一、引言
- 定义
:机器学习(ML)通过数据、模型和损失函数的结合,实现 “试错” 原则,不断基于预测误差优化模型。 - 应用
:影响日常生活(如智能手机推荐)和科学工程领域,以空前速度和规模改变人类生活。 - 与其他领域的关系
- 线性代数
:使用欧几里得空间表示数据和模型,支持高效计算。 - 优化
:将 ML 问题转化为优化问题,通过最小化损失函数求解。 - 信息论
:用于分析和设计可解释 ML 方法,涉及通信问题类比。 - 概率与统计
:将数据视为独立同分布随机变量的实现,基于概率分布进行推理。 - 人工智能
:ML 是 AI 的重要工具,用于提取信息和学习行为假设。
二、机器学习的三个组成部分
- 数据
- 数据点
:由特征(低层次属性,易测量)和标签(高层次属性,难测量)组成。 - 特征空间
:通常为,包含所有可能的特征向量。 - 标签空间
:分为数值型(回归问题)和离散型(分类问题)。
- 定义
:包含计算可行的假设映射,用于从特征预测标签。 - 参数化假设空间
:如线性映射,通过参数向量表征。 - 有效维度
:衡量假设空间大小,影响过拟合风险。
- 作用
:量化预测标签与真实标签的差异。 - 常见类型
:平方误差损失(回归)、0/1 损失、 hinge 损失、逻辑损失(分类)。
三、主流机器学习方法
- 线性回归
:使用线性假设空间和平方误差损失,通过最小化平均损失学习参数。 - 多项式回归
:通过特征映射将线性回归扩展到非线性关系,如多项式特征。 - 逻辑回归
:用于二分类,使用逻辑损失和线性假设空间,等价于最大似然估计。 - 支持向量机(SVM)
:通过铰链损失和正则化项,最大化分类间隔,处理线性不可分数据。 - 决策树
:通过树形结构实现分段常数映射,易解释,可能过拟合。 - 深度学习
:使用人工神经网络(ANN),含多个隐藏层,可近似复杂非线性映射。 - 聚类方法
:无监督学习,如 k-means,将数据分为相似子集,基于欧氏距离或相似度。
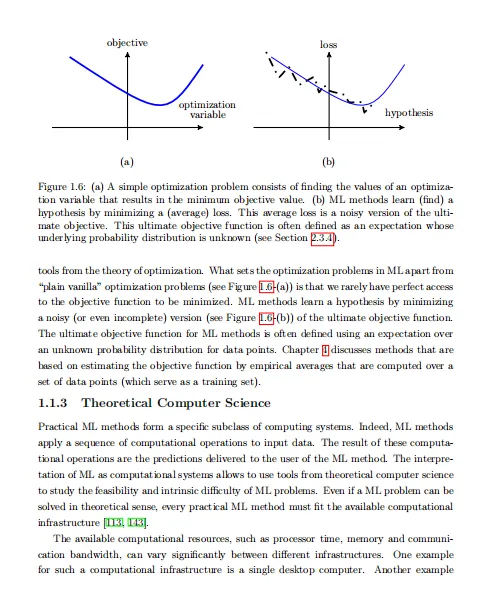
四、经验风险最小化(ERM)
- 原理
:通过最小化训练集上的平均损失(经验风险)近似最小化期望损失。 - 实现
:转化为优化问题,如线性回归中最小化平方误差。 - 挑战
:过拟合(训练误差小但泛化误差大),需结合验证和正则化。
五、梯度下降
- 基本步骤
:通过梯度方向迭代更新参数,,为学习率。 - 变体
:随机梯度下降(SGD)、小批量 SGD,适用于大规模数据。 - 关键参数
:学习率(影响收敛速度和稳定性)、停止准则。
六、模型验证与选择
- 验证方法
:将数据分为训练集和验证集,通过验证误差评估模型泛化能力。 - 交叉验证
:如 k - 折交叉验证,减少数据划分随机性影响。 - 模型选择
:基于验证误差选择最优模型(如多项式阶数、聚类数)。 - 过拟合诊断
:训练误差远小于验证误差时发生过拟合。
七、正则化
- 目的
:防止过拟合,通过添加正则项限制模型复杂度。 - 方法
:岭回归(正则化)、Lasso(正则化)、数据增强(隐含正则化)。 - 偏差 - 方差权衡
:正则化参数控制偏差(增大)和方差(减小)的平衡。
八、聚类
- 硬聚类(k-means)
:将数据分配到唯一聚类,交替更新聚类中心和分配,最小化聚类误差。 - 软聚类
:如高斯混合模型,允许数据属于多个聚类,基于概率分布。 - 应用
:数据预处理、可视化,需确定聚类数量。
九、关键概念
- 过拟合
:模型过度拟合训练数据,泛化能力差。 - 泛化能力
:模型对未见过数据的预测能力。 - 偏差 - 方差分解
:期望误差 = 偏差 ²+ 方差 + 噪声,指导模型选择。 - 监督 / 无监督学习
:前者使用标签(如分类),后者不使用(如聚类)。






本书免费下载地址
关注微信公众号“人工智能产业链union”回复关键字“AI加油站33”获取下载地址。
【AI加油站】第八部:《模式识别(第四版)-模式识别与机器学习》(附下载)