编辑:严浠
近日,UC伯克利联合Google DeepMind、多伦多大学、剑桥大学提出的基于MuJoCo XLA(MJX)构建的机器人强化学习框架MuJoCo Playground荣获了RSS 2025 最佳 Demo奖,现已完全开源。
MuJoCo Playground仅通过“pip install playground”指令,就能在单块GPU上高效训练,耗时仅需几分钟。该框架旨在简化机器人仿真、训练,支持多种机器人本体,包括四足机器人、人形机器人、灵巧手及机械臂,能够实现在不同输入模式(包括状态输入和像素输入)下的零样本sim-to-real迁移。

论文标题:《MuJoCo Playground》
论文链接:https://arxiv.org/abs/2502.08844
项目主页:https://playground.mujoco.org/
1
方法
1.1 环境
MuJoCo Playground包含三大类环境:DeepMind (DM) Control Suite(控制套件)、Locomotion(运动) 和 Manipulation(操作)。
DM Control Suite(控制套件)
复现了DM Control Suite主流的强化学习环境,作为入门级任务,可以帮助用户快速熟悉MuJoCo Playground。

Locomotion (运动)
支持多种四足机器人和双足机器人。四足机器人包括Unitree Go1、波士顿动力Spot、谷歌Barkour;人形机器人包括伯克利人形机器人、Unitree H1/G1、Booster T1、Robotis OP3。每个机器人提供了手柄指令追踪功能,通过强化学习训练机器人跟踪前进/横向速度及转向指令,还为Unitree Go1开发了跌倒自恢复和倒立行走的专项训练。目前,Unitree Go1、伯克利人形机器人、Unitree G1、Booster T1均已实现sim-to-real迁移。
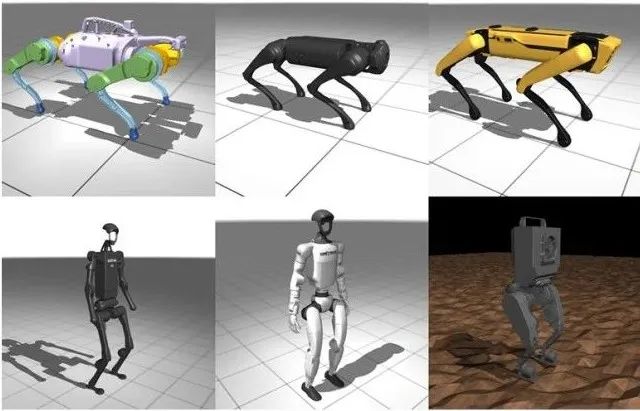
Manipulation(操作)
涵盖了抓取与非抓取任务,如下图展示了Leap Hand灵巧手方块重定向,在Franka机械臂上实现了抓取方块,Aloha机器人的双臂插孔等。目前,在Leap Hand灵巧手和Franka机械臂上均实现了sim-to-real迁移。
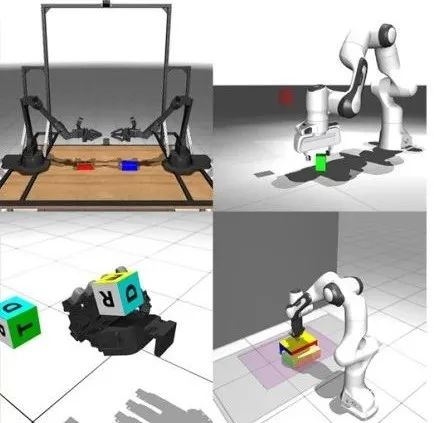
具体来说,采用MANO手部参数作为人类与机器人操作的共享动作空间 。在训练阶段通过优化MANO参数,使其生成的指尖位置与机器人灵巧手的实际指尖位置保持一致。在部署阶段由一个小型MLP将预测的指尖位置映射到机器人灵巧手的具体关节指令。
1.2 Madrona批量渲染器
MuJoCo Playground通过深度整合MJX与Madrona渲染引擎,实现了端到端的视觉输入环境训练。Madrona是一个基于GPU的ECS实体-组件-系统架构,包含了高吞吐量渲染的GPU实现。
2
实验
实验展示了MuJoCo Playground中各类环境的强化学习训练结果与sim-to-real迁移效果。sim-to-real实验涵盖了locomotion与manipulation环境。
2.1 Locomotion(运动)
1)四足机器人
训练过程:研究人员针对传感器噪声、动力学属性和任务不确定性进行了域随机化。首先在平坦地面上、限定指令范围内训练(耗时约5分钟,使用2块RTX 4090 GPU);随后在更复杂地形和更宽指令范围内进行微调。
研究人员在Unitree Go1四足机器人上进行了策略部署,设置了遥操控制、前腿倒立、后腿倒立、跌倒恢复这四项任务。实验结果表明,上述四项任务均成功实现了sim-to-real的迁移。这些策略能够应对崎岖地形,并能抵御一定的外部扰动,且无需额外微调。

2)人形机器人
训练过程: 研究人员采用了与四足机器人相似的域随机化和微调策略,实验选用了三种不同的人形机器人(伯克利人形机器人、Unitree G1和Booster T1)进行了sim-to-real实验。在平坦地面上进行训练,使用2块RTX 4090 GPU,伯克利人形机器人耗时15分钟内,Unitree G1和Booster T1耗时少于30分钟。
实验结果表明,在伯克利人形机器人上成果部署了遥操作运动控制策略,能够在坚硬地板、柔软光滑的地面等多种地面实现不同速度行走。在Unitree G1和Booster T1上部署零样本策略,同样能在标准室内地板上稳定的行走和转向。

2.2 Manipulation(操作)
研究人员对一系列操作任务进行了sim-to-real迁移,包括了灵巧手的掌中操作(dexterous in-hand manipulation)、非抓握式操作以及基于视觉的抓取。
1)方块重定向任务
研究人员使用了LEAP Hand,要求灵巧手连续翻转7cm方块,新目标姿态与前次至少相差90°,误差小于 0.1rad。

实验结果如下表所示,在10次实验中连续成功5次,最大误差小于10°。而失败时主要是因为灵巧手手指形变,方块卡在指缝。

2)瑜伽砖重定向任务
研究人员在Franka Emika Panda机械臂,配备Robotiq夹爪进行实验,要求瑜伽砖移动到目标位置并朝向正确, 位置误差小于3 厘米,方向误差小于10°。

实验结果如下表所示,成功率达到了100%,无需额外微调即可在真实机器人上完成重定向瑜伽砖的任务。

3
总结
本论文中,研究人员提出了一个基于开源MuJoCo模拟器与Madrona批量渲染器构建的环境库MuJoCo Playground,用于实现多种机器人强化学习任务。研究人员展示了如何在不同的GPU拓扑结构上,结合JAX与PyTorch等强化学习库进行大规模策略训练,并在从状态输入到像素输入的多种机器人运动与灵巧操作任务上,演示了sim-to-real 的实际部署效果。
END
推荐阅读
从第一视角人类视频中学习操作技能!UCSD联合NVIDIA提出VLA模型EgoVLA,无需使用大量真机数据训练
首次将触觉作为原生模态引入VLA!清华叉院高阳团队联合提出Tactile-VLA,任务成功率近100%
实现灵巧手抓取80%成功率!银河通用王鹤团队提出视觉语言抓取模型DexVLG | ICCV 2025
通用双臂机器人操作最新SOTA!清华开源分层高斯世界模型ManiGaussian++ | IROS 2025
点击下方名片 即刻关注我们










