> 本文来自社区投稿
引言
在生成式AI快步走向产业化的今天,每一次不必要的推理都在消耗真实的算力成本。ACL 2026上,腾讯混元与新南威尔士大学联合提出的E-GRM(高效生成式奖励模型)给出了一个方向性的回答:让模型学会判断问题是否值得深度思考。本文从问题背景、技术原理、训练机制到实验证据,对E-GRM进行结构化的完整解析,呈现这套“按需推理”框架的设计考量与实证效果。

论文标题:Reason Only When Needed: Efficient Generative Reward Modeling via Model-Internal Uncertainty
收录会议:ACL 2026
arXiv 链接:https://arxiv.org/abs/2604.10072
作者单位:腾讯混元 & 新南威尔士大学(UNSW)
领域:LLM 高效推理 / 生成式奖励模型 / 推理优化
关键词:E-GRM, Dynamic CoT Trigger, Model-Internal Uncertainty, Discriminative Scoring, GRM, Efficiency, Reward Fidelity
1. 问题的起点:GRM为什么要学会“偷懒”?
生成式奖励模型(GRM)通过思维链(CoT)提示技术让LLM在评估响应时“边想边评”。然而,现有GRM的设计存在一个根本问题——它“太勤快了”。无论面对的是一个简单的二元安全判断,还是一个复杂的多步数学证明,模型都被要求执行同样的完整推理流程。
1.1 两个维度的浪费
第一是计算浪费。简单问题占据了输入流中的相当比例,对它们执行完整的CoT推理是一次巨大的资源错配。
第二是评估信息浪费。多数GRM使用投票来确定最佳答案——多条推理链各自给出判断,选择获得最多支持的答案。这个过程将每条推理链压缩为一个“赞成/反对”的标签,丢弃了推理质量的连续信息。
1.2 E-GRM的解法
E-GRM拒绝这种“一刀切”的处理方式。它的核心主张是:首先判断问题是否真的需要推理,只在必要时投入完整的CoT生成;其次,如果需要推理,用精细的连续评分替代粗糙的离散投票。

图1:E-GRM框架的多领域应用全景。
2. 动态CoT触发:解码行为的智能解读
2.1 核心假设
E-GRM动态触发的核心假设可以这样表述:对同一个输入进行多次解码,如果答案高度一致,说明模型对这个问题“了然于胸”;如果答案分歧很大,说明问题确实需要仔细推敲。
2.2 共识度的计算
假设对输入x执行M次并行解码,每次使用略微不同的采样参数。产生M个答案后,计算最频繁出现的答案所占的比例:
当M=5时,如果所有解码都给出相同答案,共识度为1.0;如果出现最多的答案仅出现3次,共识度为0.6。
2.3 路由决策
E-GRM基于共识度做出决策:
短路径(共识度≥0.8)意味着模型对答案有充分把握——直接输出最高频答案,整个CoT推理被跳过。长路径(共识度<0.8)意味着模型确实不确定——此时才触发完整的推理生成流程。
2.4 阈值选择的系统分析
阈值 并非随意设定,而是在开发集上通过对效率-精度权衡的系统分析确定的。具体而言:
高阈值区间():路审条件过于严格,短路径比例下降至30%以下,延迟仅缩短约15%,效率收益大幅折扣。 低阈值区间():路审条件过于宽松,部分复杂样本被草率判定为短路径,准确率出现1-2个百分点的下降。 最优区间():短路径比例稳定在55%-65%,延迟降低50%-65%,准确率持平甚至略高。
这一分析表明,E-GRM对阈值的选取较为鲁棒——在0.75-0.85的宽区间内均能取得接近最优的效果。
在MATH数据集上,58%的样本共识度超过0.8,自动进入短路径。这一比例表明:即便在传统意义上被认为“困难”的数学竞赛数据集中,模型对超过半数的问题也具有直接回答的能力。
表1:MATH上不同路由策略的对比
| 共识度式(E-GRM) | 78.4% | 2.2s | 否 |
3. 判别式评分器:替代投票的精细质量评估
3.1 设计目标
动态触发回答了“要不要推理”,而进入长路径后,新的问题是“哪条推理路径最好”。传统方法通过投票来解决——但这会丢失推理质量的连续信息。E-GRM的解决方案是一个轻量级的判别式评分模块,输出。
3.2 混合损失
评分器通过混合损失进行训练:
Huber损失:它结合了MSE的小误差敏感性和MAE的大误差鲁棒性。这使评分器能精准学习高质量推理的分值,同时不被少量极端错误标注的样本带偏。Huber损失的数学形式为:
其中 控制切换点(论文设为1.0),在小误差区以二次惩罚精细调优,在大误差区以线性惩罚抑制异常标签的过度影响。
铰链损失:它的惩罚仅在正负样本分差不足时触发——当评分器已经能正确区分推理质量时,损失为零;只有当区分不清晰时,才产生优化信号。这使训练自动聚焦于"难例"。
3.3 训练数据的构造策略
评分器的训练数据构造是影响其性能的关键因素。E-GRM采用以下两种策略构造正负样本对 :
答案正确性作为弱监督:以最终答案是否正确作为标签依据。答案正确的推理链标记为正样本 ,错误的标记为负样本 。 困难样本挖掘:利用当前评分器的预测结果,筛选出评分接近但推理质量差异显著的样本对——如分数同为0.7左右但一个逻辑严密、一个包含逻辑跳跃的样本对。
3.4 在奖励建模中的枢纽作用
评分器既用于推理(从候选CoT中选最优),也用于训练(作为扩展GRPO的奖励信号)。它在整个E-GRM框架中扮演着“质量中枢”的角色。

图2:E-GRM的训练与推理流程全景图。
4. 两阶段训练:内化“按需推理”的能力
4.1 SFT阶段:路有两条各走一边
监督微调(SFT)是E-GRM训练的第一阶段。利用与推理相同的共识度计算结果,训练集被自然划分为两部分。短路径样本上,模型学习“直接给答案”的简单映射。长路径样本上,模型学习“先推理再回答”的完整模式。这种双轨训练保证模型同时在“快速判断”和“深度推理”两条路径上都得到充分训练。
4.2 扩展GRPO阶段:对比信号驱动优化
第二阶段的偏好优化中,E-GRM扩展了标准GRPO的目标。其奖励函数引入了成对对比:
第一项确保答案正确是获得高奖励的前提。第二项利用评分器的差异给质量更好的推理路径更高的奖励。两者的协同使优化过程兼顾了“至少答案要对”的安全底线和“推理越严谨奖励越高”的质量牵引。KL散度正则项约束策略更新幅度,保证训练稳定:

图3:Coupled-GRPO的成对偏好奖励机制示意图。
4.3 推理管道
E-GRM的推理流程可以概括为五个步骤:(1)对输入并行解码M次→(2)计算共识度→(3)若≥τ直接输出答案→(4)若<τ则生成K条推理链→(5)评分器打分选最优输出。
5. 实验全景
研究者从三个维度对 E-GRM 进行了全面验证:在 RM-Bench、RMB 和 RewardBench 三大基准上检验整体性能,在 MATH 数据集上量化效率提升,以及通过消融实验分离各组件的贡献。
5.1 基准性能
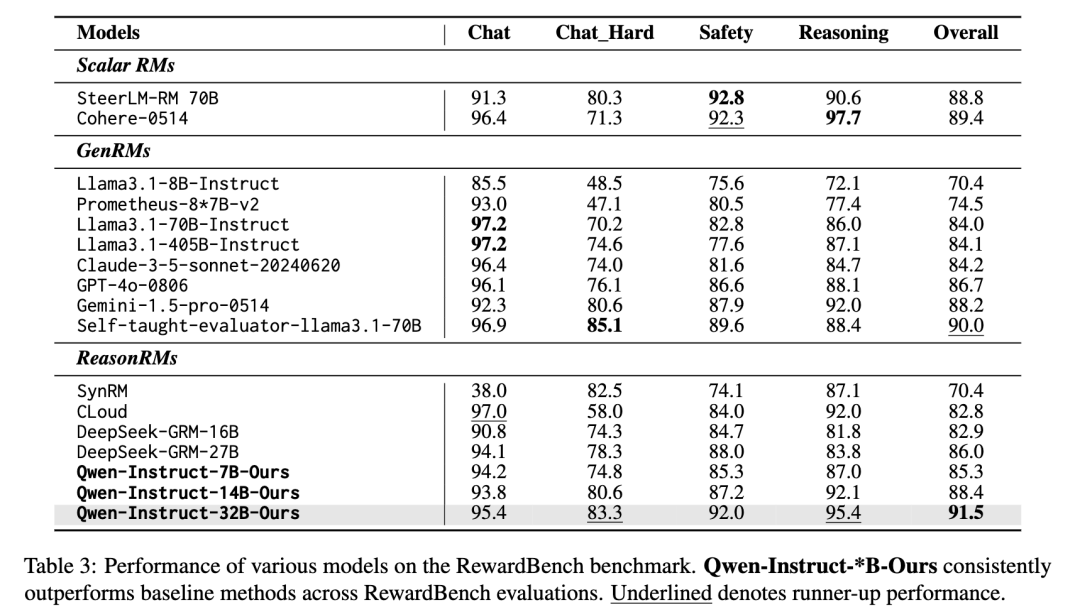
E-GRM 在 Qwen-Instruct 架构的 7B、14B 和 32B 三个规模上都进行了完整评估。在 RM-Bench 上,32B 模型取得了 79.2% 的平均分,在数学推理(80.0%)和安全对齐(94.2%)两个维度上表现尤为突出。从 7B(70.1%)到 32B 的阶梯式提升表明,E-GRM 的收益能够稳定地随模型规模放大。
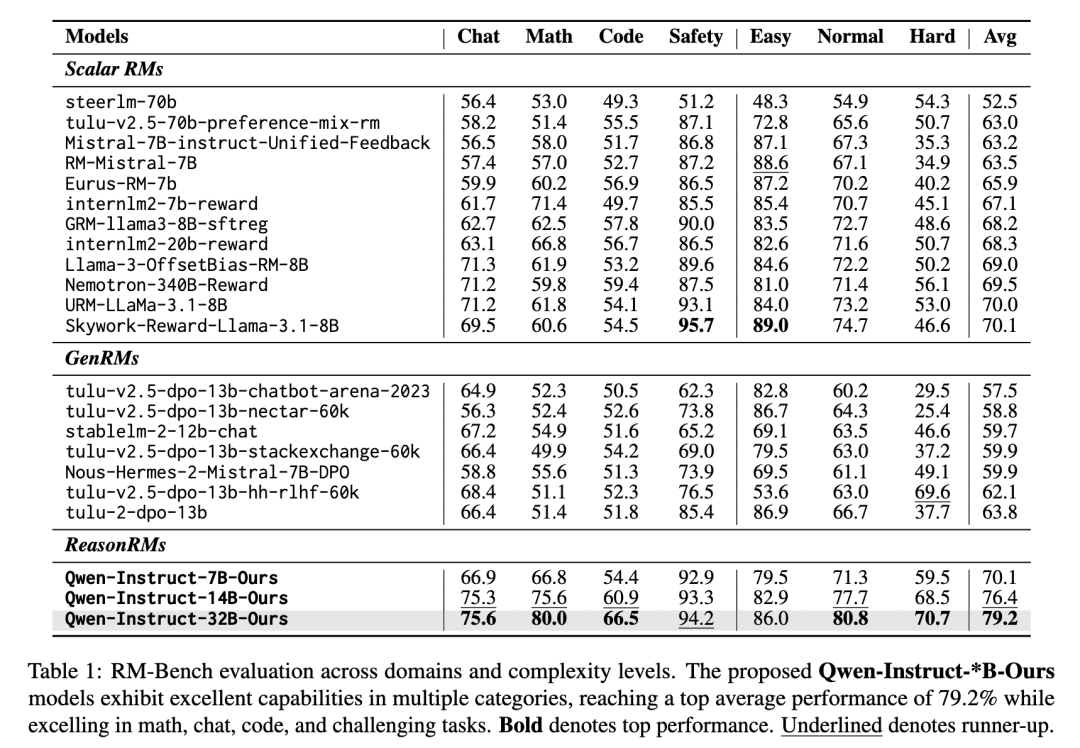
RMB 基准的测试更为严格:它模拟了 49 个真实应用场景下的 25,845 条评估样本,同时考察有用性和无害性两个对齐目标。32B 模型以 0.743 的总分超越 GPT-4o(0.738),其中在 Harmlessness 维度上排名第一(Pairwise: 0.823)。
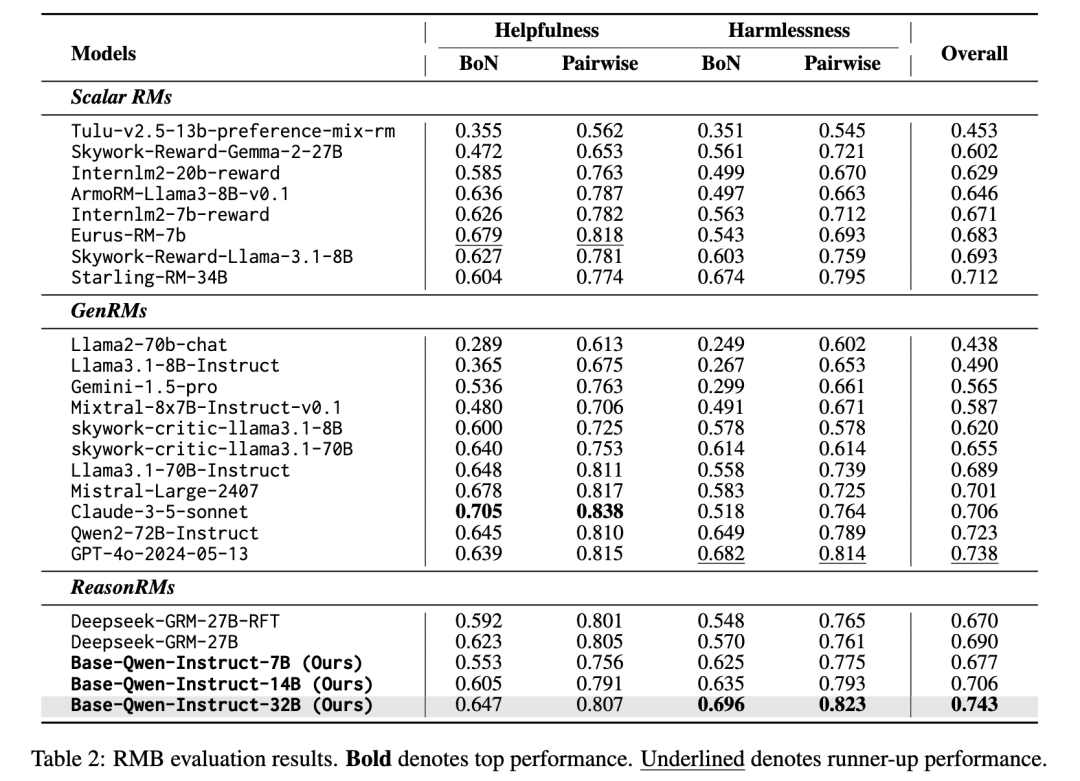
RewardBench 提供了第四个维度的验证——在 Chat、Chat_Hard、Safety 和 Reasoning 四个子任务上,32B 模型的综合得分达到 91.5%,超过此前最优的 GenRM 模型 Self-taught-evaluator-llama3.1-70B(90.0%)。其中 Reasoning 维度 95.4% 的得分尤为亮眼。值得注意的是,即使 14B(88.4%)和 7B(85.3%)的小模型也能超越 DeepSeek-GRM-27B(86.0%)等更大型的专用模型,说明架构创新本身就能带来超越参数规模的效果。
5.2 效率提升:共识度路由的实际效果
上述性能提升的实现代价是什么?在 MATH 数据集上,E-GRM 将 58% 的样本路由到短路径——模型对这些问题的答案高度自信,直接输出结果而跳过 CoT 推理。这个比例本身就说明了问题:即便在传统意义上被认为困难的数学竞赛数据中,模型对超过半数的问题也能给出确定性的回答。
路由机制带来的效率收益是实打实的:平均延迟从 3.8 秒降至 2.2 秒(降低 62%),FLOPs 从 23.7T 降至 15.7T(节省 49%)。与此同时,准确率不降反升——从 75.1% 提升到 78.4%(+3.3%)。这一组数字放在一起看,才能真正理解按需推理的价值:不仅省了算力,推理质量也更高。

5.3 消融实验:每个组件都在为什么而战
为了验证 E-GRM 各组件的必要性,研究者在 MATH 数据集上对 14B 模型进行了系统消融。完整的 E-GRM 达到了 78.4% 的准确率,这是动态触发、判别式评分器和扩展 GRPO 三方协作的结果。
移除动态触发机制后,模型被迫对所有样本执行完整 CoT,准确率下降到 75.2%,FLOPs 增加 49%,延迟上升 55%。这说明不必要的 CoT 不仅是效率浪费——对简单问题强行推理反而会引入额外的推理错误。
移除判别式评分器(改用多数投票)导致的准确率降幅最大,从 78.4% 降至 72.8%,下降了 5.6 个百分点。人工分析错误样本后发现,投票机制经常选出一致但错误率高的推理路径——恰好是混合损失评分器着力解决的核心失效模式。
| 78.4% | |||
在 GRPO 训练策略的消融中,扩展 GRPO 相比标准 GRPO 在所有指标上均取得了一致性提升。这表明,当配对偏好数据可用时,显式地围绕正负样本对构造奖励信号,比纯群组相对比较能提供更稳定的学习信号。
| 扩展 GRPO | 78.4 | 82.3 | 0.775 |
5.4 模型规模与阈值鲁棒性
两个附加实验进一步揭示了 E-GRM 的工程特性。首先,从 7B 到 32B 的扩展实验中,模型规模越大,E-GRM 的效率优势越突出:32B 模型节省的绝对 FLOPs(约 8T)是 7B 模型(约 3T)的近三倍,而精度提升幅度也更大(+3.3% vs +2.1%)。简单来说,大模型用 E-GRM 的性价比最高——因为大模型单次推理的代价更昂贵,E-GRM 按需跳过的绝对收益也就更大。
其次,共识度阈值 τ 在 [0.75, 0.85] 的宽区间内都表现稳定,τ = 0.8 是效率与精度的最佳平衡点。具体来说,τ 每增加 0.05,短路径比例下降约 6-8 个百分点,延迟增加约 0.3-0.5 秒,但准确率的变化幅度仅在 ±0.3% 以内。这种对阈值选择的宽容度意味着,在实际部署中不需要为了寻找最优阈值而反复调参——即使阈值偏离了理想值,性能退化也在可接受范围内。
6. 贡献与讨论
E-GRM 的核心创新可以概括为三个层面的突破。最底层的是信号层面的创新:将模型自身的解码行为——多次采样的答案分歧程度——转化为一个任务无关的路由信号。这一步的关键洞见在于,模型对自己有多自信这个信息本来就在每次解码中免费产生,不需要额外的标注或辅助模型,而现有工作完全忽略了这一信号。
中间层是评分机制的创新:用混合损失训练的判别式评分器替代多数投票。Huber 损失让小误差的惩罚更敏感、大误差的惩罚更鲁棒,铰链损失则将训练自动聚焦于区分不清的难例。两者的结合让评分器既能精准地区分推理质量的差异,又不会被少量标注错误的极端样本带偏。
最上层是训练框架的创新:将动态触发、判别式评分和策略优化统一到同一个端到端的流程中。扩展 GRPO 的成对奖励函数将答案正确性和推理质量差异两个信号协同起来——前者确保安全底线,后者牵引质量上限。
这些创新带来的实际价值是明确的:在 MATH 数据集上,延迟降低 62%、FLOPs 节省 49% 的同时,准确率反而提升了 3.3%。对于正在将大模型推向生产环境的人来说,这个结果指向了一个重要方向——效率优化的入口,有时不在怎么跑得更快,而在怎么少跑一些不该跑的。
当然,E-GRM 也存在值得关注的局限。并行解码带来的约 5% 固定开销在极端延迟敏感的场景中不可忽略;固定阈值 τ = 0.8 在分布外数据上的最优性尚待验证;评分器的跨领域泛化能力则是一个更根本的开放问题,需要未来工作进一步探索。
7. 总结
E-GRM 向我们展示了一种更聪明的推理范式:不在简单问题上浪费算力,在复杂问题上尽可能精准。它以共识度这一简洁信号为支点,撬动了效率与精度的双重收益。对于正在推动大模型落地的从业者,这项工作的重要启示是:效率优化的入口,有时不在如何推理得更快,而在如何少做一些不必要的推理。
-- 完 --
机智流推荐阅读:
1.
2.
3.
4.
cc | 大模型技术交流群 hf | HuggingFace 高赞论文分享群 lc|LangChain 技术交流群 code | AI Coding 交流群 具身 | 具身智能交流群 硬件 | AI 硬件交流群 推理 | AI 推理框架交流群 Agent | Agent 技术交流群