点击下方卡片,关注“大模型之心Tech”公众号
>>点击进入→大模型技术交流群
写在前面
在多模态人工智能领域,Salesforce Research的BLIP系列一直是开源社区的标杆。
从首次将视觉-语言预训练推向实用化的BLIP,到支持更灵活图文交互的BLIP-2,再到探索大模型统一架构的BLIP-3(XGen-MM),每一代产品都推动着多模态技术向"理解世界并生成内容"的终极目标迈进。
如今,这个传奇系列再添新作——BLIP3-o正式登场,不仅实现了图像理解与生成的无缝统一,更以全开源的姿态为学术界和工业界提供了全新的研究范式。

多模态模型的"统一难题":理解与生成如何兼得?
近年来,多模态大模型的发展呈现出两条清晰的技术路线:一条以图像理解为核心,专注于视觉问答、图像 captioning 等任务,代表模型包括CLIP、FLAVA等;另一条以图像生成为目标,通过扩散、自回归等技术实现文本到图像的转化,DALL·E、Stable Diffusion是其中的佼佼者。
但人工智能的终极形态,必然是能像人类一样同时具备"看懂"和"画出"能力的系统。OpenAI的GPT-4o虽展现出这种潜力,却因闭源特性难以让研究者深入探索其技术细节。如何构建一个既能精准理解图像内容,又能高质量生成符合文本描述的图像的统一模型,成为学术界的关键课题。

BLIP3-o的出现正是为了解决这一核心问题。研究团队在论文中明确指出:"现有研究对图像理解的模型设计已较为成熟,但能同时支持图像生成的统一框架仍缺乏系统性探索。"通过对图像表示形式、训练目标和训练策略的全面研究,BLIP3-o最终实现了两大能力的有机融合。


三大技术突破:从表示到训练的全链条创新
BLIP3-o的成功并非偶然,而是建立在对多模态建模关键问题的深刻洞察之上。研究团队通过三组对比实验,系统性地验证了最优技术路径,最终形成了BLIP3-o的核心架构。
突破一:CLIP特征完胜VAE,语义级表示成关键
在图像生成任务中,如何将图像转化为模型可处理的表示形式,一直是技术选型的难点。传统方法主要依赖VAE(变分自编码器)将图像编码为像素级潜在特征,但这种方式存在两大局限:一是高分辨率图像会导致特征序列过长,增加计算负担;二是像素级特征缺乏高层语义信息,不利于与文本描述对齐。
BLIP3-o另辟蹊径,选择CLIP图像编码器作为特征提取器。这种选择基于一个重要发现:CLIP通过大规模图文对比训练获得的语义特征,比VAE的像素特征更紧凑、信息更丰富。实验数据显示,无论图像分辨率如何,CLIP都能将其编码为固定长度的64维向量,而VAE对高分辨率图像的编码长度往往是其数倍。
更重要的是,CLIP特征天然与文本处于同一语义空间。这意味着在统一模型中,图像理解(如"这张图里有什么")和图像生成(如"画一只戴帽子的猫")可以共享同一个特征空间,避免了传统模型中不同任务需要单独适配的麻烦。
突破二:流匹配损失超越MSE,生成多样性大幅提升
确定了图像表示形式后,如何让模型学习从文本生成这些特征,成为下一个挑战。传统方法常用MSE(均方误差)损失,通过最小化预测特征与真实特征的距离来训练模型,但这种方式存在严重缺陷——它只能让模型学到特征的平均分布,导致生成结果缺乏多样性。
BLIP3-o引入了流匹配(Flow Matching)技术,这是一种源自扩散模型的训练方法。其核心思想是让模型学习从随机噪声到目标特征的"流动"过程,而非简单拟合平均值。实验表明,采用流匹配损失后,模型在相同文本提示下能生成更多样化的图像,GenEval(一种评估文本-图像对齐度的指标)得分从0.51提升至0.84,远超MSE损失的表现。
这种技术选择让BLIP3-o在保持生成质量的同时,解决了传统模型"千人一面"的问题。
突破三:顺序训练策略,平衡理解与生成能力
统一模型的训练往往面临"顾此失彼"的困境——强化图像生成能力时,图像理解性能可能下降,反之亦然。针对这一问题,BLIP3-o提出了两阶段顺序训练策略:

第一阶段专注于图像理解任务,使用CLIP特征训练模型的自回归 backbone,使其具备解析图像内容、回答视觉问题的能力;第二阶段冻结已训练好的 backbone,仅训练扩散 transformer 等生成模块,确保在提升生成能力的同时不损害理解性能。
对比实验显示,这种策略显著优于联合训练方法。在MMMU(多模态多学科理解 benchmark)中,BLIP3-o 8B模型得分达50.6,远超联合训练的MetaMorph(41.8)和Janus Pro(41.0);在图像生成任务中,其GenEval得分0.84也创下开源模型新高。
"顺序训练给予了每个任务专属的优化空间,"研究团队解释道,"这就像先教会模型'看懂'世界,再教它'画出'世界,符合人类认知的自然过程。"
BLIP3-o架构解析:自回归与扩散的完美协同

BLIP3-o的整体架构体现了"大道至简"的设计哲学,通过自回归模型与扩散 transformer 的协同,实现了理解与生成的无缝衔接。
模型的核心由三部分组成:作为基础的自回归大模型(采用Qwen2.5-VL系列)、负责图像生成的扩散 transformer,以及连接两者的CLIP特征空间。在图像理解模式下,CLIP编码器将图像转化为语义特征,自回归模型基于这些特征完成问答、 captioning 等任务;在图像生成模式下,自回归模型先根据文本提示生成中间视觉特征,再由扩散 transformer 逐步优化为CLIP特征,最后通过扩散解码器生成图像像素。
这种设计有两大精妙之处:一是CLIP特征空间的共享,让理解和生成任务无需特征转换即可交互;二是扩散 transformer 的引入,解决了自回归模型生成连续特征时的效率问题。论文中提到,8B参数的BLIP3-o仅需1.4B可训练参数就能实现生成能力的飞跃,远低于同类模型的参数量需求。
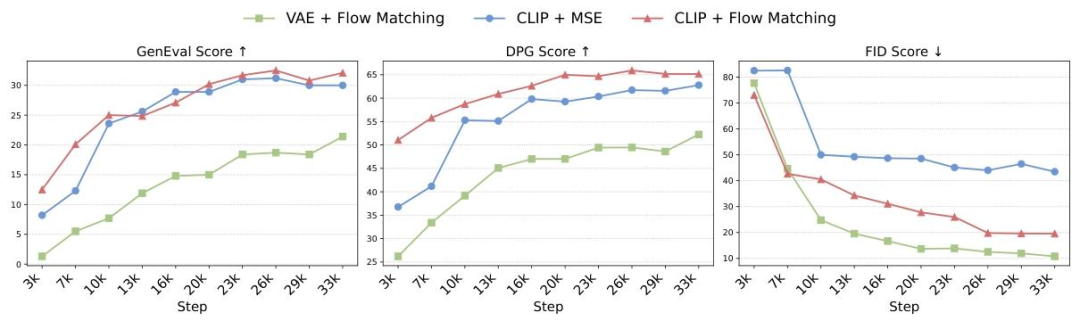
为验证架构的有效性,研究团队进行了多组设计对比实验(CLIP+MSE、CLIP+流匹配、VAE+流匹配等),结果显示CLIP+流匹配的组合在生成质量(FID)、 prompt 对齐(GenEval)和训练效率三个维度均表现最优,这也成为BLIP3-o的最终技术选型。
60k指令微调数据集:小数据撬动大提升
除了模型架构的创新,BLIP3-o的成功还得益于一个高质量的指令微调数据集——BLIP3o-60k。这个数据集通过GPT-4o生成,包含60k个精心设计的"文本-图像"对,覆盖场景、物体、人类姿态等多个维度。
研究团队发现,预训练模型在处理复杂人类手势(如"拉弓射箭")、特定物体(如"各种蔬菜水果")、地标建筑(如"金门大桥")和简单文本生成(如"路面上的'Salesforce'字样")时存在明显缺陷。BLIP3o-60k针对性地补充了这些案例,通过监督微调让模型快速适应这些场景。
实验数据显示,仅用60k数据进行微调后,模型的视觉美感和 prompt 对齐度显著提升,生成 artifacts(如扭曲的物体形状)减少约40%。更重要的是,研究发现模型从AI生成的图像中学习的效率,要高于从真实图像中学习,这为数据集构建提供了新的思路。
性能全面超越:从理解到生成的全栈领先
BLIP3-o在10余个主流 benchmark 上的表现,充分证明了其技术路线的优越性。

在图像理解任务中:
VQAv2(视觉问答)得分83.1,超越EMU3(75.1)和VILA-U(79.4); MMBench(多模态综合评估)得分83.5,领先MetaMorph(75.2)和Janus Pro(79.2); MMMU(多学科推理)得分50.6,大幅超越同类模型的40分左右水平; MME-Perception(感知能力)得分1682.6,刷新开源模型纪录。
在图像生成任务中:

GenEval得分0.84,超过Janus Pro(0.80)和EMU3(0.66); WISE(世界知识推理)得分0.62,展现出强大的常识整合能力; 人类评估显示,在视觉质量和 prompt 对齐两个维度,BLIP3-o以50.4%对44.9%和51.5%对46.1%的优势超越Janus Pro。
值得注意的是,BLIP3-o提供两个版本:8B参数模型(基于专有数据训练)和4B参数模型(完全使用开源数据)。其中4B模型在保持性能竞争力的同时,为资源有限的研究者提供了可复现的研究基础,体现了Salesforce推动开源生态发展的决心。
全开源生态:代码、数据、模型权重一网打尽
BLIP3-o延续了BLIP系列的开源传统,将研究成果毫无保留地分享给社区。目前,以下资源已完全开放:
模型代码:包含训练、推理的完整实现,支持快速部署; 模型权重:8B和4B版本的预训练权重,可直接用于微调; 预训练数据:2500万开源图像-文本对,包含详细 caption; 指令微调数据:60k高质量"文本-图像"对,支持定向优化。
未来展望:从单一任务到复杂场景
BLIP3-o的研究团队并未止步于现有成果,他们在论文中规划了三大未来方向:
图像编辑:利用理解与生成的统一能力,实现更精细的图像修改; 多轮视觉对话:让模型能基于历史对话生成和理解图像,支持连续交互; interleaved 生成:实现文本与图像的交替生成,如故事创作中穿插插图。
这些方向都指向一个核心目标——让多模态模型能像人类一样,在理解和生成之间自由切换,最终实现"感知-推理-创造"的完整闭环。
参考
论文标题及链接
BLIP3-o: A Family of Fully Open Unified Multimodal Models-Architecture, Training and Dataset (https://arxiv.org/pdf/2505.09568)
开源链接
https://github.com/JiuhaiChen/BLIP3o
大模型之心Tech知识星球交流社区
我们创建了一个全新的学习社区 —— “大模型之心Tech”知识星球,希望能够帮你把复杂的东西拆开,揉碎,整合,帮你快速打通从0到1的技术路径。
星球内容包含:每日大模型相关论文/技术报告更新、分类汇总(开源repo、大模型预训练、后训练、知识蒸馏、量化、推理模型、MoE、强化学习、RAG、提示工程等多个版块)、科研/办公助手、AI创作工具/产品测评、升学&求职&岗位推荐,等等。
星球成员平均每天花费不到0.3元,加入后3天内不满意可随时退款,欢迎扫码加入一起学习一起卷!











