从 9.7 万亿到超过 1000 万亿,短短 16 个月间,人工智能革命的加速已超乎我们的衡量尺度。
作者:STEPHEN SMITH
日期:2025年8月7日
生活中,我们时常会遇到一些令人瞠目结舌的统计数据,它们会让你停下脚步,陷入沉思。
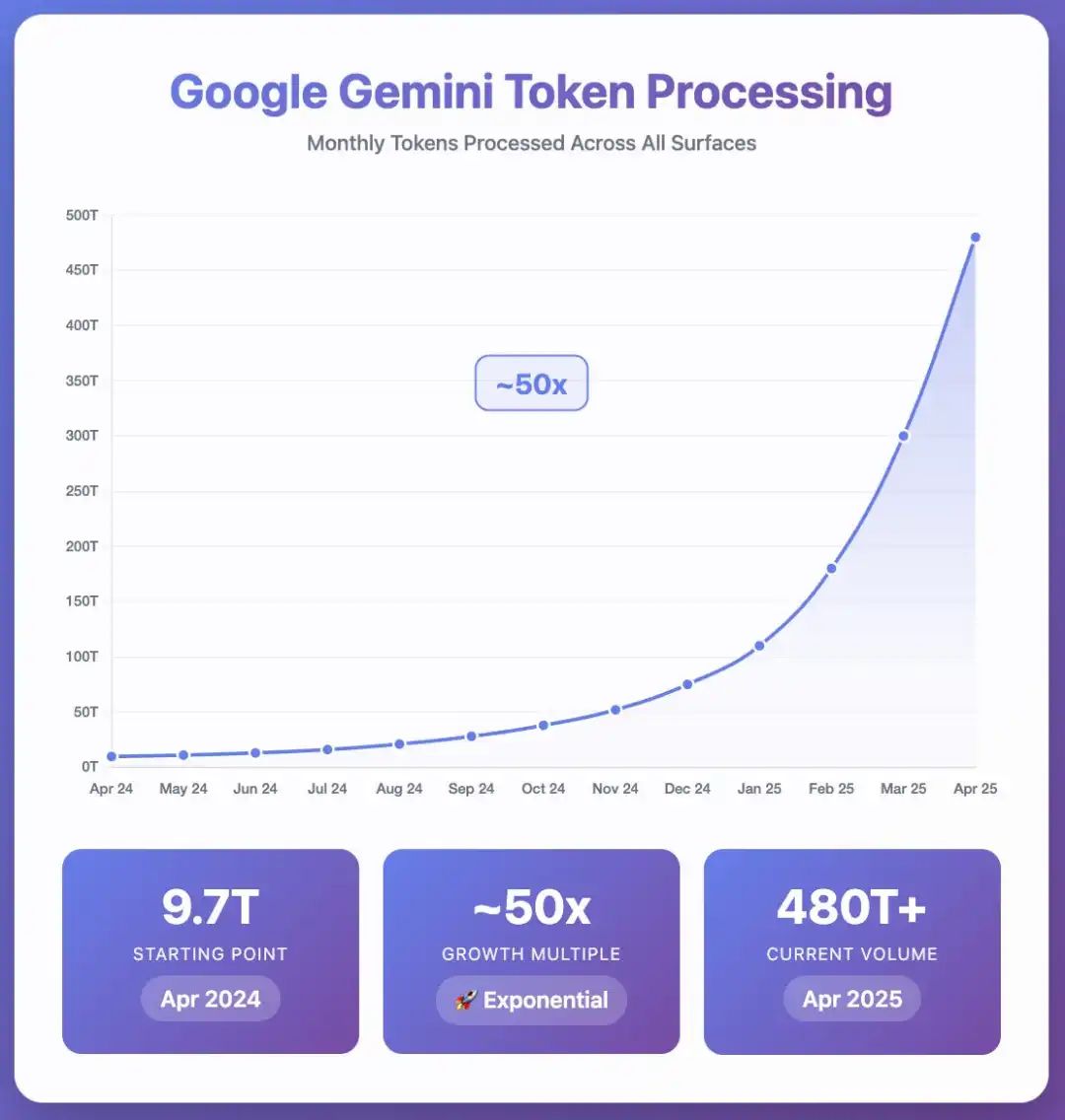
今年四月,在谷歌的 I/O 大会上,我就遇到了这样的情况。当时,谷歌宣布 Gemini 系列模型现在每月处理 480 万亿个 token。
而就在一年前,这个数字仅为 9.7 万亿。这意味着在短短十二个月内,处理量增长了 50 倍。
等等,token 究竟是什么?
让我用一种易于理解的方式来解释。
你可以把 token 想象成 AI 模型消化文本的方式,它会把文本分解成易于处理的小单元。
就像我们逐字阅读一样,AI 模型也是逐个 token 来读取文本。这是它们理解语言的基本单位。
有趣之处在于,token 并不总是一个完整的单词。例如 cat 或 run 通常就是一个 token。
但更复杂的单词可能会被拆分,比如 “understanding” 就可能被分解为 under、stand 和 ing 三个 token。甚至标点和空格也会被算作 token。
那么,token 和我们日常使用的单词之间是什么关系呢?一个很方便的经验法则是,100 个 token 约等于 75 个单词。
加速再加速
当谷歌在 I/O 大会上展示那张标有 480 万亿的图表时,我只知道这个数字很庞大,但没能真正理解其背后的分量。
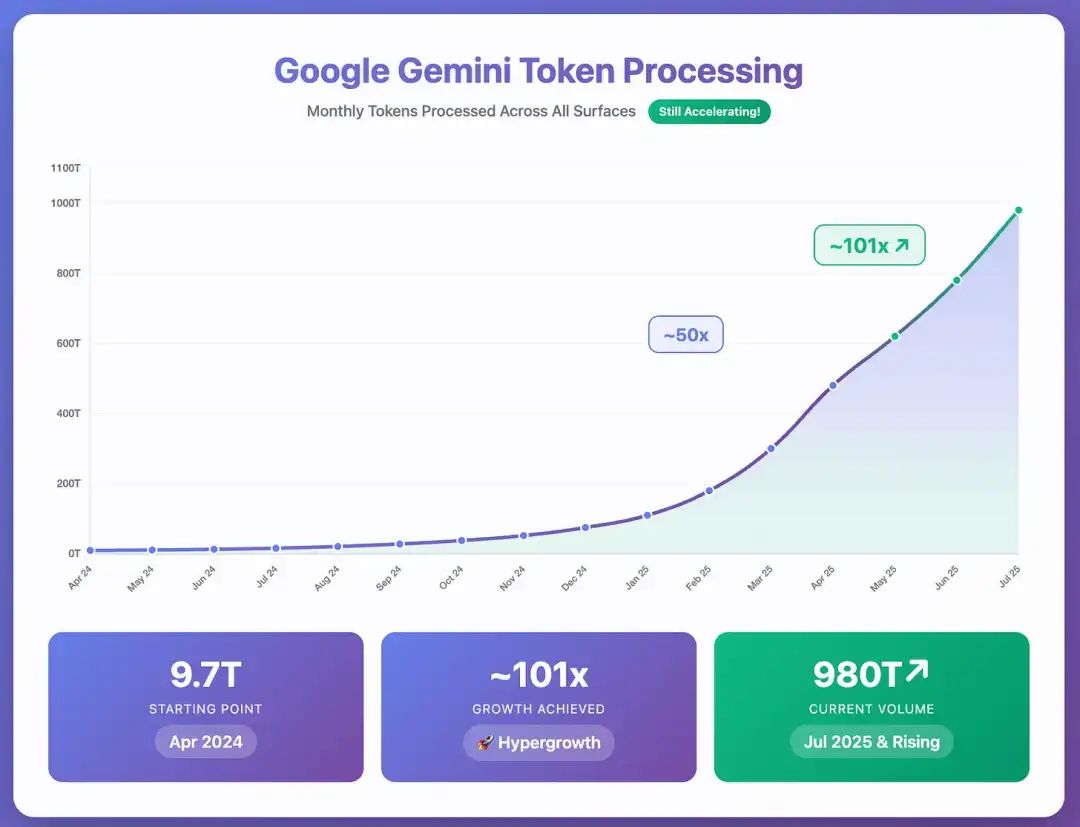
然而,在七月份的财报电话会议上,Sundar Pichai 宣布,从四月到七月,Gemini 处理的 token 数量增长了一倍多。
它们现在每月处理的 token 量达到了980 万亿。我个人从未见过任何事物能以如此惊人的速度发展。
考虑到这一宣布的时间点以及 Gemini 使用量的迅猛增长,现在谷歌的 Gemini 模型很有可能每月处理超过一千万亿个 token。
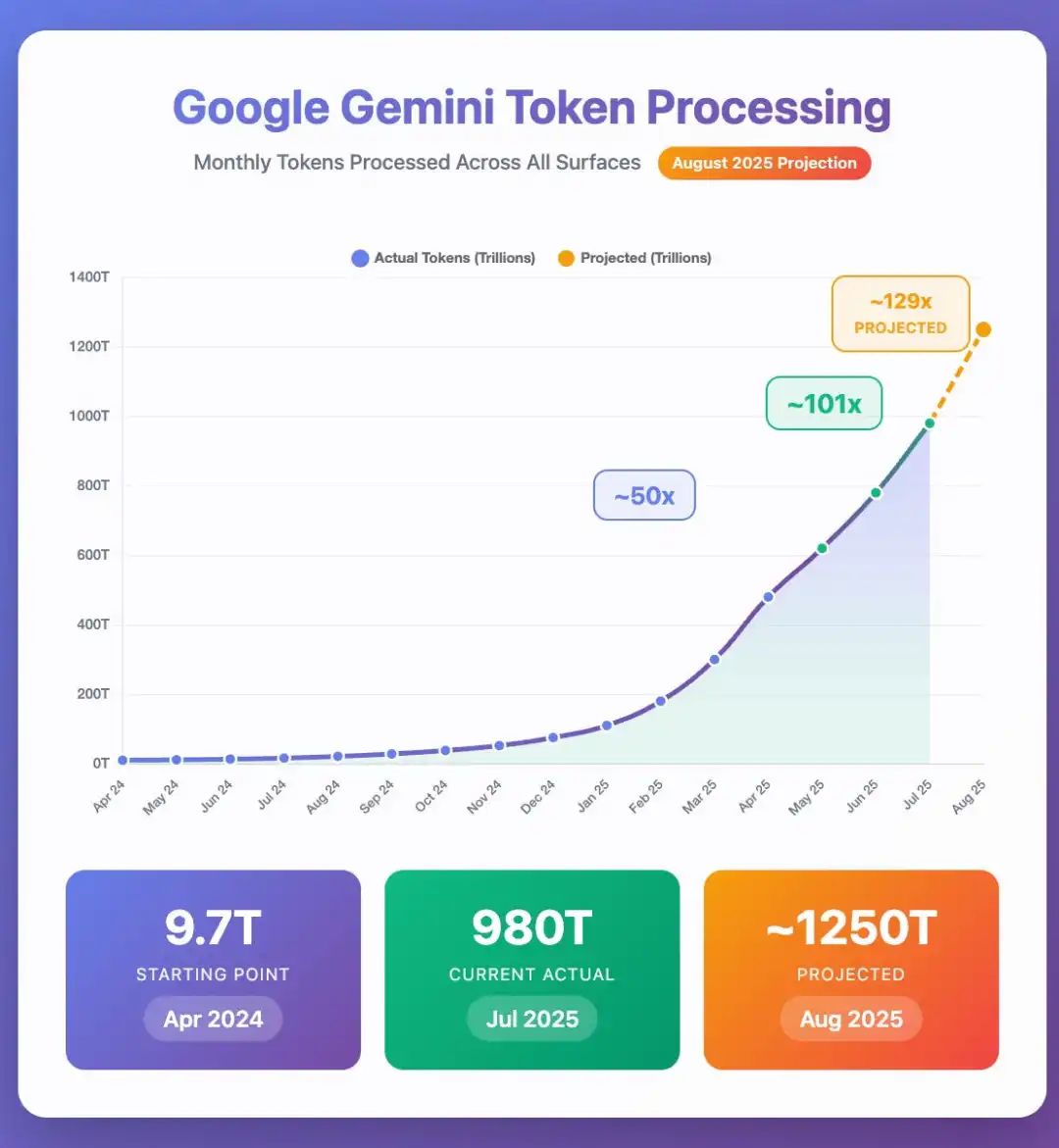
我请 Claude 分析了当前的增长率假设,并对八月底的数据进行了预测。
结果显示,谷歌 Gemini 每月处理的 token 量可能在 1.25 千万亿左右。
让一千万亿变得可以理解
本周,在为一位新客户做 AI 概述演示时,我决定引用 Gemini 模型本月可能已突破一千万亿月处理 token 这一事实。
我希望能把它放在一个具体的语境中,用一种人人都能理解的方式来解释。
我是这样解释的:
1 千万亿个 token 约等于 750 万亿个单词。换算成书页,这大约是 3万亿页。
万物图书馆
如果你把所有这些文本打印成书(每本 300 页),你将得到 100 亿本书。这比地球上每个人分一本书还要多,剩下的还足够给中国的每一个人再发一本。美国国会图书馆拥有约 1700 万本书,这相当于 588 个同等规模的图书馆。
人类写作马拉松
如果地球上的每一个人(80 亿人)都以每分钟 40 个单词的速度、每天 8 小时不停地打字,他们需要将近 5 天的全球同步写作才能产生如此多的文本。
信息的星系
据估计,银河系包含 1000 亿到 4000 亿颗恒星。如果 Gemini 一个月处理的 750 万亿个单词中的每一个都是一颗恒星,你可以创造出数千个我们银河系大小的星系。
超越人体细胞总数
一个成年人的身体估计由 30 到 40 万亿个细胞组成。Gemini 每月处理的单词数量是单个人体细胞数量的 20 多倍。
通往月球的巨塔
如果你将这一千万亿个 token 全部打印在标准的办公用纸上,这堆纸的高度将达到约 25 万公里,大约是地月距离的三分之二。它的高度将比国际空间站高出约 610 倍,比太空边缘(100 公里)高出约 2500 倍。
这些数字令人难以置信,而且增长的趋势还在加速。
这还仅仅是谷歌 Gemini 的处理量,并未计入 OpenAI、Anthropic、xAI 或众多中国开源模型提供商的数据。
世界已经改变,而这场变革才刚刚开始。
我只是觉得这件事极其有趣,并认为各位读者也会有同感。
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!










