
近期,某智能人机交互团队论文《AVE Speech: A Comprehensive Multimodal Dataset for Speech Recognition Integrating Audio, Visual, and Electromyographic Signals》被该期刊接收发表。该论文针对老龄化人群交流障碍,提出了一个整合音频、视觉和肌电信号的AVE Speech多模态语音数据集,以提升跨受试者和高噪声环境下的语音识别性能。

01
引言
全球人口老龄化加剧,听障与语障人群激增,对鲁棒的人机语音交互技术提出迫切需求。现有技术路径大致分为两类:一是依赖麦克风音频的自动语音识别,虽已广泛落地于Siri、小爱同学等消费级应用,却在高噪或失声场景下性能急剧退化;二是基于非声学信号的无声语音识别,涵盖唇读视觉模态与表面肌电模态,但前者易受光照及口型相似词干扰,后者则因电极位移和个体生理差异而稳定性不足。单模态的固有限差促使研究转向多模态融合,以期通过互补信息提升整体鲁棒性。然而,当前公开数据集在模态完整性与人群代表性方面仍显不足:LibriSpeech、THCHS30仅提供音频,LRS2-BBC仅含视听,EMG-UKA规模受限且说话人多样性有限,均难以支撑面向老年人及交流障碍者的真实场景研究。
为解决上述问题,本文提出了AVE Speech数据集,其整合了与语音过程直接相关的音频、视觉和肌电信号,主要贡献如下:
首个公开同步采集音频、唇部图像、面部肌电信号的数据集。
首个涵盖100个日常生活句子的普通话句子级语料库,每个句子包含3到5个不同的词语。
首个在受控现场环境中构建的多模态语音数据集,有100名普通话受试者参与,而非从公开视频中编译和标注而来。
02
数据集
AVE Speech数据集围绕“音频—视觉—肌电”三模态协同建模需求,从语料设计、采集协议到预处理流程进行全链路系统化构建。
1.语料设计
该数据集的语料库设计以马斯洛需求层次理论的五个维度(生理、安全、归属感与爱、尊重、自我实现)为基础,同时融入医疗场景相关语句,构建了包含100句普通话的语料库,旨在满足言语障碍群体及需日常、康复、护理辅助的老年人群体的需求。每句均为独立的普通话表达,并附带语音转录及声调标注(对应普通话的一声、二声、三声、四声及轻声)。
数据集的参与者为100名成年普通话母语者,其中女性29名、男性71名,年龄分布在18-40岁区间,平均年龄为26.68岁。本研究已通过大学伦理委员会审批,所有参与者均签署知情同意书。
2.数据采集
该数据采集在安静且光照正常的室内环境中进行,如图1所示。参与者通过交互界面获取相关指令,穿戴好采集设备后启动录制流程。每轮采集需朗读101个句子(含1个空白句),要求在2秒内完成,且需尽量避免摇头、咳嗽等无关动作;每位参与者完成10轮采集,每朗读20句可休息5秒,每轮结束后可休息至准备就绪再继续,全程耗时约1小时/人。为降低固定句子顺序及参与者习惯带来的偏差,每轮句子顺序均随机打乱。
采集设备及参数设置如下:
音频信号:采用头戴式麦克风录制,采样率为44100Hz。
视觉信号:通过RGB相机采集唇部区域视频,帧率为30帧/秒,相机位置通过3D打印固定装置调节,采集图像中心设有640×360的固定边界框。
肌电信号:利用NSW308M双极肌电系统采集6块面部及颈部肌肉的六通道数据,采样率为1000Hz;电极贴附于颏肌、笑肌等特定肌肉部位,参考电极置于锁骨处,录制过程中电极阻抗维持在10kΩ以下。
上述三种模态信号针对同一句子同步采集,分别对应音频波形、唇部图像序列及六通道肌电波形。

图1 采集过程
3.数据格式
数据集采用分层结构进行组织,按模态分为音频、视频、肌电三大主目录,各主目录下设有对应100名参与者的子目录;每个参与者子目录包含10个会话子目录,每个会话子目录下有100个单句单模态数据文件及1个空白句文件。原始录制阶段,每位参与者贡献1010条数据,经剔除错误数据后,各模态最终包含99500条数据,累计时长约55.3小时。
表1 语音识别数据集对比

如表1所示,现有数据集或仅覆盖单一模态(如音频、视觉),或仅整合两种模态(如音频与视觉、音频与肌电),且在说话人多样性、特定群体(如老年人、交流障碍者)需求覆盖及数据采集可控性等方面存在局限;而AVE Speech数据集作为首个整合音频、视觉、肌电三种模态的大规模普通话句子级数据集,在受控现场环境下采集100名说话人的数据,填补了现有研究中多模态整合不全面、说话人多样性不足等空白,为多模态语音识别研究提供了更全面的资源支撑。
03
模型框架
团队给出了即插即用的基准网络,如图2所示;主要包含单模态特征提取模块与多模态融合模块两部分。单模态特征提取阶段,音频信号经二维卷积层编码后接入ResNet-18提取特征,唇部图像序列通过三维卷积层编码后同样由ResNet-18处理,肌电信号则采用特定配置的二维卷积层(kernel大小3×3,通道[64,64,128,128,256])进行空间特征提取;三种模态的特征均经过Bi-GRU(隐藏层512)或Transformer编码器进行时间信息处理。多模态融合阶段,各单模态提取的特征在拼接层整合,随后通过Bi-GRU网络进行跨模态时间特征融合,最终经线性层与SoftMax函数实现句子分类,整体架构实现了音频、视觉、肌电模态信息的有效整合与协同建模。

图2 模型框架
04
实验结果
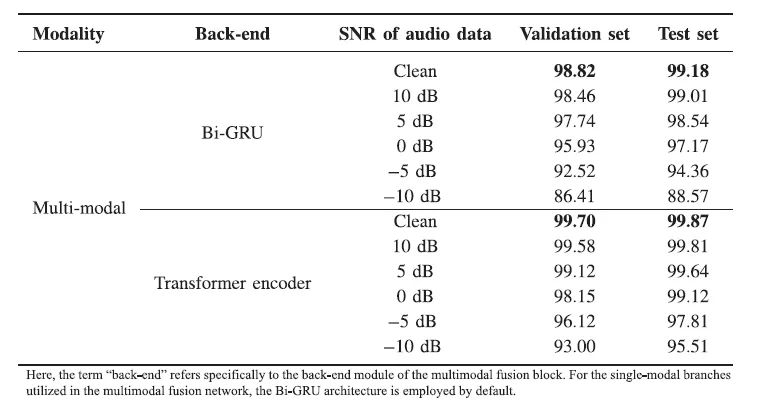
实验采用完全跨说话人划分(70人训练/10人验证/20人测试)。表2给出单模态识别结果;在 Transformer Encoder 结构下,音频、视觉、肌电模态在干净测试集上的准确率分别约为 99.36%、98.55%、63.54%。值得注意的是,随着信噪比降低,音频模态性能迅速退化 :0 dB 时准确率降至约 72.16%,-5 dB 时进一步降至约 35.33%,-10 dB 时仅为约 8.13%;而视觉和 EMG 模态则基本不受噪声影响。表3展示了多模态融合下的表现;在0 dB以上噪声条件下,三模态融合模型的准确率在干净测试集上始终保持99%以上,即使在极端噪声环境中仍维持较高水平(-5 dB 时 97.81%、-10 dB 时 95.51%)。这一结果充分验证了多模态互补信息对提升跨说话人场景及高噪声场景鲁棒性的显著作用。
表2 不同噪声条件下单模态语音识别模型的识别准确率

表3 不同噪声水平下多模态融合网络的识别准确率
05
总结
AVE Speech是首个同步采集中文“音频-视觉-肌电”三模态的句子级数据集。实验显示,它在跨说话人及高噪声场景下仍具显著优势,为后续多模态融合研究、语音识别及言语感知机制探索提供了开放基准。
论文链接:
https://doi.org/10.1109/THMS.2025.3585165
数据集链接:
https://huggingface.co/datasets/MML-Group/AVE-Speech
代码链接:
https://github.com/MML-Group/code4AVE-Speech
来源:CIE智能人机交互专委会
仅用于学术分享,若侵权请留言,即时删侵!
欢迎加入脑机接口AI星球,获取更多脑机接口+AI等领域的知识和资源。

合作咨询请添加微信:RoseBCI【备注:姓名+行业/专业】。
欢迎来稿
1.欢迎来稿。投稿咨询,请联系微信:RoseBCI
点击投稿:脑机接口社区学术新闻投稿指南
2.加入社区成为兼职创作者,请联系微信:RoseBCI


一键三连「分享」、「点赞」和「在看」
不错过每一条脑机前沿进展










