机器之心编辑部
终于,OpenAI 的新发布还是来了。
虽然不是我们期待已久的 GPT-5,但也是「something big-but-small today.」

也就是开源新语言模型。
要知道,这是近几年来(自 GPT-2 以来),OpenAI 重新开源模型。
据在 OpenAI 任职研究科学家的清华校友翁家翌透露,从 2022 年 OpenAI 内部就讨论模型开源,并曾数次接近「开源」目的,但直到今天才实现。

这次还一下开源了两个,都是推理模型。

GitHub 地址:https://github.com/openai/gpt-oss
hugging face 地址:https://huggingface.co/openai/gpt-oss-20b
hugging face 地址:https://huggingface.co/openai/gpt-oss-120b
博客地址:https://openai.com/index/introducing-gpt-oss/
Sam Altman 声称,gpt-oss 性能与 o4-mini 水平相当,并且可以在高端笔记本电脑上运行(WTF!!)(还有一个较小的可以在手机上运行)。

两款开源模型与 o3、o4-mini 的跑分结果比较如下:

总结一波,这两个开源模型的亮点包括:
宽松的 Apache 2.0 许可证:自由构建,不受版权限制或专利风险 - 非常适合实验、定制和商业部署。
可调整的推理力度:根据具体用例和延迟需求轻松调整推理力度(低、中、高)。
完整的思维链(CoT):完全可访问模型的推理过程,从而更轻松地进行调试并增强对输出的信任。不计划向终端用户展示。
可微调:通过参数微调,完全可根据特定用例定制模型。
Agentic 功能:使用模型的功能进行函数调用、网页浏览、Python 代码执行和结构化输出。
原生 MXFP4 量化:模型使用原生 MXFP4 精度针对 MoE 层进行训练,使得 gpt-oss-120b 可在单个 H100 GPU 上运行,gpt-oss-20b 模型可在 16GB 内存内运行。
OpenAI 还做了一个 playground ,让开发者可以在网页端简单尝试这两个开源模型,感兴趣的读者可以去体验尝试。

试用地址:https://www.gpt-oss.com/
在过去的几个小时,海外 AI 社区已经炸开了,纷纷开始下载尝试新模型,以至于 Hugging Face 的 CTO 只能在线请求大家不要全都去下载,服务器要崩了!

接下来,就让我看看下这两个最新开源模型的技术细节。
开源模型新高度
作为两个 SOTA 级别的开源语言模型,gpt-oss-120b 和 gpt-oss-20b 可以提供强大的实际应用性能,并具有低成本优势。
两款模型在推理任务上超越了同等规模的开源模型,展示了强大的工具使用能力,并且经过优化,能够高效部署在消费级硬件上。训练过程中结合了强化学习以及受 OpenAI 内部最先进模型启发的技术,包括 o3 和其他前沿模型。
其中,gpt-oss-120b 模型在核心推理基准测试上与 o4-mini 几乎持平,同时能够在单个 80GB GPU 上高效运行。gpt-oss-20b 模型在常见基准测试中表现与 o3-mini 相似,且仅需 16GB 内存即可运行,适用于边缘设备,非常适合本地推理、设备端使用或在没有高昂基础设施的情况下快速迭代。
两款模型在工具使用、few-shot 函数调用、CoT 推理以及 HealthBench 测试中表现非常出色,甚至超越了 o1 和 GPT-4o 等专有模型。
两款模型还具有非常强的系统兼容性,适用于需要卓越指令跟随、工具使用(如网页搜索或 Python 代码执行)和推理能力的智能体工作流中,并且能够根据任务的复杂性来调整推理力度,从而适应不需要复杂推理和 / 或针对非常低延迟最终输出的任务。两款模型完全可定制,提供完整的 CoT,并支持结构化输出。
当然,安全性是 OpenAI 发布所有模型的基础,尤其对开源模型至关重要。因此,除了全面的安全训练和评估测试外,OpenAI 还基于自身的准备框架(Preparedness Framework)测试了 gpt-oss-120b 的对抗性微调版本,引入了额外的评估层。从结果来看,gpt-oss 模型在内部安全基准测试中的表现与 OpenAI 的前沿模型相当,并提供与其近期专有模型相同的安全标准。
OpenAI 已经与 AI Sweden、Orange 和 Snowflake 等早期合作伙伴合作,了解两款开源模型在现实应用中的情况,包括将它们托管在本地以确保数据安全,以及在专业数据集上进行微调。
预训练与模型架构
gpt-oss 模型采用了 OpenAI 最先进的预训练和后训练技术,尤其关注推理、效率和在各种部署环境中的现实可用性。
两款模型均采用 Transformer 架构,并利用专家混合(MoE)来减少处理输入所需的活跃参数数量。其中,gpt-oss-120b 每个 token 激活 5.1B 参数,而 gpt-oss-20b 则激活 3.6B 参数。两款模型的总参数分别为 117B 和 21B。
此外,两款模型采用交替密集和局部带状稀疏注意力模式,类似于 GPT-3。为了提高推理和内存效率,模型还使用了分组多查询注意力,组大小为 8。同时利用旋转位置编码(RoPE)进行位置编码,并原生支持最长 128k 的上下文长度。

在训练集上,OpenAI 在一个主要是英文的文本数据集上训练了两款模型,重点关注 STEM、编程和常识类内容,并使用一个比 o4-mini 和 GPT‑4o 所使用更为广泛的分词器(tokenizer)对数据进行分词 ——o200k_harmony,同样也将其开源。
后训练
OpenAI 声称开源模型采用了与 o4-mini 相似的后训练流程,包含监督微调和高计算强化学习阶段。此外,OpenAI 还训练模型在输出答案前先进行思维链推理和工具调用。通过采用与 OpenAI 专有推理模型相同的技术,这些模型在后训练后展现出卓越的能力。
与 API 中的 OpenAI o 系列推理模型类似,这两款开源模型支持「低、中、高」三档推理强度调节,开发者只需在系统消息中添加一行指令即可轻松设置,实现延迟与性能的平衡。
性能评估
OpenAI 在标准学术基准上对比测试了 GPT-OSS-120B/20B 与 o3、o3-mini 及 o4-mini 等 OpenAI 推理模型,涵盖编程、竞赛数学、医疗和智能体工具使用等维度:
一系列测试结果表明,GPT-OSS-120B 在编程竞赛(Codeforces)、综合问题解答(MMLU 和 HLE)及工具调用(TauBench)方面超越 o3-mini,达到甚至超过 o4-mini 水平。
在医疗查询(HealthBench)和竞赛数学(AIME 2024&2025)领域表现更优于 O4-mini。尽管体积小巧,GPT-OSS-20B 在这些测试中仍与 o3-mini 持平甚至超越,尤其在竞赛数学和医疗领域表现更为突出。
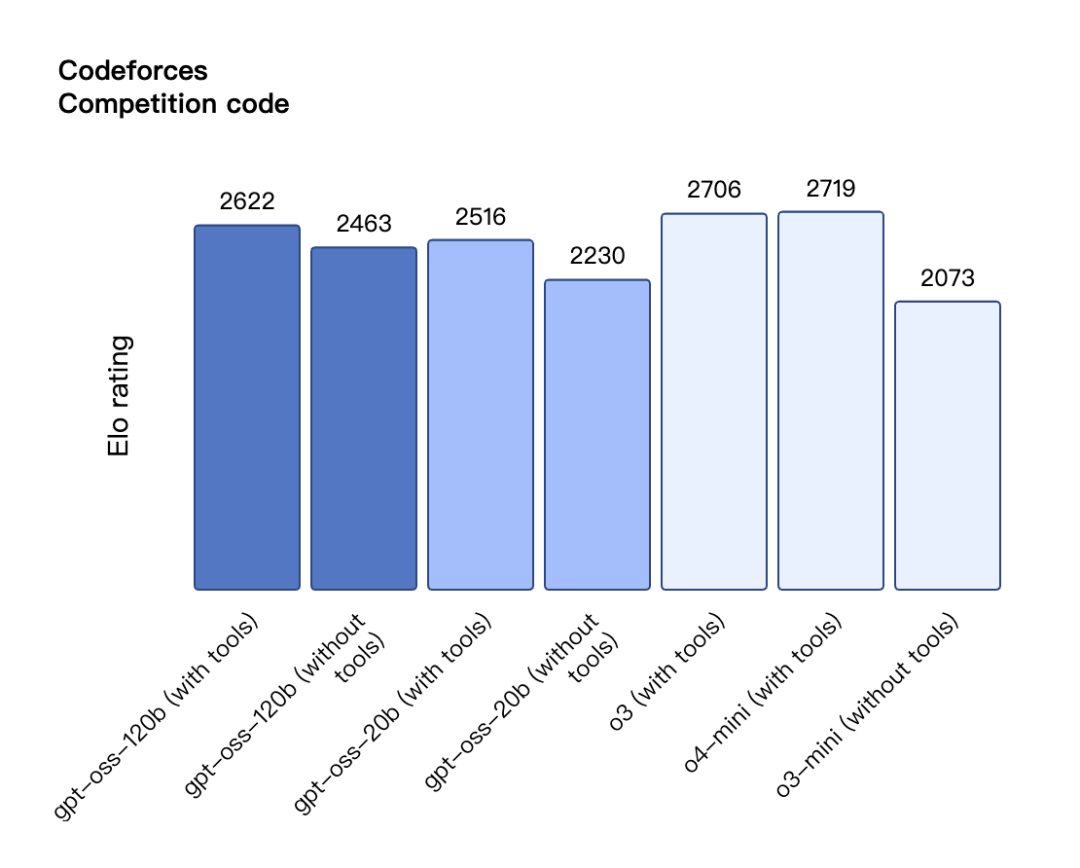
CodeforcesCompetition 编程基准

人类最后考试 —— 跨学科的专家级问题

HealthBench 基准测试

AIME 2024 和 AIME 2025 基准(使用工具)

GPQA Diamond(不使用工具)和 MMLU 基准
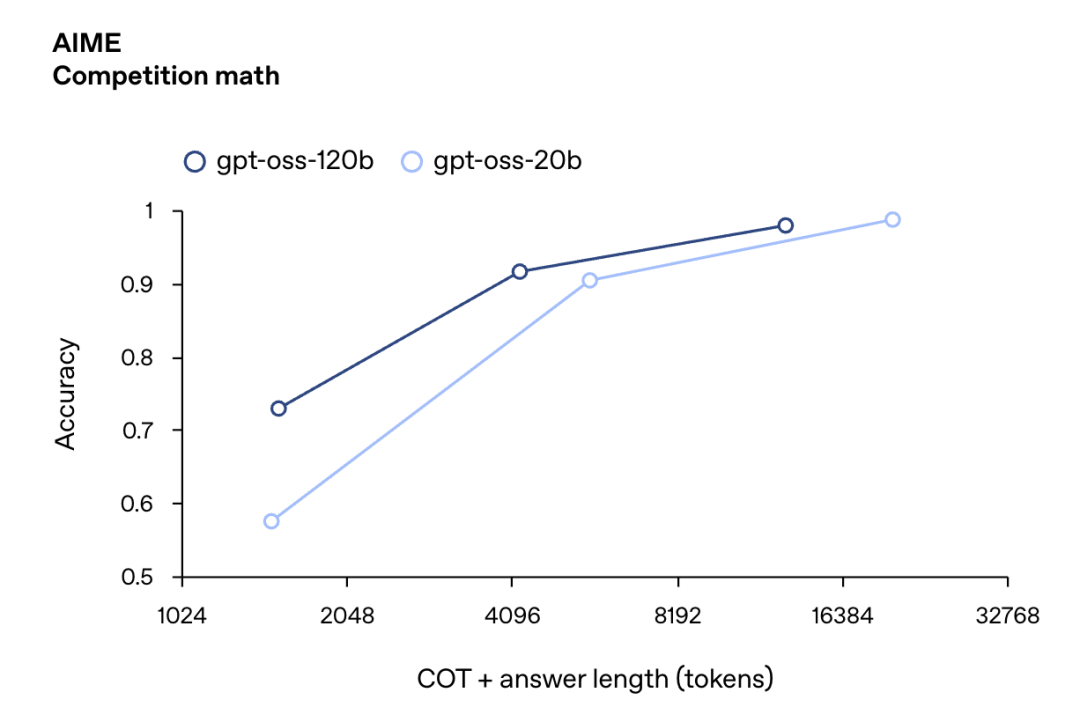
AIME 数学竞赛

GPQA Diamond(使用工具)博士级别科学问题
完整评估结果如下表所示:

思维链
OpenAI 近期的研究表明,只要模型未经过直接监督对齐其思维链,监控推理模型的思维链过程有助于检测异常行为。这一观点也得到业内其他研究者的认同。
因此在 GPT-OSS 系列模型的训练中未对思维链施加任何直接监督。
OpenAI 认为,这对于监测模型异常行为、欺骗性输出及滥用风险至关重要。通过发布具备无监督思维链能力的开源模型,希望为开发者和研究人员提供研究及实现自有思维链监控系统的机会。
更多的模型细节和评估结果请参考模型卡(model card):

模型卡地址:https://cdn.openai.com/pdf/419b6906-9da6-406c-a19d-1bb078ac7637/oai_gpt-oss_model_card.pdf
最后,在 GPT-5 迟迟未发布的情况下,你觉得 OpenAI 能否凭这两个开源模型挽尊呢?与国内开源模型比谁更香?欢迎已经用上的读者们讨论。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com