

清晨,你一边听书,一边下意识留意着周围的动静,随时准备回应家人的呼唤。这种对连续声音流的实时感知、决策与响应,是人类与生俱来的交互能力。然而,对于当前的人工智能而言,这却是一个巨大的挑战。
现有的音频大语言模型(LALM)大多遵循着“离线”模式:用户提供一段完整的录音,模型听完后给出一次性的回答。这就像把一场生动的对话压缩成一条短信,失去了声音固有的实时性与交互性。尽管已有一些流式模型专注于单一任务,如实时语音识别或语音对话,但它们彼此割裂,无法像人类一样,在一个统一的“感知-决策-响应”循环中,处理复杂多变、交织着多种声音和指令的实时环境。
为了弥合这一鸿沟,来自新加坡国立大学、南洋理工大学等机构的研究团队提出了一种全新的范式——音频交互模型,并发布了首个统一、全能的实时音频交互模型 Audio-Interaction。它能够像人类一样,持续“倾听”连续的声音流,在每一个时刻基于对语义的理解,自主决定是保持沉默还是进行回应,从而将语音对话、实时转录翻译、音频理解、指令跟随乃至主动预警等多种能力,统一在一个模型中。

论文标题:Audio Interaction Model
论文链接:https://arxiv.org/pdf/2606.05121v1
项目主页:https://xzf-thu.github.io/Audio-Interaction
数据集:huggingface.co/datasets/zhifeixie/StreamAudio-2M
研究背景:从“离线问答”到“实时交互”
声音本质上是实时且交互的媒介。与将事件压缩为符号的文本,或捕捉静态瞬间的图像不同,声音是一个连续、永不间断的通道,人类通过它感知并响应周围环境。近年来,随着大语言模型、强化学习和智能体技术的飞速发展,音频大语言模型也取得了长足进步,能够执行细粒度的情感识别、多步推理甚至代码生成。
然而,当前绝大多数音频大模型仍遵循传统的离线输入-输出模式,即 y = f(x, A),其中A代表完整的音频片段。这种模式与音频的实时交互特性严重不匹配。常见的折中方案是为每个重要任务训练一个专用的流式模型,例如语音对话模型和流式语音识别模型。但这种“一个任务一个模型”的思路存在两个根本问题:一是每个能力都需要从头训练一个独立模型,成本高昂;二是每个模型只能处理狭窄的特定能力。例如,即使是完全流式的对话系统,也可能无法理解一个犹豫的停顿,或识别一声咳嗽。
因此,研究团队认为,是时候超越现有的音频大模型,迈向一个全新的范式:大型音频交互模型。这是一个“全能”的框架,旨在将现有任务统一到单个交互式模型中,并弥合音频大模型的能力与音频的实时性之间的鸿沟。

实现这一范式面临两大核心挑战:
基于理解的响应触发:离线模型被动地对完整音频片段做出响应,而交互式模型必须基于对动态上下文语义的理解(而非表面的声学线索),在每一个音频块处决定是否响应。 分块推理下的实时上下文连续性:为了满足低延迟要求,音频必须被分割成固定长度的块进行处理,但这种分块会破坏声学信号的时间连续性以及交互过程中积累的长距离上下文。
核心创新:Audio-Interaction模型与SOUNDFLOW框架
为了应对上述挑战,研究团队提出了 Audio-Interaction 模型及其背后的 SOUNDFLOW 端到端框架。
Audio-Interaction 的核心是一个持续的“感知-决策-响应”循环。模型以400毫秒为一个块,逐步消费音频流。在每个时间步,模型会做出一个关键决策:输出一个特殊的 <silent>(沉默)词元继续聆听,或输出一个 <response>(响应)词元开始生成回答。这个决策完全基于模型对当前及历史音频内容的语义理解。

在这一循环下,传统的音频能力(如翻译、识别、对话)被自然地统一为交互范式中的指令。更进一步,模型还能实现无需指令、仅基于音频内容触发的主动干预能力,例如在听到玻璃破碎声时发出警告。
支撑Audio-Interaction的是SOUNDFLOW框架,它涵盖了从数据、训练到推理的完整链条:
1. 流式数据构建
传统的音频数据集多为短小的(音频,指令,回答)三元组,不适合训练需要处理长序列、并决定何时响应的流式模型。为此,团队构建了大规模流式原生数据集 StreamAudio-2M,包含260万个样本,总时长超过30万小时,涵盖了7大类核心能力下的28个子任务。
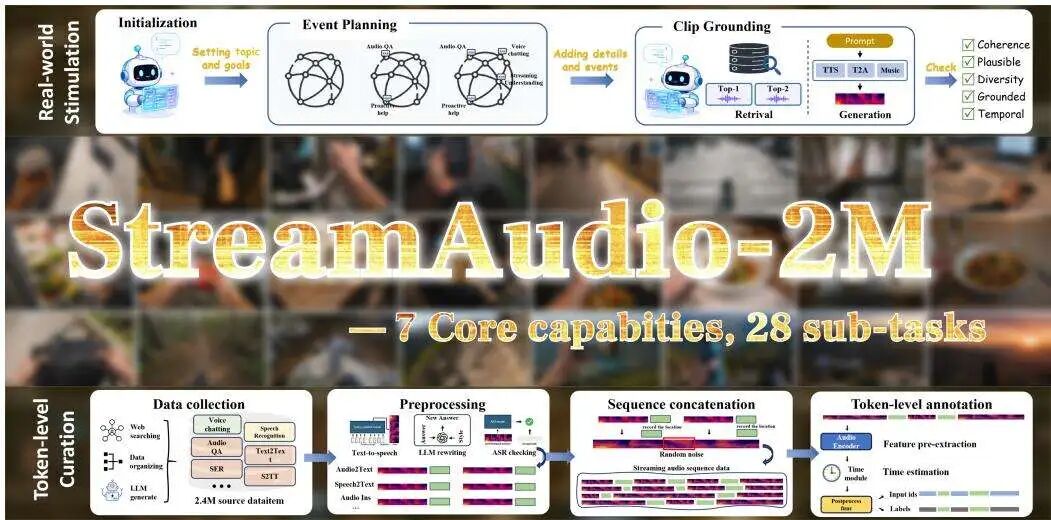
数据构建的关键在于如何将离散的音频片段组织成连贯、符合常识的长序列。研究团队采用了分层事件策划流程:
场景规划:使用大语言模型根据随机匹配的音频标注,规划一个完整的高层场景。 事件细化:将每个场景主题细化为一系列具体的音频事件。 片段落地:通过检索或生成(当检索不到合适片段时)的方式,为每个事件获取对应的音频片段。
此外,团队还设计了时频联合预处理模块,用于平滑每个音频片段的边界、抑制噪声,使其在拼接后听起来更自然、连贯。
2. 交互感知训练
训练过程模拟推理时的流式场景。模型以固定长度的音频块为输入,同时学习两项任务:预测控制词元(沉默/响应)和生成回答文本。研究团队采用了双损失函数进行优化,同时兼顾语言建模和流式控制目标。
为了解决长序列训练中模型容易遗忘早期上下文,以及对非关键声音产生误触发的问题,团队引入了历史回顾训练和理解感知的沉默训练。前者通过在序列后期插入关于前面内容的问题,显式鼓励模型进行长距离上下文检索;后者则引入大量经智能体验证无需响应的静默音频,强化模型“非必要不回应”的能力。
3. 异步低延迟推理
为了实现稳定、低延迟的实时交互,团队设计了基于先入先出队列的异步推理机制。音频编码器和解码器作为两个独立的进程运行,编码器持续处理音频块并将其特征存入队列,解码器则根据自身状态(上一次输出是沉默还是响应结束)决定何时从队列中消费特征并进行预测。这种设计完全消除了推理停滞,并将响应结束后恢复聆听的首帧延迟降低了4.5倍。

实验验证:性能保留与新能力解锁
研究团队在8个主流音频基准测试上对Audio-Interaction进行了全面评估,并与现有的音频大模型、全模态模型以及任务专用模型进行了对比。结果主要体现在三个方面:
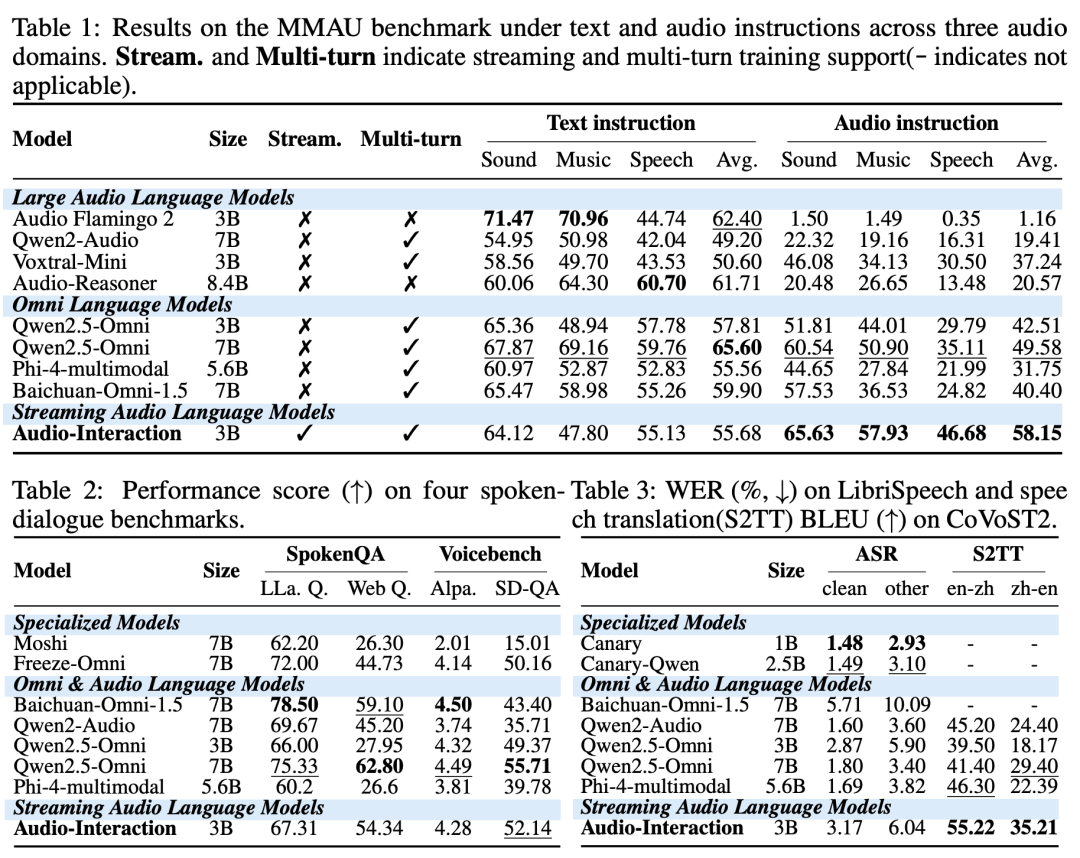
1. 保留了强大的通用音频理解能力
在涵盖声音、音乐、语音的通用音频理解基准MMAU上,Audio-Interaction在音频指令下的平均得分达到58.15,与作为基座的Qwen2.5-Omni-3B模型(57.81)相当,甚至超越了部分70亿参数的模型,证明了流式训练并未损害其核心理解能力。
2. 在核心语音任务上保持竞争力
在语音翻译任务(CoVoST2)上,Audio-Interaction相比基座模型在中英、英中翻译的BLEU分数上分别提升了15.72和17.04分,达到与70亿参数基线相当的水平。在多个语音对话基准测试上,其表现也与基座模型相当或更优。仅在语音识别任务上,由于从话语级识别头转向了分块流式解码器,词错误率有微小上升,这是获得流式能力所付出的可控代价。
3. 解锁了离线模型无法实现的新能力
这是Audio-Interaction最引人注目的优势:
对语音指令的鲁棒性:当指令以音频形式给出时,许多离线基线模型性能骤降,而Audio-Interaction因其架构设计而表现稳定。 选择性的主动响应:在新构建的Proactive-Sound-Bench测试集上,Audio-Interaction在单事件和多事件流上的准确率分别达到61.2%和62.8%,能够平衡地覆盖不同类别的安全事件,并在长音频流中保持稳定性能。 长流交互下的能力稳定性:当测试音频流由多个片段拼接而成时,Audio-Interaction在拼接5段后仍能保持超过91%的单段准确率,而基线模型的性能则下降了30%以上,这体现了原生流式训练带来的内在鲁棒性。
深入分析:模型如何“学会”交互?
除了基准测试分数,研究团队还深入分析了模型内部如何实现从离线到流式的跨越。
观察一:模型在早期解码器层将离散块统一为连续表示。由于每个音频块是独立编码的,编码器输出本身缺乏跨块的时间连续性。量化分析发现,在编码器和投影器层面,块间连续性比率很低(约0.25),而到了第一个GPT解码层,该比率骤升至0.80。这表明,模型通过跨块的注意力机制,在解码的最早阶段就重构了时间的连续性,且这一特性在所有任务中共享,是流式机制本身的性质。
观察二:“沉默/响应”决策依赖于一个关键的注意力头。流式模型需要持续生成控制词元来门控其输出。通过逐个“关闭”模型中的576个注意力头并观察控制词元生成性能的下降,研究人员发现,只有一个特定的注意力头(第35层第14个头)对这项决策至关重要。将其关闭会显著降低所有任务上的控制词元匹配分数。这表明,流式目标通过一个狭窄的、独立于具体任务的通路来路由决策,而非为每个任务设计专用电路。
结语
Audio-Interaction的工作标志着音频人工智能向更自然、更通用的实时交互迈出了关键一步。它首次将“音频交互模型”确立为一个明确的研究范式,并通过SOUNDFLOW框架提供了从数据到部署的完整解决方案。
该研究释放的StreamAudio-2M数据集和Proactive-Sound-Bench评估基准,也将为社区后续的研究提供宝贵资源。未来,随着模型规模的扩大、训练数据的丰富以及交互策略的进一步优化,能够像人类一样“听声辨位”、实时响应的通用音频智能体,或许将很快从实验室走进我们的日常生活。
无论是作为更智能的语音助手、实时翻译工具,还是在家庭看护、工业巡检、智能驾驶等安全关键场景中提供主动的音频感知与预警,Audio-Interaction所代表的交互范式都展现出广阔的应用前景。声音的世界是连续而动态的,与之交互的AI,也终将学会流畅地融入这片声景之中。
-- 完 --
机智流推荐阅读:
1.
2.
3.
4.
cc | 大模型技术交流群 hf | HuggingFace 高赞论文分享群 lc|LangChain 技术交流群 code | AI Coding 交流群 具身 | 具身智能交流群 硬件 | AI 硬件交流群 推理 | AI 推理框架交流群 Agent | Agent 技术交流群










