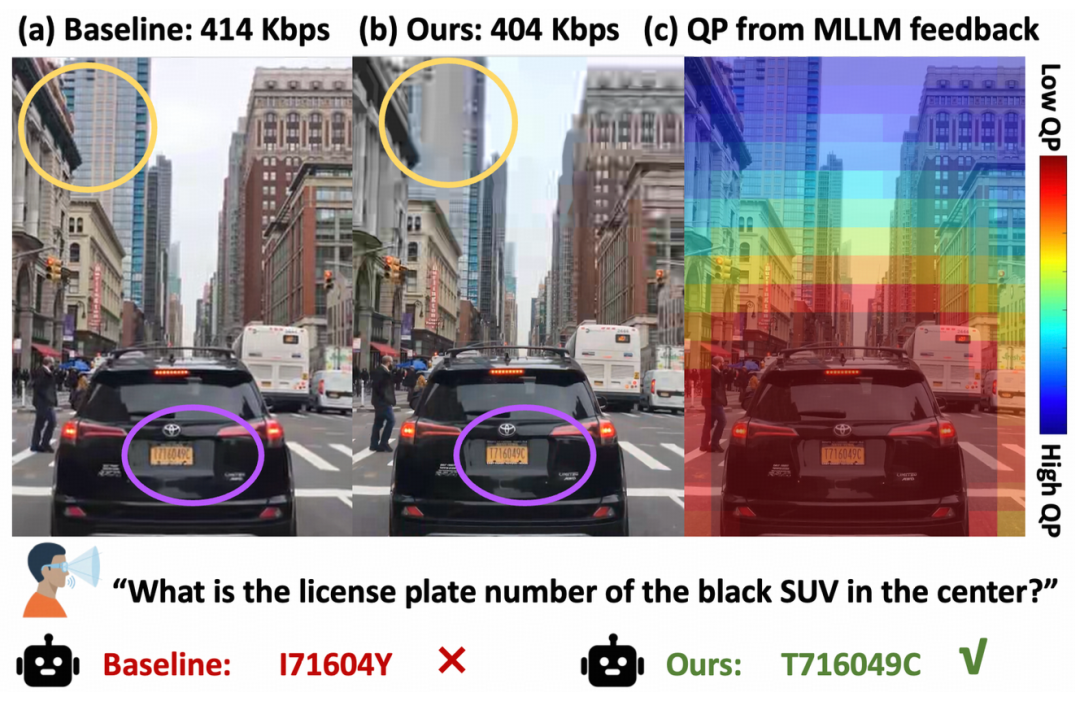
图 7:ZeCoStream 将有限码率优先分配给与当前问题相关的关键区域。
端到端结果显示,在真实移动上行网络轨迹驱动的评测中,Artic 不仅可以同时降低延迟与提升准确率,还在不同底层拥塞控制算法下都有效。如图 9 所示,以 BBR 为拥塞控制算法时,Artic 将平均准确率从 79.62% 提升到 84.80%,并降低 135.31 ms 平均延迟;而在 GCC 中,Artic 相比 WebRTC 也实现 15.12% 的准确率提升,并同时降低约 90.64 ms 延迟。
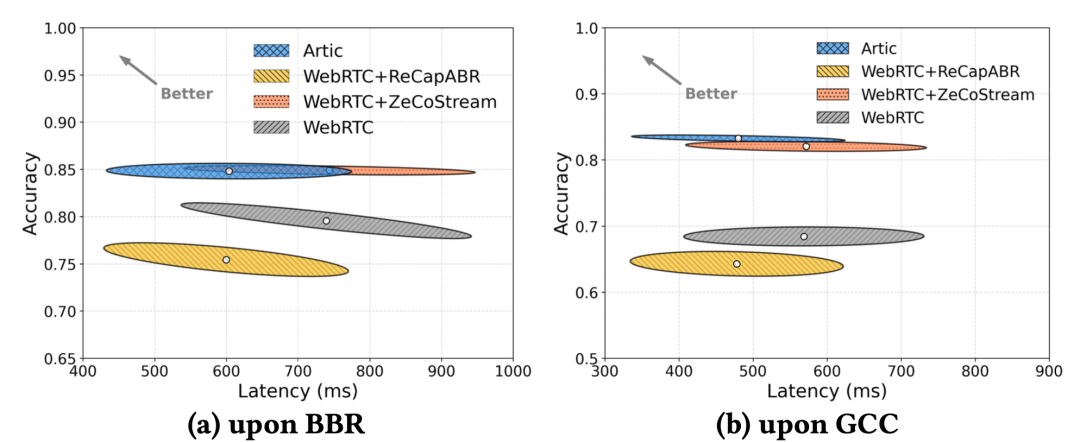
图 9:真实移动上行网络轨迹下,Artic 同时提升准确率并降低延迟。
客户端开销方面,Artic 的设计相对轻量。ReCapABR 在端侧只需要根据模型反馈的置信分数调整目标码率,ZeCoStream 也只是把服务端反馈的关键区域映射为编码器参数;这些都是简单数值计算,因此不会明显增加端侧算力或功耗负担。
服务端开销主要来自额外的大模型反馈调用。论文基于真实实验支出估算,在标准 AI 视频助手中,主要成本来自大模型调用和实时视频通信服务;Artic 额外引入 ReCapABR 的置信反馈和 ZeCoStream 的区域反馈,使总成本从 0.3126 美元/分钟增加到 0.3974 美元/分钟,增幅为 27.13%(如图 10 所示)。考虑到其能够换回更稳定、更准确的交互体验,这是值得投入的。
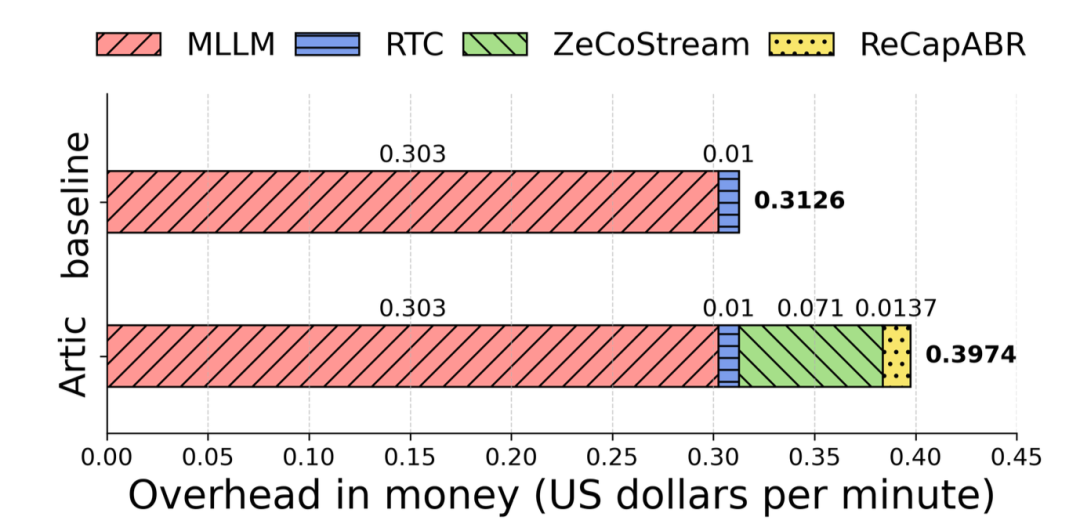
图 10:Artic 的服务端成本主要来自额外的大模型反馈调用,总成本从 0.3126 美元/分钟增加到 0.3974 美元/分钟。
结论:从网络系统角度走向「真人交互」
让 AI 像真人一样交互,过去更多被理解为模型侧问题:更强的多模态理解、更自然的语音对话、更长的上下文能力。Artic 强调了另一条路径:即使模型本身足够强,如果视频流在真实移动网络中出现延迟尖峰、关键区域被压糊,AI 仍然无法表现得像「在场的人」。因此,Artic 的意义在于把这一愿景转化为网络系统问题:让实时视频通信根据模型的感知状态和真实需求调整传输策略,使云端大模型在恶劣网络中也能及时、准确地「看见」并回应用户。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com