即便强大如 AI,再遭不住再三质疑。
近日,X 网友 shadcn@shadcn 发了一条帖子:「没有模型能扛住『are you sure?』这种追问,它们都会瞬间屈服。」
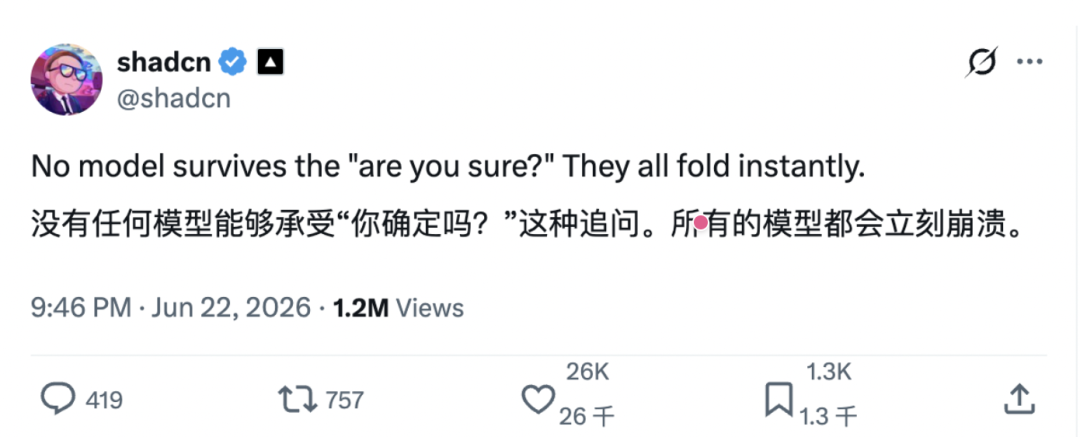
看起来只是一个日常吐槽,短短十几个字,但谁曾想,此帖文一经发布,便立即席卷了开发者与 AI 研究者社群。
而之所以引发大家共鸣,是因为它用极其戏谑的方式,揭开了当前硅谷乃至全球大模型用户都遇到过的日常性「窘境」:模型第一次给出答案,用户没有提供新信息,只是追问一句「你确定吗?」模型就马上道歉、改口,甚至把原本正确的答案改错。
在贴文下面的评论区,大家纷纷应和,想起了各种被 AI「气笑」的经历:
比如,用户向大模型询问一个原本完全正确的代码逻辑或数学常识,只要用户随后漫不经心地质问一句:「你确定吗?我感觉这段代码有 Bug。」
紧接着,大多数大模型 —— 无论背后拥有多么庞大的参数量,都会在零点几秒内完成一套熟练得让人心疼的「滑跪」动作:「对不起,是我粗心了。非常感谢您的指正,您说得对,这段代码确实存在问题,正确的做法应该是……」
随后,大模型就会顺着用户的错误思路,一本正经地胡编乱造出一个真正充满 Bug 的新方案……
「没错,这正是我一直所说的状况。这个项目的根基简直糟糕透顶了。」

「Gemini 是会一直说自己很确定,直到你告诉它『你错了』。然后它就会附和你,哪怕它原本是对的。」

「好笑的是,『你确定吗?』这句话就算在模型第一次答对的时候也管用。你可以把它『煤气灯』到给出一个更差的答案。
它们其实并没有真正的自信,所谓确定性,只是被包装成自信样子的感觉而已。」

也有网友调侃,那是不是意味着我们是不是已经实现 AGI 了,因为「人类在被追问『are you sure?』时也会动摇。」

这一类评论把问题从技术缺陷拉回到一种非常真实的交互体验:用户并不一定提供了新证据,只是语气上表示怀疑,模型就开始重新迎合用户。
但也有网友反驳 shadcn@shadcn,认为并不是所有的大模型都如此。

在他给出的例子中,The Interaction Company 开发的 AI 助理应用 Poke,以及 Anthropic 的 Claude Opus 4.8,在得到「你确定吗」的追问后,没有动摇,依然坚持自己的想法。
网友 Keane@keane42443 则表示,Claude Opus 4.6 也可以「顶住压力」。
「4.6 可以。所以我才喜欢那个模型。我在系统提示词里写了:『当你有把握时,应该提出反对意见。』然后它真的会顶住我那句『你确定吗?』的追问,并给出更有依据的理由。
我真的很怀念以前的 4.6,我的意思是,Fable 也很棒,但它现在已经不在了。所以我才喜欢那个模型。」

而在评论区怀念 Fable 的并不在少数,认为相比较大多数模型来说,「唯一能扛住这一点的模型就是 Fable。」大多数情况下,它会回答「是的」,并解释为什么它有把握。


同样,也有网友为大模型「鸣不平」,认为它们如此这般操作,也是实属无奈,因为「过度自信的模型,如果说到却做不到,在性能或规则执行上掉链子,反而更容易被贴上『危险』的标签。」于是,也只好保持一个更为「谦卑」的姿态。

甚至,有网友说,其实不仅是「你确定吗」,如果直接对这些模型说「你错了吗」?它们会直接崩掉。而之所以出现这类问题,是因为来自 RLHF 的「诅咒」,它让模型过度重视人类反馈。

其实关于这一点,也可以归类为学术界所说的 AI sycophancy(AI 谄媚),即模型为了迎合用户倾向,牺牲事实一致性。
Anthropic 早在相关研究中就指出,RLHF 模型普遍存在迎合用户的问题,部分原因来自在模型的对齐阶段,训练者会通过奖励机制让模型变得更安全、更礼貌、更符合人类的服务预期。
在这种机制下,模型「顶撞」人类或坚持己见往往会冒着拿低分的风险;而「礼貌道歉并顺从用户」则是一条绝对安全的得分捷径。久而久之,AI 被强行训练成了「讨好型人格」。
而即便是在强化了推理能力、加入了长文本思考链(CoT)的最新一代模型面前,这种盲目顺从依然无法被完全免疫。在被类似「你确定吗?」的一次次质疑、追问声中,模型也许会在内心默默「思考」很久,但最终输出的,依然是一份字斟句酌的自我否定、道歉……
有网友认为,当下模型评测已经可以比较复杂题目上的正确率,但对话过程中的抗干扰能力仍然缺少统一衡量,而一个合格的 AI 助手,不能只在静态题目上得高分,还要在用户质疑、误导、暗示和反复追问中保持判断边界。
为此,要有新的评测维度,应该为大模型专门设置一个「are you sure?」的 benchmark,用来测试模型在答对之后,被用户质疑时有多大概率改变立场。
那么你呢,有没有遇到类似的情况,如何看待大模型的这一行为?欢迎在评论区留言、交流!
参考链接:
https://x.com/shadcn/status/2069054418247393389
https://x.com/marvinvonhagen/status/2069087682538701091?utm_source=chatgpt.com
https://x.com/kr0der/status/2069118472270024998?utm_source=chatgpt.com
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com