点击下方卡片,关注「3D视觉工坊」公众号
选择星标,干货第一时间送达
来源:3D视觉工坊
星球内有20多门3D视觉系统课程、3DGS独家系列视频教程、顶会论文最新解读、海量3D视觉行业源码、项目承接、求职招聘等。想要入门3D视觉、做项目、搞科研,欢迎加入!
3D头像重建是虚拟现实和数字娱乐的核心技术。然而,现有方法要么需要针对每个受试者进行数小时优化,要么依赖昂贵的预处理流程——计算成本高昂、可扩展性受限、难以快速部署。
研究团队提出FFAvatar方法,一种可泛化的前馈框架,能够从少样本无姿态肖像图像在秒级时间内重建高质量、可动画的3D高斯头像。该方法通过多视图Query-Former融合多源图像信息,并通过端到端预测的FLAME参数实现动画控制。
研究团队提出FFAvatar方法,一种可泛化的前馈框架,能够从少样本无姿态肖像图像在秒级时间内重建高质量、可动画的3D高斯头像。该方法通过多视图Query-Former融合多源图像信息到统一的规范高斯表示,并通过端到端直接从像素预测的FLAME参数实现动画控制。FFAvatar无需针对每个受试者进行优化,显著降低了计算成本,同时保持了高质量重建和精确动画能力。该方法为快速3D头像重建提供了新的技术突破,推动虚拟现实和数字娱乐应用发展。
论文信息
标题:FFAvatar: Few-Shot, Feed-Forward, and Generalizable Avatar Reconstruction
作者:Thuan Hoang Nguyen, Jiahao Luo, Yinyu Nie, Hao Li, Gordon Guocheng Qian, Jian Wang
机构:Nanyang Technological University
原文链接:https://arxiv.org/abs/2605.15320
导读
头像重建传统上依赖针对每个受试者的优化,需要数小时计算,或依赖昂贵的预处理流程,限制了可扩展性。本文引入FFAvatar,一种可泛化的前馈框架,能够从少样本无姿态肖像图像在秒级时间内重建高质量、可动画的3D高斯头像。FFAvatar通过多视图Query-Former融合多源图像信息到统一的规范高斯表示,并通过端到端直接从像素预测的FLAME参数实现动画控制。该方法无需针对每个受试者进行优化,显著降低了计算成本,同时保持了高质量重建和精确动画能力。
效果展示
FFAvatar 模型的三阶段训练流程。首先开展可扩展预训练,基于自研大规模数据集 MFHQ-1M(单身份多帧数据集)训练,提升模型对未知身份的泛化能力;其次进行多视图微调,在小规模 360° 多视角采集数据集(如 Ava256 [18])上优化预训练权重,提升几何还原精度;最后执行轻量个性化适配,仅需数百步调参,在单张 A100 显卡上耗时不足 7 秒,即可有效强化目标身份特征的保真效果。

引言
头像重建是计算机视觉和图形学的核心研究课题,在虚拟现实、数字娱乐和人机交互等领域具有重要应用价值。近年来,3D高斯泼溅技术为头像重建带来了新的机遇,提供了高效渲染和高质量重建能力。
然而,现有方法要么需要针对每个受试者进行数小时优化,要么依赖昂贵的预处理流程,限制了可扩展性和快速部署能力。传统优化方法虽然能够获得高质量重建,但计算成本高昂,难以扩展到大规模应用。前馈方法虽然能够快速重建,但往往需要姿态信息或大量训练数据。
为了解决这些问题,我们提出FFAvatar方法,一种可泛化的前馈框架,能够从少样本无姿态肖像图像在秒级时间内重建高质量、可动画的3D高斯头像。

主要贡献
为了解决快速3D头像重建的挑战,我们提出了FFAvatar方法。具体来说,我们的主要贡献如下:
• 我们提出了一种可泛化的前馈框架,能够从少样本无姿态肖像图像在秒级时间内重建高质量、可动画的3D高斯头像。
• 我们设计了多视图Query-Former模块,融合多源图像信息到统一的规范高斯表示,实现信息高效整合。
• 我们实现了端到端FLAME参数预测,直接从像素预测动画参数,无需额外姿态估计步骤。
方法
FFAvatar方法的核心是采用前馈架构进行快速3D高斯头像重建。多视图Query-Former模块融合多源图像信息到统一的规范高斯表示,实现信息高效整合。
具体来说,我们首先从少样本无姿态肖像图像提取视觉特征,然后通过多视图Query-Former模块融合特征到规范空间。规范高斯表示附着于FLAME头部模板,支持精确动画控制。
FLAME参数预测模块端到端直接从像素预测动画参数,无需额外姿态估计步骤。该方法支持实时渲染和高质量动画,显著降低了计算成本。

实验结果
我们在多个数据集上验证FFAvatar方法的性能,评估重建质量、动画能力和计算效率。
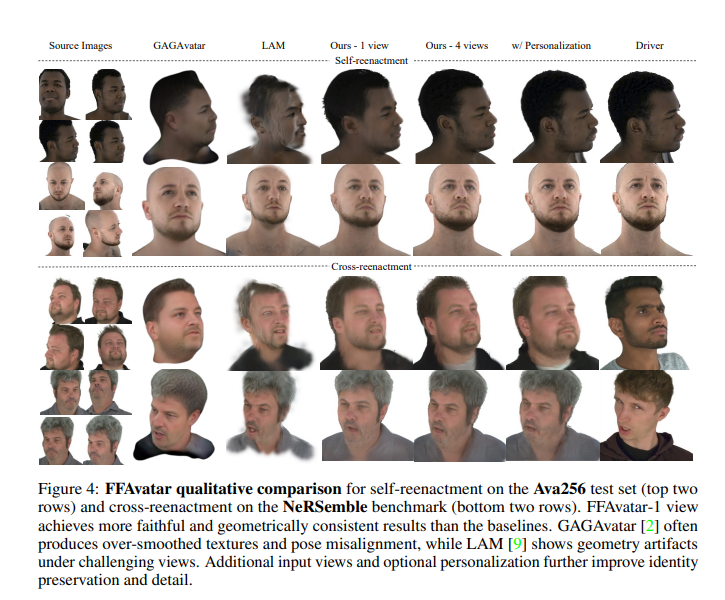

重建质量对比表明,FFAvatar在几何细节和纹理质量方面与优化方法相当,但计算时间显著缩短至秒级。
动画效果展示显示,FFAvatar生成的头像能够通过FLAME参数实现精确表情和姿态控制,动画质量优异。
总结 & 未来工作
在本文中,我们提出了FFAvatar方法,一种可泛化的前馈框架,能够从少样本无姿态肖像图像在秒级时间内重建高质量、可动画的3D高斯头像。该方法通过多视图Query-Former融合多源图像信息,并通过端到端FLAME参数预测实现动画控制。FFAvatar为快速3D头像重建提供了新的技术突破。
未来的工作将致力于扩展FFAvatar到更多头像类型和动画场景。我们计划探索更高效的融合方法,进一步减少计算开销。此外,我们将研究如何将该方法与实时交互技术结合。
对更多实验结果和文章细节感兴趣的读者,可以阅读一下论文原文~
本文仅做学术分享,如有侵权,请联系删文。
。




添加微信:cv3d001,备注:姓名+方向+单位,邀请入群。










