

你正在剪辑一段视频,需要将背景音乐替换为吉他旋律,同时让人声听起来更低沉、更有磁性,并且不能改变说话的内容。又或者,你需要将一段带有地方口音的中文对话,精准地修改为标准普通话发音,同时保留说话人的音色和节奏。对于专业音频编辑师来说,这些任务虽然繁琐,但尚可完成。然而,如果要求一个AI模型,仅凭一句自然语言指令就自动、精准地完成这些复杂的、多模态的音频编辑,结果会如何?
现实是,尽管AI在图像和视频编辑领域已取得显著进展,但通用化的、基于指令的音频编辑系统仍处于早期阶段,其能力缺乏统一、全面的评估。为此,来自上海交通大学、腾讯混元团队、南洋理工大学等机构的研究者联合推出了 MMAE(Massive Multitask Audio Editing Benchmark) ,这是首个为通用指令式音频编辑设计的大规模多任务评测基准。

论文标题:MMAE: A Massive Multitask Audio Editing Benchmark
论文链接:https://arxiv.org/pdf/2606.07229
开源仓库:https://github.com/ddlBoJack/MMAE
数据集地址:https://huggingface.co/datasets/BoJack/MMAE
研究团队利用MMAE对当前五个先进的音频编辑模型进行了全面评估,结果令人深思:所有模型的“精确匹配率”(即完全无误地执行编辑指令的比例)均低于5%。在涉及声音、音乐、语音混合的复杂任务中,这一比例甚至降为0% 。这清晰地揭示了当前AI音频编辑技术在精确执行与上下文保持之间所面临的巨大挑战。
研究背景:音频编辑智能化的评估困境
近年来,智能编辑技术取得了显著突破。在视觉领域,像Nano-banana 2这样的图像编辑模型和Gemini-Omni这样的视频编辑模型,已经将交互式创作推向了新的高度。受此趋势推动,音频社区也涌现出一批基于自然语言指令进行编辑的模型。用户只需用文字描述需求,如“移除所有观众的欢呼声”或“将背景音乐换成爵士乐”,模型就能尝试对语音、音乐或音效进行修改。
这代表了下一代智能音频生成与编辑系统的发展方向。然而,与之配套的评估体系却严重滞后。现有的评测基准高度碎片化,通常局限于某个特定子领域(如仅针对语音或仅针对音效)或基础操作(如添加、删除)。更重要的是,传统的评估指标(如信噪比、语音识别错误率)难以衡量开放式指令编辑任务的质量。模型是否真正理解了指令?修改是否精确?无关的音频内容是否被完好保留?这些问题都需要更精细、更可靠的评估范式来回答。
MMAE的诞生,正是为了填补这一关键空白。它旨在成为一个标准化的、长期的评估平台,为下一代音频编辑系统的研发提供清晰的诊断路线图。
MMAE基准详解:一个系统性的评估体系
MMAE不仅仅是一个数据集,更是一个包含系统性分类法、高质量标注和创新性评估范式的完整评测套件。
全面的任务分类法
研究团队从三个正交维度对音频编辑任务进行了系统性的分类,确保覆盖真实世界中复杂多样的编辑场景:
模态:涵盖7种音频类型,包括纯声音、纯音乐、纯语音,以及它们的两两混合(如声音-音乐、声音-语音、音乐-语音)和三者混合(声音-音乐-语音)。混合模态任务更贴近实际应用,也更具挑战性。
复杂度:分为6个等级,从简单的单步操作,到涉及多段音频、多轮交互、多跳推理(需要中间推断)的复杂任务。这反映了模型从基础执行到高级认知的能力谱系。
操作与粒度:定义了8种编辑操作类型,并按粒度分为局部编辑(如添加、移除、替换、提取、局部属性修改)和全局编辑(如背景更换、前景更换、整体修改)。一个任务可能包含多种操作的组合。

图1:MMAE基准在模态、复杂度和操作三个维度上的数据分布,体现了其多样性和平衡性。
创新的基于量规的评估范式
这是MMAE的核心创新。面对开放式编辑任务,传统指标力不从心。MMAE借鉴了在教育测评和近期AI评估中的成功经验,引入了基于量规的评估范式。
具体而言,对于每个音频编辑样本(包含原始音频和自然语言指令),研究团队都设计了一套精细的、原子化的、相互独立的评估量规。每个量规都是一个多选题,聚焦于一个可验证的单一属性,例如“输出音频中第二声玻璃敲击的音高是否明显降低了?”或“输出音频中男性主持人的说话内容是否与原始音频一致?”

图2:一个多音频音乐编辑任务的示例。指令要求“将audio2歌词全部改为‘Hachimi’,并使用audio1的人声音色”。下方列出了部分对应的评估量规,用于判断指令跟随和内容一致性。
评估由两个核心维度构成:
指令跟随率:衡量模型是否准确执行了指令要求的修改。 一致性率:衡量模型是否完好保留了指令未要求修改的音频内容。
通过一个高性能的多模态大语言模型(如Qwen3-Omni)作为“评判员”,根据生成的编辑结果音频来选择量规的答案。最终,通过计算样本在所有量规上的平均得分,得到模型在两个维度上的性能指标。此外,精确匹配率作为一个更严格的指标,衡量模型能够完全无误(所有量规都答对)完成编辑的样本比例。
严谨的数据构建流程
为确保数据的多样性和高质量,MMAE的构建遵循了一个严谨的五阶段流程:从专家头脑风暴收集创意,到构建分类法与评估范式,再到以指令为中心的数据收集,接着通过人机协作进行量规标注,最后进行严格的多轮质量检查与修正。整个流程共产生了2000个高质量样本和17741条精细的量规。

图3:MMAE数据构建的全流程示意图,涵盖了从创意收集到最终质检的各个环节。
实验结果:当前模型的瓶颈与发现
研究团队在MMAE上评估了五个代表性的最新音频编辑模型:Step-Audio-EditX, Ming-UniAudio, MMEdit, Audio-Omni 和 SmartDJ(包含有无外部规划器的两种设置)。结果揭示了当前技术的诸多局限。
整体表现堪忧
如下表1所示,所有模型的整体表现均不理想。在完整数据集上,表现最好的Step-Audio-EditX模型,其指令跟随率和一致性率也仅分别为44.86%和58.88%。而精确匹配率这一关键指标,所有模型都低于5%,这意味着模型几乎无法一次性完美地完成任何一项编辑任务。
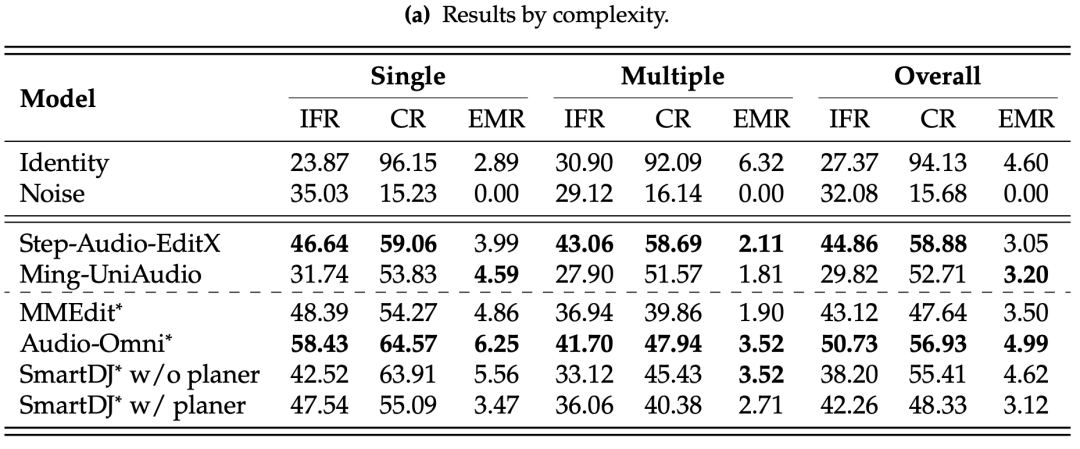

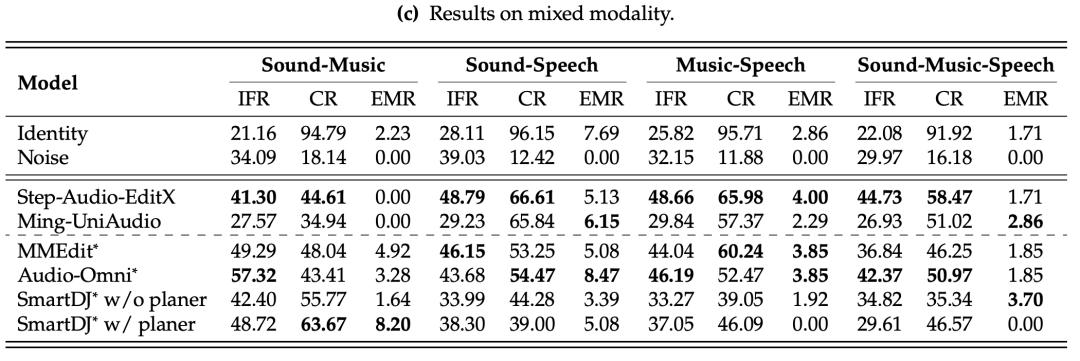
表1:各模型在MMAE上的主要评估结果。IFR是指令跟随率,CR是一致性率,EMR是精确匹配率。
更令人震惊的是,在声音-音乐-语音这种最复杂的混合模态任务中,所有模型的精确匹配率均为0% 。这无疑给追求通用音频编辑的AI研究敲响了警钟。
关键发现与洞察
复杂度与混合模态是性能“杀手”:所有模型从“单一”复杂度任务过渡到“多重”复杂度任务时,性能都出现显著下滑。同样,处理混合模态音频比处理单一模态音频要困难得多。这表明当前模型缺乏处理复杂推理和跨域同步所需的结构鲁棒性。
指令跟随与一致性存在根本性权衡:评估中设置的两个基线模型清晰地表明了这一点。“原样输出”基线有近乎完美的一致性率(94.13%),但指令跟随率很差(27.37%);而“输出噪声”基线则有相反的倾向。现有模型则在这两者之间艰难挣扎,无法取得良好平衡。这也证明了将两个指标分开报告的必要性,因为一个综合分数可能会掩盖模型通过“少编辑”来投机取巧的行为。
平均能力与完美执行存在脱钩:一个有趣的发现是,平均指标更高的模型,其精确匹配率未必更高。例如,Step-Audio-EditX的平均指令跟随率和一致性率都明显高于Ming-UniAudio,但其精确匹配率反而更低。这类似于生成模型中的“均值寻求”与“众数寻求”行为。一些模型倾向于在多数任务上做到部分正确(提高平均分),但总有小错误;而另一些模型则在大量任务上完全失败,但在少数任务上能做到完美。这提示我们,优化平均指标并不等同于提升模型可靠完成完整编辑的能力。
外部智能体规划帮助有限:在SmartDJ模型中引入外部规划器(Gemini 2.0 Flash)来分解复杂指令,并未带来一致的性能提升。规划器版本提高了指令跟随率,但严重损害了一致性率,整体精确匹配率也没有改善。错误分析表明,瓶颈既存在于规划器对复杂音频语境的理解上,也存在于基础模型执行原子操作的可靠性上。这指出,在过度依赖高层规划之前,优先提升基础模型本身的编辑保真度更为关键。
未来展望与结论
MMAE的发布,为音频编辑AI领域树立了一个急需的、高标准的评测基准。它系统性的分类法和基于量规的评估范式,为模型性能提供了精细、客观、可解释的度量工具。
当前的实验结果表明,尽管现有模型已具备基础的音频编辑能力,但它们距离实现可靠、精确的通用编辑还有很长的路要走。极低的精确匹配率,以及在复杂、混合任务上的惨淡表现,凸显了该领域面临的严峻挑战。
MMAE不仅是一个评测工具,更是一份研究路线图。它指明了未来需要重点突破的方向:提升原子编辑操作的保真度、开发真正支持全模态的通用模型、以及构建更鲁棒的、由智能体引导的组合式编辑系统。
随着音频内容创作的日益普及,能够理解人类意图并精准执行的AI编辑助手将成为强大的生产力工具。MMAE的出现,正如一场精心设计的“高考”,旨在甄别出真正的“优等生”,并引导整个领域向着更智能、更可靠的未来迈进。这场考试才刚刚开始,而现有的“考生”们,还需要加倍努力。
> 本文由 Intern-S2 等 AI 生成,机智流编辑部校对
-- 完 --
机智流推荐阅读:
1.
2.
3.
4.
cc | 大模型技术交流群 hf | HuggingFace 高赞论文分享群 lc|LangChain 技术交流群 code | AI Coding 交流群 具身 | 具身智能交流群 硬件 | AI 硬件交流群 推理 | AI 推理框架交流群 Agent | Agent 技术交流群










