
视频生成大模型的竞争,正在从谁生成得更好看,转向谁能实时互动。
过去一年多,主流视频大模型的迭代方向大体相似:提升分辨率、拉长生成时长、优化运动一致性、增强指令可控性。用户输入提示词,模型完成推理后输出一段长度相对固定的视频,这几乎已经成为行业默认流程。
但实时交互场景正在提出新的要求。
视频通话、实时陪伴、虚拟偶像、互动直播,都无法只依赖离线生成一段成片。用户会不断提问、打断、引导角色做出新的反应;角色也需要在对话过程中持续理解语音、调整动作、维持形象,并把新的反馈实时呈现在画面里。
换句话说,视频模型不再只需要生成得好,还要随时听得懂、马上有反应、长时间不掉线。
正是在这个节点上,生数科技把 Vidu S1 带到了实时交互这条新路线上。
在今天举行的 2026 全球数字经济大会上,生数科技创始人朱军正式对外发布全新实时交互模型 Vidu S1。该模型由朱军教授的 00 后博士生张金涛担任负责人,带领团队完成 Vidu S1 全链路研发。Vidu S1是生数科技通用世界模型整体布局在实时交互式生成方面的一个重要体现。
Vidu S1 面向的是一类全新的使用场景:让视频模型从离线成片,走向可对话、可响应、可持续在线的实时交互。它的核心能力包括语音实时控制视频生成内容、无限长实时生成、540P (960×540) + 25FPS (最高可支持 42FPS) 实时交互,以及自定义初始图像与音色。难得的是,这套实时交互能力在消费级显卡上就能跑起来。
这种革新改写了数字人的创建流程。
过去,数字人的制作更像一个小型项目:需要准备素材、完成建模或训练,再做口型、动作和形象适配。制作周期从几分钟到一天不等。
Vidu S1 采用更纯粹的生成式路线,省去了离线建模和角色训练环节。用户只需上传一张首帧图,模型就能快速理解角色的身份、外观和风格,并在交互过程中实时生成该角色的表情、口型、动作与姿态;再结合自定义音色,数字人也能保持形象与音色的统一。
从「上传素材等待训练」到「上传首帧直接交互」,个性化数字人的使用门槛大幅降低。
我们也提前体验了 Vidu S1 的实际效果。比如,我们上传了一张最近爆火的负鼠表情包,只需简单设置,一个会说天津话的负鼠角色就出现在了屏幕里。它不只能接话、顺着话题往下聊,还能听懂动作指令:你让它比赞、摸鼻子、眨眼睛,它都能在画面里实时做出对应动作。
这正是 Vidu S1 最值得关注的地方。它并不是对已有视频生成能力的常规升级,而是为实时交互式视频模型确立了新的技术基准。
AI 视频的下一阶段已经浮现:生成质量仍然重要,但已只是起点。能否实时交互,正在成为新的分水岭。
从离线生成到实时交互,Vidu S1 定义视频生成模型新基准
从离线播放到双向互动:交互范式的根本转变
过去视频生成模式可以概括为三步:用户输入提示,模型进行一系列推理计算,完成后一次性输出一段音视频内容。这套逻辑本质上是一次性内容交付,用户在生成过程中没有任何介入和修改的空间。
Vidu S1 改变的正是这一交互范式。
它支持通过语音甚至摄像头画面与角色进行实时对话,用户说一句话,模型立刻理解语义并同步生成对应的视觉反馈,这个过程不是先生成完整视频再播放,而是像视频通话一样边理解、边生成、边输出。用户可以在互动过程中随时改变指令,模型也会随之调整下一步的画面内容,不需要重新发起一次生成请求。
值得一提的是,Vidu S1 还具备一定程度的场景理解能力:当用户开启摄像头,模型能识别画面中的人物数量、动作状态等信息,并据此给出实时反馈,而不只是被动响应语音指令。这让交互不再局限于对话本身,也延伸到了对物理环境的感知。
语音指令实时跟随,不只是驱动嘴型,而是驱动行为
数字人技术发展到今天,多数产品仍停留在音频驱动口型阶段。这种方式的局限很明显,动作数量有限、组合痕迹明显,用户很容易感觉到这是被安排好的表演,而不是真实的即时反应。
Vidu S1 采用实时视频生成技术架构,让模型不仅能听清语音内容,更能听懂对话中的语义和情绪,并实时生成与之匹配的表情、手势乃至完整的肢体动作,而不是从固定动作库里调用现成片段。

语音指令 实时跟随。从「语音驱动口型」迈向「语音驱动行为」,让角色听得懂、动得准、反馈更自然

实时生成 无限时长。全球领先的无限时长,实时互动视频大模型
支撑这套能力的,是自回归扩散模型 (AR + Diffusion) 路线:模型并非一次性产出完整片段,而是基于已经生成的历史画面,结合用户当前的语音、指令等上下文信息,实时预测并生成下一帧内容。这种逐帧生成的方式,天然具备可被实时打断和改写的特性,用户随时发出的新指令,都能被模型实时理解并体现在后续画面中,不必等待一整段视频生成完毕再重新开始。
无限时长实时生成
除了交互式实时生成,Vidu S1 还首次实现了无限时长的实时视频生成。即使连续生成数小时,画面仍能保持稳定,不会快速漂移或崩坏。
实现长时间连续互动,仅仅 “持续生成” 还不够。模型还需要在长时间运行中同时保持角色身份稳定、动作自然连贯,并能够持续接收用户指令、实时做出响应。Vidu S1 既能在长时间生成中保持角色形象稳定、动作自然连贯,也能持续接收用户语音指令并实时作出响应,率先实现无限时长的生成式视频互动。
540P+25FPS 背后:实时交互拼的是模型与系统协同
在实时交互场景下,分辨率和帧率是直接决定用户体验是否流畅的关键门槛。视频通话、直播互动这类场景对模型提出的要求是持续输出、快速响应,并且在长时间运行中保持帧率稳定,任何一次卡顿或延迟都会被用户直接感知。
Vidu S1 给出的答案是 540P (960×540) 分辨率、25FPS 帧率 (最高支持 42FPS) 的实时生成能力,在同类实时交互方案中处于行业前列。

540P + 25 FPS 实时交互。支持 540P + 25 FPS 的高分辨率实时视频互动生成 (最高支持 42 FPS)
要实现这样的指标,背后离不开模型架构和系统工程两个层面的协同优化:
在模型侧,Vidu S1 基于生数科技的 TurboDiffusion [1] 推理加速框架,通过少步生成、低比特注意力 SageAttention [2]、稀疏注意力 SLA [3] 和 SpargeAttention [4] 等推理优化技术,大幅降低单帧生成所需的计算成本,在消费级显卡上就可以实现 540P 分辨率、25FPS(最高支持 42 FPS)实时生成。
在系统侧,Vidu S1 基于生数科技的 TurboServe [5] 推理部署引擎,实现高效的推理请求调度。系统持续记录用户输入、角色状态和历史画面,并根据交互状态动态调度计算资源。
通过模型推理与流式服务的协同优化,Vidu S1 实现了从 “把视频生成得更快”,到 “让视频持续在线、稳定输出、实时响应” 的关键跨越。

540P + 25FPS (最高支持 42FPS) 让实时视频生成模型具备了进入视频通话、直播、实时陪伴、互动游戏乃至 XR 场景的基础能力门槛。这些场景对延迟稳定性和长时间在线能力的要求,是传统离线生成模型完全无法满足的。
自定义角色,支持任意图片与音色进行数字人创建
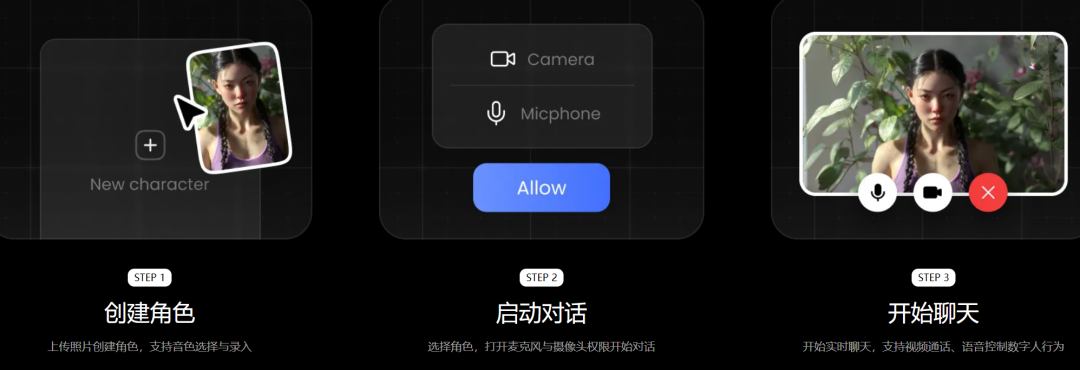
用户在体验页面中可以上传图片创建自己的角色。无论是真人形象、动漫人物、萌宠,还是游戏角色和其他虚拟形象,都可以作为初始角色使用;声音层面,用户也可以选择系统音色,或录制自己的声音进行定制。
这意味着,数字人的创建门槛被进一步降低。
普通用户可以用宠物、插画或自创人物生成互动角色;企业未来则可以通过 API,将品牌 IP、虚拟客服、数字主播、游戏 NPC 或教育陪练接入自己的业务。
Vidu S1 的想象空间,不再局限于数字人产品,而是进一步延伸到 AI Character、互动内容和实时视频基础设施。
一手测试:女孩、学长、狐妖、蒙娜丽莎,都被 Vidu S1「唤醒」了
更重要的是,Vidu S1 是完全公开试玩的(https://www.vidu.cn/vidu-stream),可自定义初始图像实时互动,同时还开放了 API 平台。实际效果如何,我们亲自上手体验了一番。Vidu S1 预设了多个角色,用户进入页面后可以直接选择角色开启通话。

内测体验地址:
国内地址:https://www.vidu.cn/vidu-stream
API 地址:https://platform.vidu.cn/live/landing
客户端体验方式:在手机应用商店搜索「Vidu AI Pro」下载最新版本,进入 APP 内点击「Vidu S1」即可体验
我们首先从预置角色开始测试。用户只要选定角色,就可以通过麦克风直接发出语音指令。角色会在画面中实时回应,并根据对话内容实时生成表情、口型和动作反馈。
通过视频聊天,我们可以直接用语音指挥数字人做出不同动作。比如,当我们要求它「举起网球拍」这个动作时时,画面中的数字人会根据指令自然调整身体姿态,抬手完成挥拍的动作。
又比如,当我们发出「双手放在胸前比心」的指令后,画面中的数字人响应很快,手部位置、身体姿态和表情衔接都比较自然。语音在这里已经延伸为角色行为生成的控制信号。
在接下来这个测试中,数字人在回应时语气自然,节奏也与真实交流相符。它会顺着用户的问题继续展开,也会根据当前语境调整表情和状态。尤其是在日常的闲聊场景里,这种自然接话的能力会让角色更有在场感。
我们还临时提出了几个更细的动作要求,比如推眼镜、撩头发,都较好地完成了。
在下面这个测试中,该角色展现出了极高的交互智能与情绪感知力。不仅对答如流、转承自然,更能主动引导话题、有效避免冷场,对随机提出的开放性问题亦能应对自如。在指令执行层面,角色对「比心」、「施法」等动态指令的完成度极高;在情感表达上,其「生气」等微表情的管理也十分精准到位。
除了预置角色,Vidu S1 也支持用户上传图片创建自己的角色。创建过程中,用户可以直接选择系统提供的预置音色,也可以录制自己的声音,让角色在视觉形象和声音上都具备更强的个性化特征。
更让我们意外的是创建速度。上传图片并完成基础设置后,新角色几乎可以立即进入对话状态。

最后,我们上传了一张《蒙娜丽莎》的图片进行测试。
进入通话后,画面中的蒙娜丽莎不再只是保持原本的经典微笑,而是可以根据语音输入开口说话,并在对话过程中生成口型、表情和轻微动作反馈,无论是抬手动作还是生气时的表情和语气,都非常自然。
自定义角色可以覆盖真人、动漫、萌宠等常见形象。对于内容创作者来说,这类能力打开了更大的想象空间:一张历史人物画像、一幅插画、一个品牌 IP,甚至一张风格化角色图,都有机会被快速变成可对话、可表演、可持续互动的数字角色。
结语:视频生成模型的下一站,是实时交互模型
过去,视频大模型主要服务于内容创作,用户关心的是视频清晰度、够不够好看。接下来,视频大模型会进入实时交互场景,用户开始关心模型能否实时听懂需求?能不能马上做出反应?能否长时间保持同一个角色?是否可以接入直播、陪伴、游戏和 XR?
这些问题,单靠传统离线视频生成无法解决。
实时交互模型让视频从播放对象变成交流对象,数字人也因此从会说话的形象,走向可以被语音驱动、感知环境、持续生成行为的在线角色。
这正是 Vidu S1 想要定义的行业位置。
从率先提出 U-ViT 架构,到率先发布实时交互模型,生数科技始终走在视频大模型技术演进的前沿。其持续领先的技术布局,不仅展现了深厚的研发实力,也再次验证了其对 AI 视频发展方向的前瞻判断。
未来,行业竞争将不再局限于视频生成质量,而是围绕实时响应、角色一致性与长期在线能力展开。随着流式视频模型和 AI Character 的持续发展,数字人也将从内容生产工具,进化为下一代人机交互入口。
[1] TurboDiffusion: Accelerating Video Diffusion Models by 100-200 Times.
[2] SageAttention: Accurate 8-Bit Attention for Plug-and-play Inference Acceleration.
[3] SLA: Beyond Sparsity in Diffusion Transformers via Fine-Tunable Sparse-Linear Attention.
[4] SpargeAttention: Accurate and Training-free Sparse Attention Accelerating Any Model Inference.
[5] TurboServe: Serving Streaming Video Generation Efficiently and Economically.
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com










