JetSpec团队 投稿
量子位 | 公众号 QbitAI
近期,DeepSeek发布DSpark让大模型推理效率再次成为行业焦点。
几乎在同一时间,另一大模型基座代表阶跃星辰参与发表了一篇名为《JetSpec:Breaking the Scaling Ceiling of Speculative Decoding with Parallel Tree Drafting》的论文,也回答了一个相似问题:当模型能力继续提升,下一阶段AI竞争不只是谁更聪明,而是谁能把智能更快、更稳定地输出出来。

简单来说,DSpark更关注推理服务中的验证效率,JetSpec则从Draft生成本身入手,用因果并行树生成提高一次验证能接受的Token数。前者是在系统层面减少无效计算,后者是在算法层面提高有效Token生成率。
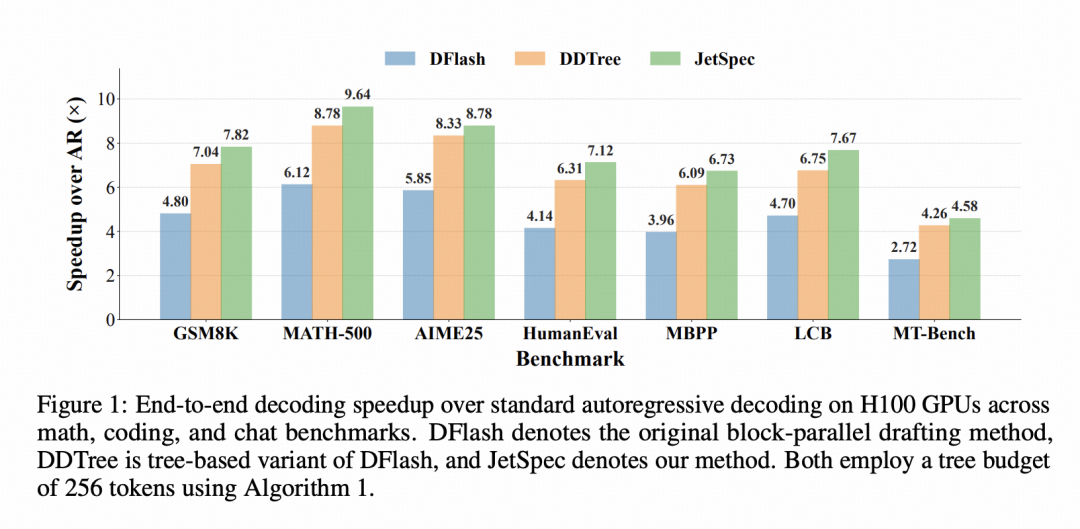
从结果来看,DSpark展示了推理服务在生产系统中仍有60%-85%(Flash模型)和57%-78%(Pro模型)的速度提升空间;JetSpec则从算法侧给出了一组更直接的加速结果:在Qwen3-8B上,JetSpec相比标准自回归解码最高实现9.64×端到端解码加速;在MATH-500上,一次验证平均可接受10.76个token。更重要的是,这种加速并不只出现在数学任务,在HumanEval、LiveCodeBench、MT-Bench等代码和对话任务上,JetSpec也分别实现了7.12×、7.67×和4.58×加速。
放在阶跃的技术路线里看,JetSpec不是一个孤立的推理加速论文,而是Flash模型叙事的一部分。从Step 3.5 Flash到Step 3.7 Flash,阶跃一直强调的并不是“大而全”的模型竞赛,而是面向Agent场景的高效智能:更快的输出速度、更优的调用成本、更好的工具调用与多模态任务执行能力。JetSpec则进一步从推理算法层面补上了这块拼图——当模型开始被Agent高频、长链路、持续调用时,真正决定体验和成本的,不只是模型能不能回答,而是它能不能以足够高的效率完成一次又一次推理。因此,DSpark和JetSpec的同时出现并不是巧合。它们共同说明,大模型行业正在进入一个新阶段:模型能力仍然重要,但推理效率正在成为决定Agent能否规模化落地的基础变量。
值得一提的是,这两篇论文均有AI行业技术大佬坐镇。DSpark作者栏中看到了梁文锋的名字,而在JetSpec作者栏中则看到了阶跃两位大佬:CEO及创始人姜大昕、CTO及联合创始人朱亦博,其中朱亦博博士是AI Infra领域的顶级专家,长期深耕大模型训练与推理系统、分布式计算和高性能AI基础设施。一作为Lanxiang Hu,目前就读于加州大学圣地亚哥分校(UCSD),师从Prof.Hao Zhang和Prof.Tajana Šimunić Rosing,在阶跃实习期间完成此项工作。其他作者分别来自浙江大学、UIUC以及南京大学。实际上,这也不是阶跃和UCSD第一次在大模型效率方面合作,此前他们还共同发表了PD分离(Prefill-Decode Disaggregation)这条技术路线的代表性开山论文之一DistServe,该研究将大模型的推理过程拆分为“预填充”和“解码”两个阶段,并让它们分别在独立的计算资源池中进行伸缩与调度。如今这种解耦推理架构已被NVIDIA TensorRT-LLM、SGLang、vLLM等主流大模型推理框架采用。
当因果性遇见并行草稿:推进投机解码的吞吐–延迟前沿
概览
投机解码通过让轻量级草稿模型提前生成候选token,再由目标模型一次性并行验证这些候选结果,从而加速自回归生成。
最近,来自DSpark和JetSpec几乎同期发布,并共同指向同一个核心瓶颈:当草稿生成已经足够便宜之后,如何保留足够的因果一致性,让并行生成的token能够通过目标模型验证,并真正转化为实际的系统收益?
这两项工作都收敛到这一方向,说明因果性正在成为下一代投机解码的关键一招。它们分别从吞吐量—延迟边界的两个互补侧面切入。DSpark面向高并发服务场景:在Qwen3-8B和AIME25上,DSpark在投机预算为7的设置下,通过带有因果递归状态的置信度调度验证,将平均接受长度从DFlash的4.07提升到5.01。JetSpec则面向低延迟、计算预算更充足的场景:通过将因果性直接融入并行草稿头,它能够把更大的草稿预算转化为更长的接受前缀。在相同设置下,JetSpec将平均接受长度从投机预算为16时的7.23提升到预算为128时的9.82,超过了预算为128下DFlash的7.34和DDTree的8.66,从而更好地支持低延迟生成。
为什么接受率是关键
在低草稿生成成本的场景下,保持较高的逐token接受率尤其重要。
传统草稿模型,例如EAGLE系列,通常通过自回归生成来保持草稿质量,但这也意味着草稿越长,就需要越多的串行草稿生成步骤。DFlash改变了这一成本结构:它使用轻量级的块并行草稿模型,在一次前向传播中预测多个未来位置,从而打开了低成本草稿生成的空间。
但是,草稿生成便宜本身还不够。一旦草稿成本下降,瓶颈就会转移到并行候选结果能否通过目标模型验证上。当未来位置对前序草稿token的条件依赖较弱时,它们单独看可能都很合理,但连成序列后却可能彼此不一致。
因此,即使草稿生成相对于目标模型验证已经极其便宜,如果接受率不够高,最大加速比仍然会被限制。根据投机解码的理论,我们有:

其中,c表示逐token平均草稿成本与验证成本之比,α表示逐token接受率,γ表示草稿长度。
基于这一公式,在低草稿成本但中等逐token接受率的情况下,例如当 最大理论加速比仍然低于5倍(Figure1)。
最大理论加速比仍然低于5倍(Figure1)。

△图1:在不同逐token草稿成本和接受率下,投机解码的期望加速比会随着草稿长度变化而变化。结果表明,即使在极低逐token草稿成本的场景下,逐token接受率从0.85提升到0.95也会带来显著差异。
在真实服务场景中,这个问题会变得更有意思。一旦草稿生成足够便宜,目标就不再只是简单地生成更多草稿token,而是要决定节省下来的计算预算应该如何使用。
在高并发、吞吐量导向的服务场景下,目标是在不增加每个请求验证成本的前提下,提高整体吞吐量。这正是DSpark所面向的场景:它保持并行草稿主干的低成本,同时加入轻量级的串行头和置信度估计,用来更好地判断哪些候选结果值得送去验证,从而控制每个请求的计算预算。因此,相比MTP这类纯自回归草稿方法,DSpark能够持续提升吞吐量;而在MTP中,更长的草稿通常需要更多串行草稿生成步骤(图2)。
同期工作Domino也体现了类似思路:通过因果修正提升并行草稿质量,从而提高后续验证的有效性。
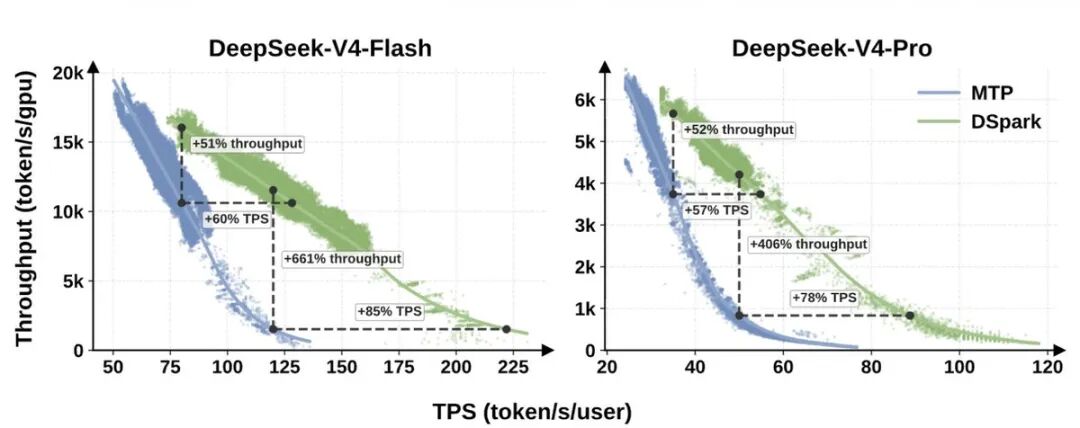
△图2(引自DSpark论文):在高并发场景下,DSpark的吞吐量与每用户生成速度(TPS)关系曲线。结果表明,在论文所测量的流量模式和推理引擎配置下,相比MTP-1基线,DSpark改善了实际观测到的吞吐量—延迟前沿。
在低并发、延迟导向的服务等级目标(SLO)下,系统拥有更充足的FLOPs预算,因此目标会转向最大化每次验证步骤中的接受率。在这种场景下,我们可以承受更高的草稿计算开销,用来提升接受率,并在更深的草稿位置上维持较高接受率。这正是JetSpec因果并行草稿方法变得尤其重要的地方:草稿预算被用于生成路径条件化的草稿树,使模型更有可能产生更长的可接受前缀。
△图3:在低并发场景下,JetSpec加速Qwen3-8B运行MATH-500时的每用户生成速度(TPS/user)。在多种代码和数学任务上,JetSpec将接受长度提升到约10–11个token,从而显著降低生成延迟,带来更好的交互体验。
因果性如何发挥作用
当草稿变得便宜之后,下一个问题是如何分配有限的计算强度:是在高并发下进一步压榨吞吐,还是在每个请求可用FLOPs更充足时追求更低延迟?这正是因果性成为关键之所在。
推进吞吐极限:用于预算感知校正的DSpark
DSpark面向高并发、预算受限的服务场景。它使用轻量级的Markov风格修正头和置信度头,也可以采用带有递归前缀状态的RNN-head变体。对于每个草稿位置i,并行草稿模型首先生成基础 ,以及对应的草稿隐藏状态hᵢ。随后,置信度头会估计与前缀相关的置信度分数cᵢ:
,以及对应的草稿隐藏状态hᵢ。随后,置信度头会估计与前缀相关的置信度分数cᵢ:

其中,Markov修正头 会根据前一个草稿token注入一个轻量级的因果修正,用来得到修正后的logits。随后,系统会根据预算
会根据前一个草稿token注入一个轻量级的因果修正,用来得到修正后的logits。随后,系统会根据预算 和阈值rho对验证长度进行调度:只保留满足置信度要求的最长前缀,并将其送入目标模型验证。
和阈值rho对验证长度进行调度:只保留满足置信度要求的最长前缀,并将其送入目标模型验证。

这使得DSpark非常适合预算感知的服务场景:草稿主干仍然保持并行,而轻量级修正路径则提升了局部一致性和前缀相关的一致性。
推进延迟极限:JetSpec将草稿预算转化为更高接受长度
在低并发场景下,现代AI加速器通常拥有更多空闲FLOPs,因此关键问题变成:如何把更高的计算预算转化为每次草稿—验证步骤中更多被接受的token?这正是JetSpec选择不同路径的地方。JetSpec使用因果并行草稿头生成路径条件化的草稿树,其中更深层的节点会依赖同一分支上更早生成的token。
这一效果可以从深度维度的接受率曲线中清楚看到(图4)。在代码生成和数学推理任务上,JetSpec都能比DFlash持续保持更高的接受率。

△图4:DFlash和JetSpec在AIME25上不同草稿深度位置的逐位置接受率。
在AIME25上,JetSpec在草稿深度1处的逐位置接受率几乎达到完美水平(q₁约为99%),并且在深度8处仍然保持约50%的接受率(q₈约为50%)。这里,qᵢ表示至少前i个草稿token被接受的生存概率。因此,经验接受长度可以写作:
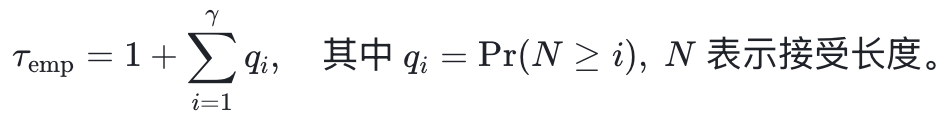
在原始投机解码分析所采用的恒定逐token接受率假设下,
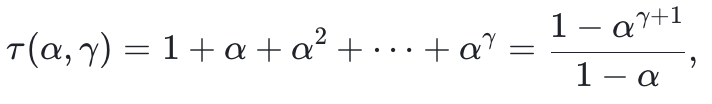
我们通过拟合理想理论接受长度与经验接受长度来定义alpha_eff:
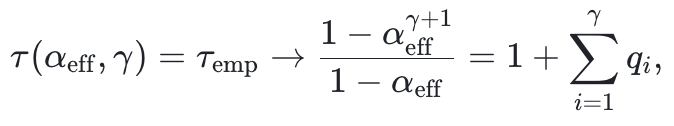
这对应于约93%的有效逐token接受率,显著高于DFlash。在这种低成本、高接受率的场景下,即使逐token接受率提升5%,也会对投机解码产生显著影响:它会大幅提高最大理论接受长度(图1),进而直接降低生成延迟。
下一步:同时支持吞吐量导向和延迟导向的并行草稿生成
一个可预见的下一步,是构建一个动态服务框架,同时推动吞吐量—延迟帕累托边界的两端:在低并发场景下提升每用户生成速度,在高并发场景下则在严格验证预算约束下提升整体吞吐量。
在这一方向上,当前阶段的JetSpec和DSpark具有天然互补性:JetSpec强化了并行草稿主干,使其能够在低延迟场景下更好地利用更大的草稿预算;而DSpark则通过轻量级串行置信度检查和预算控制,更好地支持高并发服务。
JetSpec项目地址:https://jetspec-project.github.io/jetspec-web/
论文地址:https://arxiv.org/abs/2606.18394
开源地址:https://github.com/hao-ai-lab/JetSpec
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
【学术投稿】请在工作日发送邮件至:ai@qbitai.com,标题注明【投稿】,并告诉我们:你是谁,从哪来,投稿内容附上项目/主页链接,以及联系方式。
🌟 点亮星标 🌟