点击下方卡片,关注“大模型之心Tech”公众号
今天大模型之心Tech为大家分享清华&上海AI Lab等团队近期的大模型相关工作——AnyCap项目:一个用于可控全模态描述生成的统一框架、数据集与基准。如果您有相关工作需要分享,请在文末联系我们!
>>点击进入→大模型技术交流群
背景与挑战
多模态大型语言模型(MLLMs)正快速向全模态智能演进,能够处理图像、视频、音频等多种模态,而文本描述作为连接这些模态的通用接口,在检索、问答、内容生成等众多任务中发挥着关键作用。近年来,描述生成的可控性受到越来越多的关注,即模型需具备生成精确遵循用户指令的描述的能力,例如强调特定方面或采用指定的风格表达。这种可控性对于满足用户个性化需求和提升下游任务性能至关重要。
然而,实现精确且可靠的全模态可控描述生成仍面临重大挑战:
首先,开源模型的可控能力有限,现有描述模型多依赖刚性控制信号(如软提示、边界框)来调整描述的精细度,虽能实现一定控制,但灵活性受限,生成结果多样性不足;自然语言提示虽更灵活,却因训练数据有限且范围狭窄,往往仅在特定方面(如详细描述)表现较好,且重新训练模型以支持更广泛的控制成本高昂,还可能削弱其整体语言能力。
其次,缺乏可控全模态描述数据集,可控描述的人工标注成本高、耗时长,而利用模型生成大规模数据又因缺乏低成本且质量有保障的生成管道而面临困难。
最后,缺乏合适的评估基准和指标,经典的机器翻译 metrics(如 BLEU、CIDEr)依赖 n-gram 重叠,无法反映内容准确性和对控制信号的遵循程度;基于 LLM 的评分器则存在高方差、风格偏差和诊断能力差等问题。
核心创新
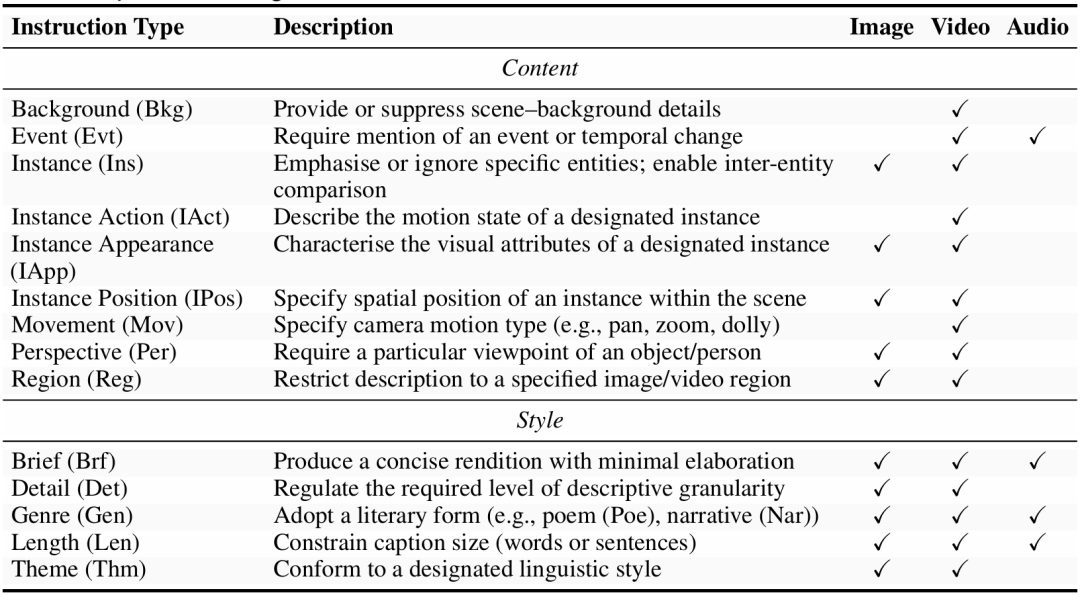
提出AnyCapModel(ACM):一种轻量级即插即用框架,无需训练基础模型,通过整合用户指令、模态特征和基础模型生成的初始描述,提升全模态描述的可控性,适用于多种基础模型。 构建AnyCapDataset(ACD):涵盖图像、视频、音频3种模态,28种用户指令类型,30万高质量数据条目,采用三元组结构(用户指令、高质量合规描述、次优描述),降低标注难度,支持学习与用户偏好的精确对齐。 设计AnyCapEval评估基准:通过分离内容准确性和风格保真度提供更可靠的评估指标,包括关键密度(KPD)和详细评分标准,从内容和风格维度评估可控描述生成。

核心方法细节
AnyCapModel(ACM) 工作流程:对于图像、视频、音频等模态输入,先由冻结的基础模型生成初始描述,再由ACM框架对该描述进行优化,生成符合用户指令的改进描述。 架构:通过模态特定编码器(如InternViT用于图像和视频,EAT用于音频)提取模态特征嵌入,经模态特定线性变换(MLPs)投影到共享语义空间;同时将用户指令和初始描述分词并嵌入为文本嵌入,最后将模态和文本嵌入拼接后输入自回归语言模型生成改进描述。 训练策略:采用残差校正训练策略,专注于优化现有描述而非从头生成。训练中包含约40%初始描述已符合要求或事实正确的数据样本,引导模型识别无需或需少量校正的情况,增强对齐能力。 训练设置:使用AdamW优化器训练3个epoch,学习率为1×10⁻⁶,采用余弦学习率调度(预热比例0.03),权重衰减0.01,全局批大小256,使用bfloat16混合精度。训练时冻结外部模态骨干,更新ACM的内部组件(包括语言模型)。

AnyCapDataset(ACD) 定义:采用三元组结构(用户指令、高质量合规描述、次优描述),用户指令指定描述属性,高质量描述严格遵循指令,次优描述在事实准确性、详细程度或指令合规性等方面存在 minor 缺陷。 指令类型:通过调研文献和分析下游需求,确定28种指令类型,分为内容控制(如强调特定实体、描述背景等)和风格控制(如简洁表达、采用特定文体等)。 构建流程:为每个多模态样本生成用户指令和合规描述,设计包含任务描述、多模态输入、原始参考标题(如有)和高质量示例的提示引导模型生成;生成次优描述时,基于(指令、合规描述)对移除指导或添加控制退化指令。生成前对提示严格验证,生成后随机抽取5%样本人工审核,确保95%以上符合人类偏好。 统计信息:包含约30万三元组数据,源自约75万原始样本,涵盖图像(125k)、视频(100k)、音频(75k)三种模态,最优描述平均长度62词,次优描述平均长度57词。
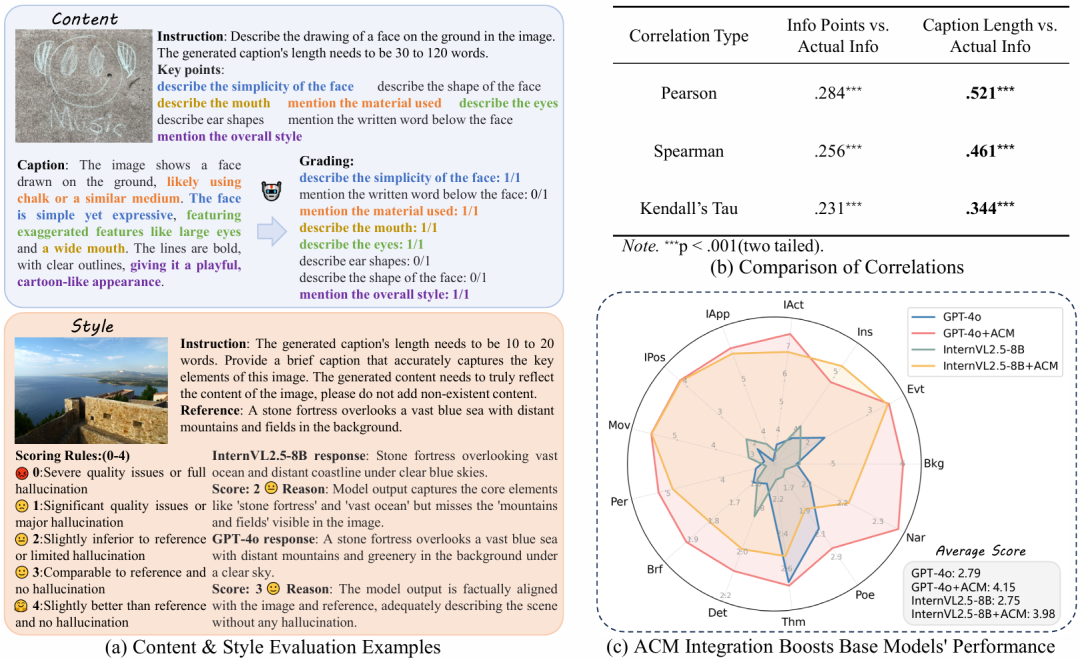
AnyCapEval 内容评估:给定参考描述和用户指令,标注涵盖指令所需信息的关键要点集,通过基于GPT-4o的自动匹配器识别候选描述中存在的关键要点,计算关键密度(KPD),即每100词中匹配的关键要点数量,量化有效信息率。 风格评估:由GPT-4o根据用户指令将候选描述与参考描述对比,按0-4分进行离散评分,评分标准涵盖与指令的偏离程度、幻觉严重程度、与参考的相似性等,通过结构化提示降低评估方差和主观偏差。
实验验证
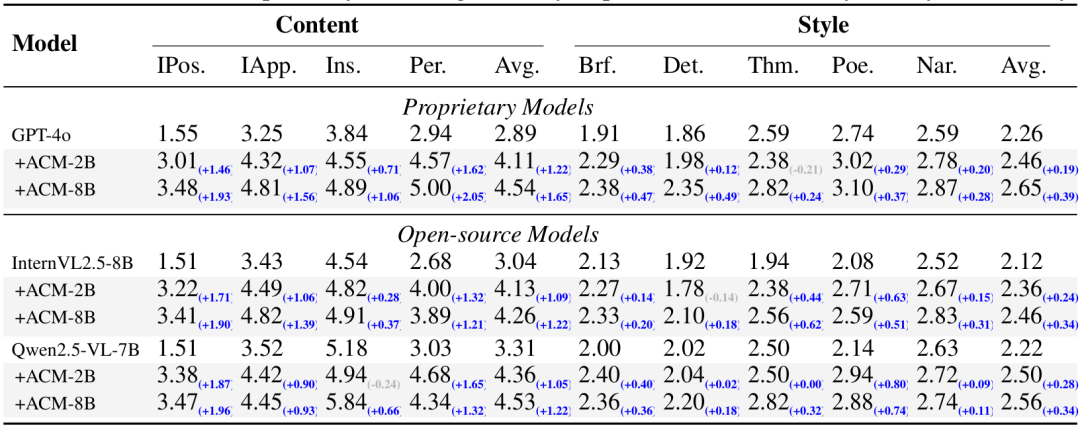
实验设置:在AnyCapDataset上训练ACM的2B和8B变体,使用32个NVIDIA A100(80GB)GPU,2B模型训练6小时,8B模型训练21小时。评估时结合多种基础模型(如GPT-4o等专有模型,InternVL2.5-8B、Qwen2.5-VL-7B等开源模型)在AnyCapEval及MIA-Bench、VidCapBench等公开基准上进行。 对比实验:ACM在AnyCapEval上显著提升多种基础模型的内容和风格分数,如ACM-8B使GPT-4o的内容分数提升45%、风格分数提升12%;在MIA-Bench和VidCapBench等公开基准上也有显著增益,部分开源模型结合ACM后性能接近或超过专有模型。




消融实验:对比ACM与SFT、DPO、SC方法,ACM表现更优且无需模型特定训练;探索训练数据比例影响,发现适度加入次优描述可提升模型对指令偏差的敏感性,40%左右的完全合规数据比例较优;还分析了不同数据类型比例对性能的影响,确定了较优的比例配置。



总结
本文提出的AnyCap项目通过AnyCapModel、AnyCapDataset和AnyCapEval,为可控全模态描述生成提供了统一解决方案。ACM提升了多种模态和模型的可控性,减少幻觉;ACD填补了数据缺口;AnyCapEval提供了可靠评估方法。但在新兴模态应用上受限于高质量数据集,且存在恶意滥用风险,未来需拓展数据集和关注伦理影响。
参考
标题:AnyCap Project: A Unified Framework, Dataset, and Benchmark for Controllable Omni-modal Captioning
链接:https://arxiv.org/abs/2507.12841
仓库:https://github.com/qishisuren123/AnyCap
大模型之心Tech知识星球交流社区
我们创建了一个全新的学习社区 —— “大模型之心Tech”知识星球,希望能够帮你把复杂的东西拆开,揉碎,整合,帮你快速打通从0到1的技术路径。
星球内容包含:每日大模型相关论文/技术报告更新、分类汇总(开源repo、大模型预训练、后训练、知识蒸馏、量化、推理模型、MoE、强化学习、RAG、提示工程等多个版块)、科研/办公助手、AI创作工具/产品测评、升学&求职&岗位推荐,等等。
星球成员平均每天花费不到0.3元,加入后3天内不满意可随时退款,欢迎扫码加入一起学习一起卷!











