
被一道数学竞赛题卡住很久时,高手往往能准确地判断:现在缺的是一个技术细节,还是整个思路从一开始就走错了?在回顾自己的探索和进展时,他们不断地评估哪些步骤已经通过验证,哪些命题存在缺陷,甚至凭直觉就能意识到哪些假设不可行;然后决定继续深挖,还是彻底转向一条全新的路径。知道自己卡在哪里、又该在何时推倒重来,是人类解决困难问题时极其关键的元认知能力。
而这恰恰是当前最强大语言模型仍难以稳定具备的能力。它们会沿着一条看似合理的路线不断补充细节、修饰论证,写出局部自洽、甚至颇具说服力的推导;但模型往往缺乏可靠的机制去识别「这不是一个需要继续打磨的解法,而是一条死路」。模型很难通过自我纠正跳出根本性错误的推理方向,而且缺乏像人类一样「从错误中学习」的主动意识。
为了解决这一瓶颈,清华大学与微软亚洲研究院的研究团队提出了一个推理多智能体系统 STAR-PólyaMath,在 LLM 外部构建了一套完整的探索-推理-验证框架(harness),通过协调 Reasoner、Verifier 和 Meta-Strategist 三个智能体角色,循环驱动长程证明,使推理过程变得可验证、可回溯,实现跨尝试积累经验。
STAR-PólyaMath 在八大顶级数学竞赛基准上全部取得最优成绩,其中 AIME 2025/2026、Putnam 2025、HMMT 2026 获得满分,在最难的 MathArena Apex 2025 上领先同基座的 GPT-5.5 模型达 13.5%。

论文标题:STAR-PólyaMath: Multi-Agent Reasoning under Persistent Meta-Strategic Supervision
论文链接:
https://arxiv.org/abs/2605.19338v1 开源链接:
https://github.com/Julius-Woo/STAR-PolyaMath
本文第一作者吴嘉骜,是清华大学人工智能学院 T-STAR Lab 的一年级博士生,研究方向是大模型推理及智能体系统。本文通讯作者是微软亚洲研究院首席研究员(Principal Researcher)张宪和清华大学人工智能学院董胤蓬助理教授。其他合作者来自纽约大学、MIT 等。清华大学 T-STAR Lab 聚焦 AI 基础理论、AI 安全、智能体、空间智能等方向研究,致力于理解人工智能模型的机理,发展安全、可靠、可信的人工智能理论与方法。
一、案例:GPT-5.5 反复错误,
STAR-PólyaMath 成功突破
MathArena Apex 是从 2025 年近百场公开数学竞赛中筛选出的前沿模型稳定无法解出的 12 道问题,彼时最强模型的平均正确率不到 5%。MathArena 团队在定性分析中指出了一个普遍现象:模型倾向于很快锁定一个(往往错误的)答案并努力证明其正确,而不是继续寻找更好的方案。
Apex 2025 Problem 2(「The Zigzagging Chessboard」,源自 Turkey TST 2025 P5)是其中的一个典型案例。问题要求确定一个和多边形边界方格计数相关的最优常数 k,正确答案是 k = 1/2。开启最高思考强度的 GPT-5.5 对这道题进行了 8 次独立尝试,只对了 1 次。仔细看每次的推理过程,它快速收敛到某个次优构造上,得出错误答案,并努力提供逻辑自洽的论证来支撑这个错误结论。
这正是我们前面提到的大模型在长程数学推理中面临的核心困境。尽管模型有足够的数学知识来解决问题,但当一个合理或普遍的错误方向形成后,它缺乏「跳出当前思路回顾」的元认知,在同一个错误上空转。
在 Apex Problem 2 上,STAR-PólyaMath 的 Reasoner 第一次尝试同样失败,尽管它认为做出了答案 3/4,但 Verifier 始终质疑其证明过程,且在经历三次超时失败后,Meta-Strategist 从跨尝试的失败记录中做出了一个关键判断:「这个方向是根本错误的」,明确禁止后续推理重新锚定在 3/4 上,并授权重新规划(re-plan)。新方案找到了一个更密集的构造,将结果推至 1/2,并通过数学推导和实际构造简单连通多边形的代码验证,完成了严格证明。

STAR-PólyaMath 在 Apex 2025 Problem 2 上的案例对比
二、长程推理的三重困难
前沿大语言模型在推理上已经非常强大,在数学竞赛上能取得接近满分的成绩。但面对最困难的竞赛题时难以一上来就有正确的思路,需要不断探索、提出假设、取得进展或推翻猜想,甚至推倒重来。在这种长程推理中,三类系统性的失败模式反复出现。
幻觉累积与可信性问题。模型倾向于对自身的中间结论保持高置信度,中间步骤中一个看似微小的错误(例如一个边界情况的遗漏)会在后续推导中不断放大。
跨尝试的记忆丢失。当一条证明路径失败、需要回溯时,大多数系统要么保留过多上下文信息,导致无法准确定位错误,要么丢失之前尝试的关键信息(上下文被压缩或会话重置),结果是反复尝试已经被证伪的方向,正如 GPT-5.5 在 Apex Problem 2 上的表现。一个可靠的推理系统需要对「哪些路走不通」保持持久且结构化的记忆。
推理与工具使用的失衡。运行代码是可靠的计算和验证手段,但也有研究表明,经过工具使用数据训练的模型会系统性地偏向代码而忽视数学结构的发掘。尤其是在复杂的组合问题上,暴力搜索几乎很快就达到了不可承受的计算规模。反过来,纯自然语言推理又难以处理需要符号化构造的问题。在缺乏元认知判断的情况下,模型难以平衡好「何时该计算探索、何时该数学推理」。
三、STAR-PólyaMath:
结构化推理与持久元监督
STAR-PólyaMath 的设计灵感来源于波利亚(George Pólya)在《How to Solve It》中提出的解题步骤,即理解问题、制定计划、执行计划、回顾反思。这被结构化为框架的四个阶段:探索(exploration)、规划与分解(planning & decomposition)、逐步执行与挑战循环(step-wise execution & challenge loop)、解答生成(solution generation)。
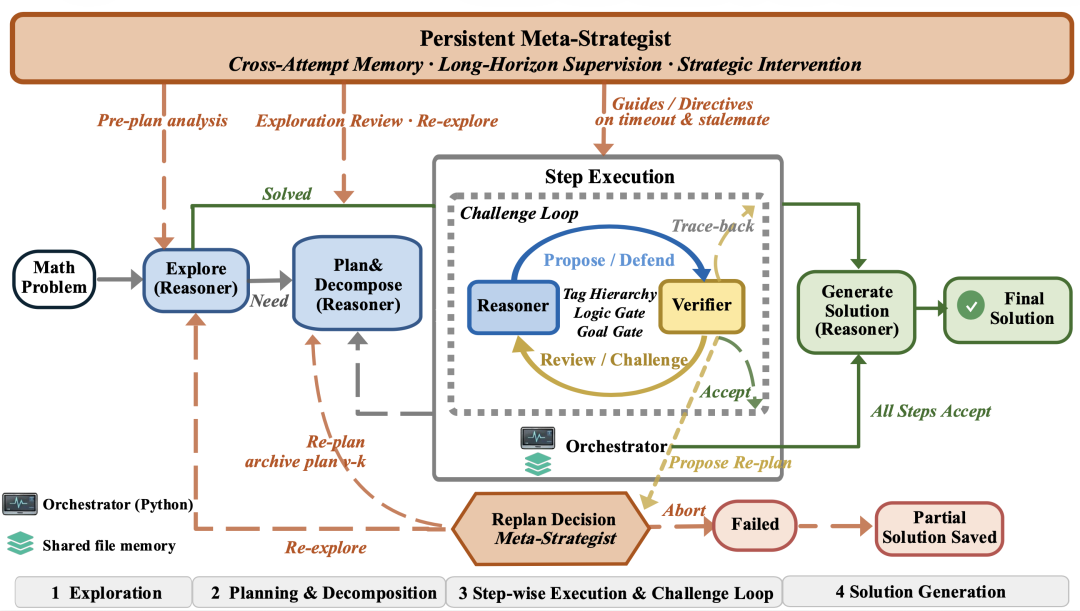
STAR-PólyaMath 系统工作流
架构设计
整个框架由一个无推理能力的 Python 编排器(Orchestrator)协调三个智能体。
Reasoner 负责实际的问题求解,包括探索问题结构、提出计划、执行每一步的推理或计算,并在受到质疑时为自己的论证辩护。它的输出始终需要通过验证环节。在一次尝试(即顺序执行一个计划)中,它保留完整记忆,但在回溯和重新计划时重置记忆,以减少错误推理的污染。
Verifier 负责对 Reasoner 的输出进行独立审查,不保留记忆。审查有两个门控机制,目标门(Goal Gate)检查该步骤是否真正完成了计划中声明的目标,防止「语义漂移」(即论证正确但仅完成了平凡的解答),逻辑门(Logic Gate)则审查推理内容的正确性。审查后给出四种判定之一:通过(Accept)、质疑(Challenge)、回溯(Trace-Back)或 Propose-Replan(提出重新规划)。
Meta-Strategist 是该框架最关键的创新。它就像一位经验丰富的导师,不执行任何具体的数学推理,而是在更高层面给出指导。它在整个问题的解决过程中保持单一持久会话,积累所有之前的尝试、被放弃的策略以及长期存在的失败模式。在关键时刻,Meta-Strategist 会给出具体的策略建议,例如在 Verifier 提出重新规划时做出最终裁决。当检测到 Reasoner 连续陷入无意义的计算等待时,它可以发出强制性指令,要求切换到禁止使用代码的纯推理模式。
使推理过程可验证
STAR-PólyaMath 通过分层验证标签(verification tags)让长程推理的每一步都具有可检验性。每个中间断言都必须标注为 [verified](已执行代码验证)、[easy-verify](可通过简单计算检查)或 [hard-verify](需要严格的数学审查)。这套标签决定了 Verifier 的审查力度,代码验证的结果被直接视为可信,纯数学论证则接受最严格的逻辑审查。
从实际运行统计来看,这种分层策略体现了清晰的适应性。在 AIME 和 HMMT 这类以计算为主的竞赛中,约 36-43% 的断言通过代码验证;而在 IMO、Putnam 等以证明为主的竞赛中,85% 以上的断言属于 [hard-verify],由 Verifier 承担主要验证工作。框架并非一刀切地偏向工具或推理,而是根据问题性质动态调整验证策略。

挑战循环与错误恢复
Reasoner 与 Verifier 之间的交互是一种保留完整会话上下文的结构化辩论(structured debate)。当 Verifier 对某一步提出质疑时,Reasoner 可以为自己辩护、补充论证或修正错误,Verifier 则基于新的信息重新评估。这种双向辩论机制防止了过于保守的 Verifier 错误否决正确的论证。
当步骤内辩论无法收敛时,框架具备两层错误恢复机制。回溯(Trace-back)将推理回退到出错的源头步骤,归档错误的分支,同时保留已验证的中间结果供新尝试使用。重新规划(Re-plan)则是更彻底的回退,当 Meta-Strategist 判断整个计划方向有误时,它授权归档当前计划并重新开始,同时将先前失败的方向标定禁止,注入后续所有 Reasoner 的上下文中。
这些机制共同保证了推理过程的可靠性。错误被尽早发现,不会持续传播;失败被结构化记录,不再重复发生;长程推理的每一步都有独立的可验证性。
四、实验结果
STAR-PólyaMath 使用 GPT-5.5(xhigh effort)作为三个智能体的基座模型,在 8 个顶级数学竞赛基准上全部取得最优成绩(评测协议和 MathArena 对齐,详见论文):
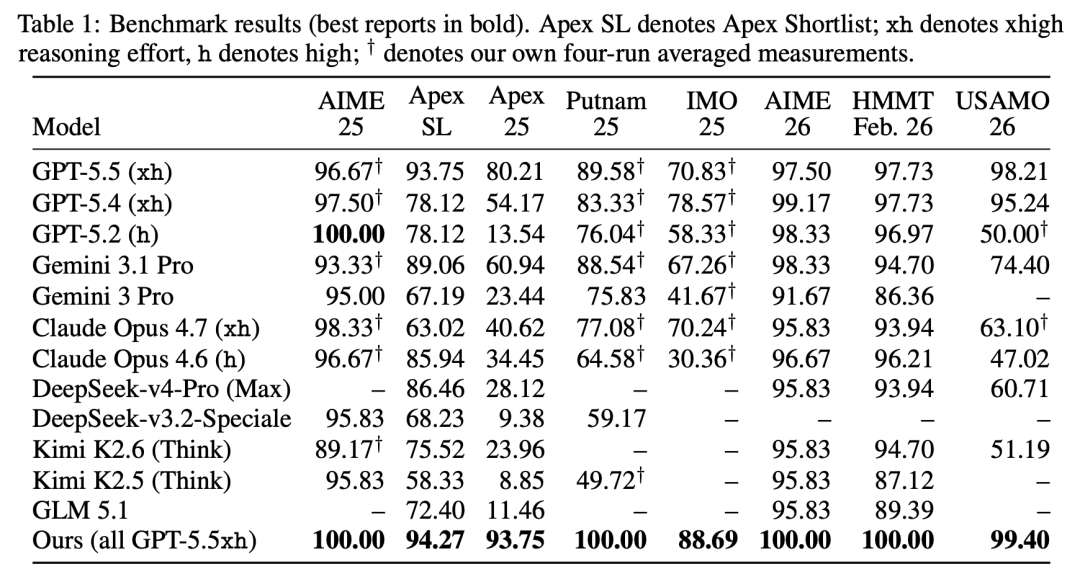
STAR-PólyaMath 在 Apex 2025 上的提升最为显著,达到 93.75%,而直接调用同基座的 GPT-5.5 模型仅为 80.21%,差距达 13.5%。这组问题恰恰是需要多步证明和策略切换的最难问题,也正是 Meta-Strategist 发挥最大价值的场景。
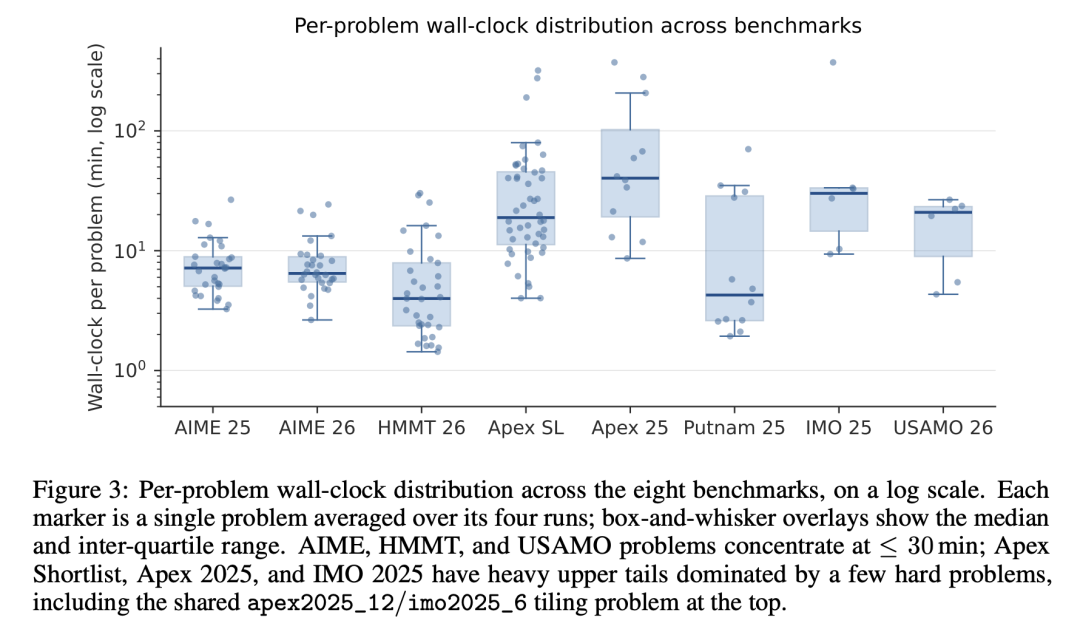
从运行统计来看,计算开销与问题难度高度相关。AIME 级别的问题平均 8 分钟即可完成,100% 在探索阶段就直接解决,几乎不触发 Meta-Strategist。而 Apex 2025 和 IMO 2025 级别的问题平均耗时 55 分钟以上,Meta-Strategist 平均每题介入 1.6-2.2 次。框架不会对简单问题施加不必要的开销,但在真正困难的问题上投入充足的计算资源进行探索推理。
基座模型替换实验清楚地表明性能提升来自结构化推理 harness 框架,而非模型本身。将基座模型从 GPT-5.5 替换为 GPT-5.2 或 Claude Opus 4.7 后,框架仍然在所有基准上超越对应模型的直接调用结果。混合配置(如 Reasoner 用一个模型、Meta-Strategist 用另一个)也未能超越统一配置,说明性能增益主要来自智能体间的协议和循环结构。
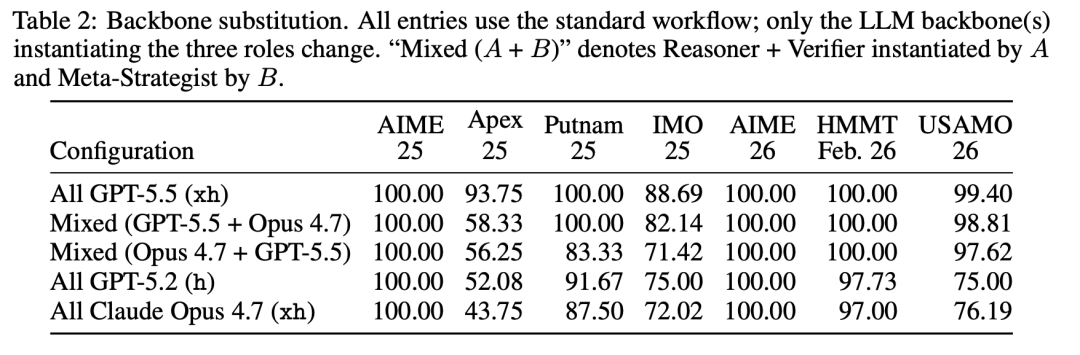
逐一去除 harness 组件的消融实验进一步揭示了各机制的贡献。去掉回溯和重新规划的机制后,IMO 2025 和 Apex 2025 的得分在所有消融设置中损失最大,说明跨步骤错误恢复对长程推理的关键性。去掉 Meta-Strategist 的持久记忆(每次介入都是新会话、不保留历史),IMO 2025 比完全去掉 Meta-Strategist 还低,说明无记忆的干预反而引入了无效噪声。不允许 Reasoner 对 Verifier 的质疑进行辩护后,Putnam 2025 从 91.67% 跌至 75%,表明双向辩论对证明类任务尤为重要。

五、超越数学:一种可泛化的推理范式
在前沿模型已经具备足够的知识和推理能力的前提下,越来越多人意识到制约其在长程任务上表现的瓶颈在于 harness 设计和结构化思考。STAR-PólyaMath 的设计并不依赖数学领域的特殊性质。其核心机制(将长程任务分解为可验证的子步骤、结构化检验每一步的正确性、跨尝试记忆、高层次监督和经验性指导)本质上适用于任何需要长程、可回溯、可验证推理的场景。
例如,在代码生成中,一个类似的框架可以将「生成-测试-调试」循环结构化为带有回溯的状态机,其中 Meta-Strategist 可以在反复修补失败后判断「当前架构方向本身有问题,需要重写」。在科学发现中,Reasoner 对应假设的提出和实验设计,Verifier 对应实验结果的审查,Meta-Strategist 则在多轮假设失败后综合判断「应该修正实验方法还是底层假设」。
该项目已开源完整的代码框架、所有角色的 prompt 和 skill 定义、运行配置,便于社区将这套推理协议迁移到其他领域。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com










