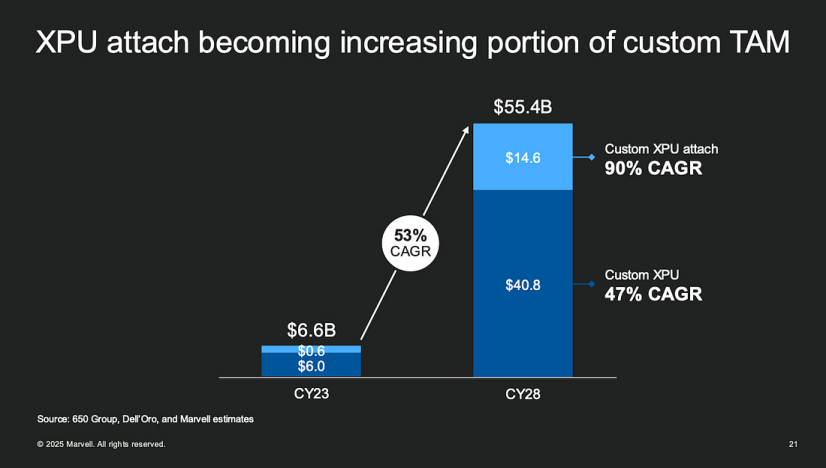
本篇选自Semi Version的长文深度解析Marvell如何以全栈定制战略重塑AI芯片基础设施。面对云巨头3270亿美金AI投资浪潮,传统GPU架构遭遇成本与能效瓶颈。Marvell凭借XPU+Attach双轨架构(18款定制芯片落地)、6.4Tbps硅光引擎及2nm级封装集成,构建从SRAM缓存优化到光互连的完整技术闭环。文章揭示其颠覆性创新:定制SRAM面积减半功耗降66%,448G SerDes突破带宽极限,更以XPU Attach组件90%增速卡位模块化AI生态——这不仅关乎单点技术突破,更是算力基础设施的范式革命。欢迎感兴趣的读者转发与关注!
在快速扩张的 AI 数据中心背景下,定制 XPU 开发的趋势正变得越来越显著。随着 GPU 成本飙升且供应持续受限,越来越多的云服务提供商和超大规模平台转向内部开发 AI 加速器,以获取灵活性和成本效益。虽然 NVIDIA 的 GPU 在推理和训练性能上持续领先,但其高昂的单体成本和平台锁定效应促使业界探索替代架构——从而引发了内部 ASIC 开发的热潮。定制 XPU 的概念不仅涵盖定制的 CPU、GPU、DPU 和 NPU,还包括异构计算框架内的系统级配套组件。这些组件包括纵向扩展互联结构、内存池单元、协处理器、安全模块和光互连。焦点从仅仅最大化单个芯片性能转向在系统架构层面进行协同优化。在此架构转型中,Marvell 凭借三大核心竞争力发挥着关键的使能作用:Marvell 在 5 纳米以下节点设计定制 ASIC 方面拥有经过验证的成功记录,并正积极与台积电(TSMC)等领先代工厂在 N3 和 N2 工艺上展开合作。这使得 Marvell 能够为 AI 推理、网络和安全工作负载交付高性能、低功耗的定制芯片。利用基于小芯片(chiplet)的设计和 2.5D/3D 先进封装,Marvell 能够将计算裸片与高速 SerDes、HBM 堆栈和光模块集成在单个封装内。这显著降低了延迟和功耗,同时提升了系统带宽密度。Marvell 凭借其 112G 和 224G SerDes 技术,以及对 PCIe Gen6、CXL 和以太网的全栈支持,在高速 I/O 领域处于领先地位。它还深度投入光互连技术,支持共封装光学(CPO)和线性驱动可插拔光学(LPO),为数据中心带宽扩展提供面向未来的保障。本质上,定制 XPU 战略不仅仅是一种降本手段——它更是朝着基础设施协同设计的根本性转变,通过整体的硅-系统-封装集成来实现性能、功耗和灵活性。Marvell 在逻辑、封装和 I/O 领域的垂直技术栈能力,使其成为传统云超大规模企业和新兴 AI 原生平台不可或缺的合作伙伴。在这个新范式下,AI 硬件的价值超越了独立的芯片指标,转向模块化、可定制和可扩展的系统设计。Marvell 清晰地将加速计算市场划分为两大主要领域:定制 XPU——指核心的定制加速器本身——和 XPU 配套(XPU Attach),包括网络接口、纵向扩展互联结构、内存控制器和管理模块等外围协处理芯片。通过接口解码全局:Marvell 如何定义其在 AI 芯片时代的影响力随着 AI 数据中心转向异构计算和基于平台的设计,依赖单一芯片的性能已不足以满足大规模 AI 模型的需求。Marvell 通过其“定制 XPU + XPU 配套”的双轨战略,正在重塑加速计算的竞争格局。其在 2025 年披露的18 个加速定制计算接口(Accelerated Custom Compute Sockets),不仅反映了其技术部署的深度和广度,更是评估其在 AI 芯片业务成熟度与战略渗透力的具体指标。Marvell 公布的 18 个接口并非简单地代表 18 个 ASIC。相反,它们代表了与客户的真实部署,每一个都是一个具有商业价值和深度系统集成的接口级设计项目。每个接口对应一个与超大规模企业或新兴 AI 参与者共同定义的芯片项目,可能包括:DPU、纵向扩展互联结构控制器和安全 I/O 组件这些并非一次性设计,而是多年、多代的合作项目,反映了 Marvell 在帮助塑造下一代 AI 系统蓝图方面的战略作用。2.双市场渗透:顶级超大规模企业与新兴 AI 参与者根据 Marvell 的数据,这 18 个接口分布在两个关键领域:美国前四大超大规模企业(亚马逊、微软、谷歌、Meta)- 3 个定制 XPU 接口: 代表 Marvell 直接参与设计核心计算单元,如训练或推理 ASIC。
- 9 个定制 XPU 配套接口: 支持关键子系统,如 SerDes、CXL 接口、内存控制器、数据包处理和光连接。
新兴超大规模企业(例如 OpenAI、特斯拉、xAI、Humane)- 2 个定制 XPU 接口: 反映了新 AI 原生参与者采用自定义芯片和定制加速平台的趋势。
- 4 个定制配套接口: 支持模块化 I/O、内存解聚(disaggregation)和云边协同部署。
这种多元化的客户群突显了 Marvell 服务老牌和下一代超大规模平台的独特能力。这些接口项目并非短期合作——它们代表了多代设计伙伴关系。Marvell 已不仅仅是 IP 供应商;它已成为一个全栈使能者,参与芯片设计的每一层——从架构协同定义、先进封装到 SerDes 及热/功耗协同优化。更重要的是,这些接口的成功反映了 AI 硬件日益增长的模块化和平台化特性。通过整合 ASIC 设计、封装技术和高速互连,Marvell 提供为云和新兴 AI 架构量身定制的端到端、协同优化的硅平台。在此背景下,Marvell 正扮演着 AI 芯片时代基础设施构建者和生态系统整合者的角色——提供可扩展、可复用和可定制的解决方案。这些接口合作项目提供了一个比传统产品数量更全面的衡量指标。在当今的 AI 格局中,拥有更多接口不仅仅意味着市场份额——它定义了谁在塑造 AI 基础设施的未来。技术领导力:SerDes、裸片间互连与共封装光学的全面部署Marvell 强调了其在 SerDes 技术上持续的代际领先地位,其 3 纳米 224Gbps SerDes——在 2025 年 OFC 上展示——实现了超过 50Tbps/mm 的带宽密度和低于 0.1pJ/bit 的能效。这使其成为超长距离、高精度 AI 数据中心互连的理想选择。在裸片间互连方面,Marvell 的裸片间互连(Die-to-Die, D2D)技术正朝着 50Tbps/mm 性能和亚皮焦耳/比特(sub-pJ/bit)能效迈进,支持跨多裸片封装平台(如多堆栈 HBM 系统和 CoWoS)的紧密集成。在光学领域,Marvell 已建立了一个内部的共封装光学(CPO)平台,该平台基于其专有的硅光引擎,每个引擎可提供 6.4Tbps,通过 4 引擎配置可扩展至 25.6Tbps。该平台与台积电的先进封装工艺和 JEDEC 标准保持一致,巩固了其作为下一代基础设施使能者的角色。Marvell 的 AI 芯片与解决方案全服务能力Marvell 在当今 AI 定制硅市场取胜的能力源于其独特的“全服务定制(Full-Service Custom)”模式——不仅是作为 IP 提供商或独立的 ASIC 设计公司,更是作为一个全面的集成合作伙伴,使超大规模企业和新兴 AI 参与者能够将系统架构愿景转化为生产就绪的硅芯片。Marvell 与客户合作共同开发完整的系统架构,而非仅仅交付 IP 模块。基于 AI 工作负载特征(无论是训练还是推理),Marvell 致力于内存访问模式、互连拓扑结构以及功耗性能权衡,以共同设计多核计算、网络传输和数据流控制蓝图。➡ 关键优势: 真正的系统级思维,与云提供商合作定义下一代平台。Marvell 提供全套先进的设计 IP——包括高速 I/O、SerDes、PCIe、CXL 和一致性互联结构(Coherent Fabric)——可随时嵌入定制 ASIC。这确保了芯片开发的短上市周期和高可靠性。➡ 关键优势: 自有的 SerDes/CXL IP 组合,能够快速支持高带宽 AI 芯片互连,而无需过度依赖第三方授权。从 RTL 和物理设计(PD)到 DFT、时序收敛(Timing Closure)和流片(Tape-out),Marvell 提供端到端的硅实现服务。该公司已在 5 纳米和 3 纳米等先进节点上实现量产验证,并正在积极准备 2 纳米设计。➡ 关键优势: Marvell 可以帮助客户在先进节点(如台积电 N3B/N2)快速流片,同时支持后期 PPA(性能、功耗、面积)优化。随着小芯片架构和光电集成成为主流,Marvell 支持先进封装技术,包括 2.5D 中介层(interposer)、扇出(fan-out)、异构集成和光引擎封装。➡ 关键优势: SerDes/CPO 组件与封装的协同设计,提供低功耗、高带宽和可靠的互连解决方案。Marvell 提供交钥匙制造和物流解决方案——涵盖晶圆生产、封装、测试和最终交付。特别是对于云规模的 ASIC 项目,Marvell 简化了供应链并加速了量产爬坡。➡ 关键优势: 经过验证的量产和交付执行能力,消除了超大规模企业管理复杂后端运营的需要。https://tspasemiconductor.substack.com/p/from-custom-sram-to-optical-serdes