点击下方卡片,关注【Xbotics具身智能实验室】公众号
更多具身干货,欢迎加入(戳我)
👉具身智能学习资料汇总:https://github.com/Xbotics-Embodied-AI-club/Xbotics-Embodied-Guide
👉具身智能求职/实习信息汇总:https://github.com/Xbotics-Embodied-AI-club/Xbotics-Embodied-AI-Job
你想要的这里都有~~
具身智能是一场肉眼可见的万亿生意,融资月月刷屏。但如果你去问那些真正在工厂、仓库、家庭场景里部署过机器人的工程师,他们会告诉你一个尴尬的事实:
同一个模型,在实验室固定工位上成功率95%,换一个相机角度、换一个机器人底座位置、甚至只是把桌子挪了20厘米,成功率就可能腰斩。
这不是某个模型的bug,而是当前整个VLA技术路线的系统性问题。而这个问题,正在成为具身智能商业化落地最被低估的障碍。
在讨论这个问题怎么解决之前,有一个重要的产业节点值得先讲清楚。
BEV进入具身:一个被低估的产业转折点
在自动驾驶领域,BEV(Bird's-Eye View,鸟瞰图)早已成为标配。2019年前后,特斯拉和一批自动驾驶公司发现,与其让模型分别处理多个摄像头的透视图,不如先把所有传感器信息“提升”到一个统一的俯视空间里,再做检测、跟踪和规划。这个转变,直接推动了自动驾驶感知系统的代际升级。
但在机器人操作领域,BEV长期缺席。
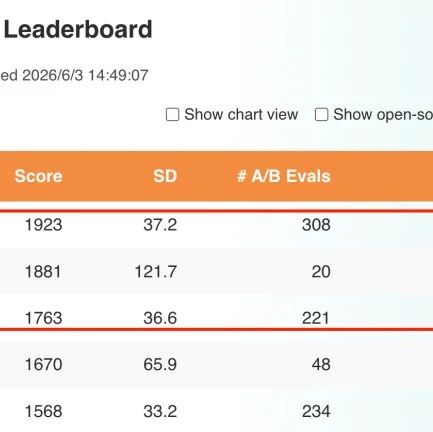
直到Dexterity-BEV这项工作出现,BEV才首次被系统性地引入具身智能的策略学习。这个引入,直接改写了具身智能的底层游戏规则。论文作者是跨维智能的算法团队。就在上周,正是这支队伍在WorldArena Track 2赛道正面硬刚英伟达、谷歌,以明显分差登顶全球第一。
在BEV进入具身之前,VLA模型本质上是在二维图像上做操作决策。 多视角图像各说各话,相机动一动模型就懵。BEV的引入,相当于给具身智能装上了一套“空间操作系统”——所有相机观测、所有机器人动作,都被投影到同一张俯视工作底图上。视角变化被归一化,坐标系混乱被统一。
可以说,这次将BEV引入具身,让整个赛道从此进入了一个新的快车道。 如果说之前的VLA是在“照片上做动作”,BEV引入后的VLA开始真正在“空间里做动作”。这条路线一旦跑通,异构机器人共享策略、跨场景零样本泛化,就不再是口号,而是有了工程底座。
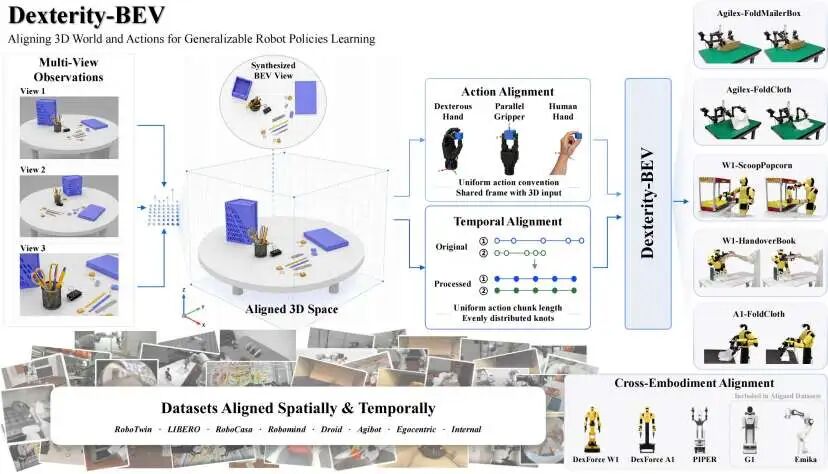
BEV整体架构图
从这个节点出发,我们再来看VLA当前面临的问题和解决路径,会看得更清楚。
VLA的“降维打击”,打到了自己身上
过去两年,VLA模型的快速崛起,很大程度上得益于2D视觉语言模型的溢出效应。π0、Gr00t这些头部模型,无一例外都继承了互联网规模预训练的VLM作为backbone。
这条路线的逻辑是清晰的:既然大模型已经在互联网图文上学会了理解“杯子”、“桌子”、“倒水”这些概念,那再往上接一个action head,理论上就能让机器人看懂图片并输出动作。
但这个逻辑有一个隐蔽的裂缝。VLM擅长的是语义理解,不是几何推理。
它知道你面前的是“杯子”,但很难精确判断杯子相对于机械臂末端的三维位置。而机器人操作恰好是一个几何问题——你差5毫米,抓取就失败了。你差5度,拧瓶盖就滑了。
更致命的是,真实部署中,相机位置、机器人底座、桌面布局几乎不可能保持训练时的状态。而RGB图像对视角变化高度敏感:同一个杯子,正前方拍摄在图像中间,斜上方拍摄可能在左下角。对纯2D模型来说,这是完全不同的输入分布。
这就是为什么BEV的引入如此关键。 它从根本上改变了输入表示的性质:不再让模型面对一堆视角各异的透视图,而是让所有观测先映射到同一张俯视空间地图上。这个转变,让模型从“死记相机角度”的困境中解脱出来,开始学习真正的空间关系。
坐标系混乱:跨本体泛化的隐形天花板
如果说视角问题是感知层面的障碍,那坐标系混乱就是控制层面的更深层问题。
不同机器人厂商、不同数据集、不同实验室,对同一个“抓取”动作的表达方式可能完全不同。有的用7个关节角,有的用末端执行器的6DoF位姿,有的相对于机器人base frame,有的相对于桌面world frame,有的左右臂各用各的局部坐标系。
这就好比,同样一句话“往左走三步”,在不同的地图软件里,指向的是完全不同的目的地。因为每个软件对“左”的定义不一样。
在双臂机器人场景中,这个问题更严重。左右臂往往各自拥有独立的子坐标系,它们之间的base offset无法被模型直接感知。模型不得不从数据里“猜”左右手之间的空间关系。
这带来一个反直觉的结论:在很多情况下,堆更多数据不一定让模型更强,反而可能把更多无关的坐标差异喂进去,让模型更困惑。
而Dexterity-BEV通过BEV的引入,给出了一个根本性的解法:把动作也翻译成BEV底图上的绝对位姿,让不同机器人、不同数据集的“抓取”变成同一个数学语言。这个让无数团队掉坑的隐形天花板,第一次被系统性地炸掉了。
Dexterity-BEV 的产业启示:建一层“空间翻译层”
Dexterity-BEV的核心思想可以浓缩成一句话:不放弃2D VLM的预训练红利,但在输入和输出之间强制插入一层3D空间对齐。
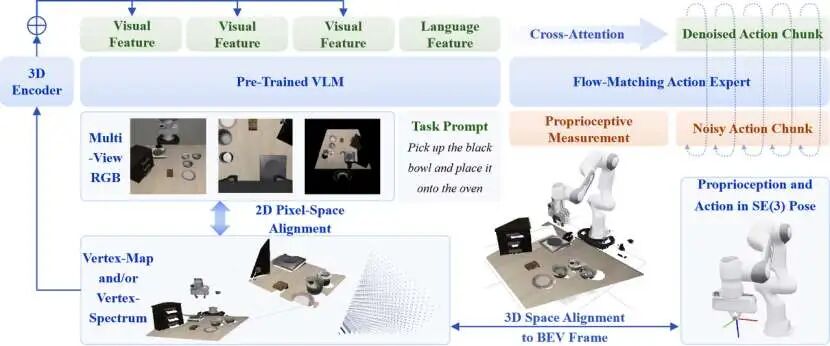
BEV如何通过顶点图和顶点谱,在2D基础上加入3D位置信息
首先,它给每一个RGB像素补充三维坐标信息。利用深度图和相机内外参,把每个像素点反投影到真实三维空间中,形成aligned vertex map。不同相机看到的同一个物理点,在这个map里被映射到同一个空间位置。
其次,它选择BEV作为统一的“工作空间底图”。把多相机观测投射到一个俯视平面上,形成一张标准化的BEV image。这是BEV首次被用于机器人操作策略学习。 无论相机从什么角度拍摄,这张俯视图都保持稳定——杯子在桌面上的位置、机械臂和物体的相对关系,一目了然。
最后,也是最关键的一步:把机器人的动作也翻译成这张底图上的绝对位姿。
从产业角度看,这相当于在所有异构机器人之上建了一层统一的“空间翻译层”,让整个赛道从此进入了一个新的快车道。让整个行业看到了一个清晰的路径:如果这套管线能够固化,异构机器人就可以共享策略,极大地降低从一个本体迁移到另一个本体的成本。
未来竞争:数据集的“几何一致性”决定模型上限
Dex-BEV这篇文章最重的工作在数据处理pipeline。
它涉及相机内参外参的统一标定、GUI手动3D对齐、ICP点云配准、用视觉基础模型补全缺失深度、注册高质量URDF模型、统一TCP定义、对轨迹做跨数据集的时间和空间重采样……
这些东西毫无性感可言,但它们是将来把竞争对手直接关在门外的铜墙铁壁。未来机器人数据集不能再只存RGB图像、语言指令和动作标签了。一个真正可用的高质量数据集,至少应该包含:相机内外参、深度图或可恢复的深度信息、机器人URDF、统一TCP定义、末端执行器在统一坐标系下的SE(3)轨迹、多视角时间同步信息。
以后标注数据,不能只标“成功了还是失败了”,还必须标“在以什么坐标系、相对于哪个参考系做动作”。谁有能力把多来源、多形态、多机器人平台的数据,清洗和重构成几何一致的高质量样本,谁就能在基础模型竞争中占据难以撼动的高点。模型结构可以追赶,但数据管线的工程量、经验积累和工具链成熟度,不是短期能复制的。
现实门槛与演进方向
当然,Dexterity-BEV当前的方案也有门槛。
它依赖相对完善的相机外参标定。在完全非结构化的环境中,外参标定本身就是一个难题。
下一步的关键突破方向是calibration-free BEV lifting——让模型通过端到端学习或结合视觉基础模型,自动恢复相机参数和空间结构,减少对显式标定硬件的依赖。
但论文作者也给出了一个非常诚实的判断:目前视觉基础模型的精度,距离可靠、实时、反应式的机器人控制还有距离。它们可以帮助补全数据,但暂时不能完全取代管线式的几何对齐。
这个判断本身就是有价值的。它告诉行业:短期内,工程化的数据管线仍然是必须投入的硬功夫。
结语
具身智能行业正站在一个残酷的分水岭上。之前还在疯卷模型参数,真正的赢家已经在疯狂搭建数据空间基础设施。
跨维这次将BEV系统性地引入具身,并为此构建了从3D对齐到统一SE(3)动作表示的完整管线,本质上是在定义这波万亿浪潮的底层操作系统。
这不只是一篇论文,而是一张通往真实规模化部署的门票。 从此以后,谁能用几何一致的标准化数据喂出跨本体、跨场景的通用策略,谁就能吃掉具身智能最大的一块蛋糕。
这听起来不够惊艳,但这就是最深的护城河,也是最值钱的护城河。
跨维智能的Dexterity-BEV在真实双臂机器人平台测试视频
-END-
Ask Me Anything|提问箱
❝对文章有疑惑,或想聊更深?欢迎把你的问题丢给我们:技术方案、实操踩坑、课程与资料、项目合作、职业发展,都可以问。
怎么问:在评论区留言,或私信公众号
我们会做什么:每周集中整理高质量问题并公开回复,重点问题邀请作者或嘉宾深度解答;典型问题会加入知识库并持续更新。
提问小提示:尽量说明「你的目标—当前做法—期望产出」,附上必要信息(硬件/软件版本、数据规模等),能更快获得有用答案。
一起把问题变成知识,推动社区进步 🚀