点击蓝字
关注我们
2025年8月8日,在历经两年半的漫长等待后,OpenAI正式发布了其新一代旗舰模型系统——GPT-5。此次发布并非如GPT-4诞生时那般带来颠覆性的新功能,而是在性能指标上实现了全方位的“屠榜”,同时其产品形态与用户体验策略也引发了复杂的多维度反响。本文旨在深入分析GPT-5发布初期的全球多维度反应,剖析其技术特征、市场预期、用户体验分化,并结合当前全球AI治理格局,前瞻其可能带来的战略影响与潜在的治理挑战。初步发现,GPT-5的问世标志着AI发展进入了一个新阶段:一方面,其核心技术能力,如推理、编程和事实性,取得了一定突破;另一方面,它也暴露了现有评测体系的局限性,并引发了关于“何为更优AI”的深刻讨论,同时在用户关系和产品伦理层面提出了新的治理课题。

在万众瞩目下,OpenAI终于揭开了GPT-5的神秘面纱。距离2023年3月15日GPT-4的发布已过去近两年半,整个行业对此次更新抱有极高期望。根据发布会及初期用户测评纪要,GPT-5并非一个单一模型,而是一个复杂的、动态调度的统一系统,旨在平衡不同任务场景下的效率与能力。
GPT-5的核心是一个由多个模型组成的集成系统,其设计理念体现了对计算资源优化和任务专业化的高度重视。该系统主要包括:
第一,核心模型组。gpt-5-main是一个高智能且快速的模型,用于处理绝大多数日常和通用查询。gpt-5-thinking则是一个专为处理高难度、复杂推理问题设计的深度模型。用户可通过特定指令,如“认真思考这个”的主动调用。
第二,动态路由器。系统内置一个实时路由器,能根据对话类型、复杂度和用户意图,智能地在main和thinking模型间进行切换。该路由器将根据用户的使用反馈不断迭代优化。
第三,辅助与开发者模型。系统还包括用于处理超额请求的mini版本,以及一个为开发者设计的更小、更快的gpt-5-thinking-nano版本。此外,Pro付费会员还可使用一个利用并行计算能力的gpt-5-thinking-pro版本。
这一架构标志着OpenAI从提供单一通用大模型,转向提供一个多层次、自适应的“AI服务系统”,这是对前代产品在设计理念上的延续。
OpenAI在发布会上公布了一系列亮眼的性能数据,显示GPT-5在多个长期困扰AI领域的“顽疾”上取得了重大进展。
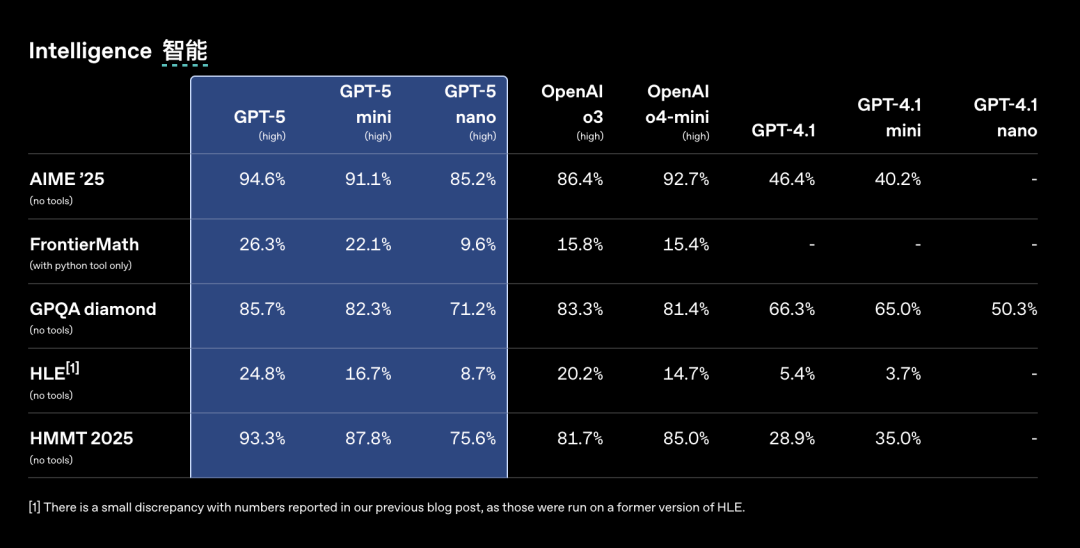
首先,大幅降低事实性幻觉。根据OpenAI的数据,gpt-5-main产生重大事实错误的频率比GPT-4o低44%,而gpt-5-thinking更是比OpenAI o3低了78%。在专业的LongFact和FActScore基准测试中,gpt-5-thinking产生的 factual errors 比o3低80%以上。
其次,有效抑制“模型谄媚”(Sycophancy)。“模型谄媚”指的是在模型规模增大和对话指令微调时,会增加模型的谄媚倾向,模型更倾向重复用户的观点,即使这些观点并不正确。GPT-5在对话中表现得更为客观和深思熟虑,减少了不必要的迎合与情感表达。gpt-5-main在抑制谄媚行为的评估中表现优于最新GPT-4o近三倍,A/B测试显示其谄媚行为发生率在免费和付费用户中分别下降了69%和75%。同时,新增的“愤世嫉俗者”、“机器人”、“倾听者”和“书呆子”四种性格预设,也为用户提供了更便捷的交互风格选择。

再次,性能指标有所优化。在包括数学竞赛(AIME 2022-25)、现实世界编程能力、人类最后知识测试(MGP)以及多模态能力在内的多项基准测试中,GPT-5均刷新了最高分记录。在最新的大模型盲测竞技场(LMSYS Chatbot Arena)中,GPT-5也具备优势。此外,一定程度上提升能源效率。在处理视觉推理、代理编程和研究生级别科学问题等复杂任务时,GPT-5在表现优于o3的同时,使用的输出Token减少了50-80%。

根据Artificial Analysis的排名,GPT-5目前领先第一,综合分比o3高了两分、比Grok 4高一分。

总体而言,从技术上看,GPT-5的发布反映了OpenAI的战略重心——从追求“更大”转向追求“更好”和“更高效”。通过解决幻觉和谄媚等核心问题,OpenAI试图提升模型的可靠性和专业性,以应对日益增长的商业应用和学术研究需求。然而,发布会上出现的图表数据错误(如“52.8大于69.1”)也暴露了其在宣传沟通上的草率,这种“草台班子”的细节失误在一定程度上削弱了其技术叙事的严谨性,可能成为竞争对手攻击的靶点。
尽管GPT-5在技术指标上取得了压倒性优势,但发布后24小时内的市场与用户反响却呈现出一种极为复杂和分化的局面,远非一片赞誉。

综合8月8日最新的国际媒体报道,《卫报》《华盛顿邮报》等媒体肯定了GPT-5在医学、编程与推理能力的飞跃,西班牙《国家报》甚至将其称为“企业级AI应用的里程碑”。生物技术巨头Amgen已部署该模型,盛赞其在临床模糊性管理中的精准表现。然而,市场对OpenAI的AGI叙事保持审慎。《卫报》认为,开发者虽将GPT-5喻为“口袋里的博士级专家”,却坦承其缺乏“持续学习能力”,无法实现真正的人类替代;《华盛顿邮报》则警告欧盟“高风险模型”分类可能引发合规成本激增,叠加发布会“图表比例失实”事件,技术透明度再遭质疑。
对于大量将ChatGPT用于日常写作、创意和情感交流的普通用户而言,初期的体验甚至带有明显的“降级感”。
首先是产品策略的争议。OpenAI在为用户升级至GPT-5时,直接移除了GPT-4.5、GPT-4o乃至o3的访问权限。对于许多已经习惯并高度评价GPT-4.5特定能力的用户来说,这是一种强制性的、且令人不安的改变。一位忠实用户悲伤地记录了他与GPT-4.5的“告别”,其回复“让我动容”,这反映了用户与特定AI模型版本之间已建立起深厚的情感联系和工作流依赖。
其次是创造性与情感智能的退步感。根据初期深度用户的测评,GPT-5在需要微妙文笔和情商的场景下,表现不如已被下架的GPT-4.5。例如,在模仿鲁迅文风写一篇关于“被昂贵咖啡厅坑了”的短文时,GPT-5的输出被评价为“蹩脚的破折号、双引号泛滥,而且文风完全不鲁迅”,而GPT-4.5的旧作则被认为“文笔根本就不是一个级别的”。同样,在处理一些需要“高情商”的场景题时,GPT-5的回答显得“情商很低”,远不如GPT-4.5的回答得体。
还有用户反馈,GPT-5在指令遵循的精确性上表现“非常一般”。这些负面的反馈揭示了一个深刻的问题,AI的“智能”是多维度的,而当前行业主流的基准测试可能无法完全捕捉到用户在创造性、情感共鸣和个性化风格等方面的细腻需求。OpenAI为了系统的统一性和维护成本,选择“一刀切”地淘汰旧模型,忽视了部分用户群体的“版本遗产”价值和使用惯性,这是一个值得商榷的产品伦理和用户关系管理策略。
此外,《华盛顿邮报》的最新报道还揭露了体验的割裂性。免费用户遭遇严格额度限制(触发后强制降级至旧版),而深度功能如Gmail/日历集成、百万级上下文处理,仅向月费200美元的Pro用户开放。这种“功能分层”策略引发普通用户不满,被质疑背离技术普惠初衷。
与普通用户的失望形成鲜明对比的是,开发者社区对GPT-5的评价普遍非常积极。在专业的编程和开发任务中,GPT-5展现出了惊人的实力。

首先,代码生成与修改能力超群。一位开发者在尝试开发“粤语学习应用”时,对GPT-5、Claude 4 Opus和Gemini 2.5 Pro进行了对比测试。结果显示,GPT-5生成的UI设计更受青睐,且在后续“生产级别的任务里面进行精准修改”这一高难度环节中,当Claude和Gemini均告失败时,GPT-5“完成的非常好”。
其次,超强的上下文精度。其他开发者的测试也证实了这一点,认为GPT-5展现出极强的上下文处理精度。一位开发者通过屏幕录像展示了GPT-5如何精确理解并执行复杂的代码修改指令。
开发者社区的正面反馈表明,GPT-5的核心优势可能在于其强大的逻辑推理、代码理解和长上下文精确遵循能力。这使其在作为专业生产力工具方面,实现了对竞品的代差级领先。这种体验上的“冰火两重天”,也就是普通用户感到失望,而专业开发者感到惊喜——预示着AI模型市场可能会进一步细分,模型的能力评估也将更加依赖于具体的应用场景。
GPT-5的发布凸显了当前AI评测体系面临的严峻挑战,主要有以下两个方面。
第一,缺乏第三方独立验证。截至目前,全球尚未有任何权威的第三方机构发布针对GPT-5系统(包括main和thinking模型)与GPT-4o、Claude 4、Gemini 2.5等竞品的独立、全面的基准测试报告 。所有关于其性能优越性的数据均来自OpenAI单方面发布,且其发布会材料的严谨性存疑。
第二,基准测试与用户感知的脱节。即便OpenAI的数据无误,GPT-5“屠榜”的客观事实与大量用户主观体验的“降级感”之间存在巨大鸿沟。这表明,如MMLU、GPQA、HumanEval等传统基准,虽然在衡量模型的知识储备和逻辑推理能力上依然重要,但已无法全面反映模型在创造力、文体风格、情商、用户交互友好度等方面的真实水平。那位用户关于鲁迅文风的吐槽,便是对现有评测体系“盲区”的生动控诉。
我们可能正在进入一个“后基准测试时代”。模型的竞争不再仅仅是分数的比拼,更是综合体验、特定场景下的可靠性以及与用户契合度的较量。这对AI治理提出了新要求:我们需要推动建立更多元、更注重定性评估、更能反映真实世界复杂需求的评测框架。
目前没有任何国家政府或国际组织就GPT-5的部署发布了具体的政策声明或监管指南。这符合技术发展的普遍规律,即监管的反应通常滞后于技术的突破,形成一个短暂的“政策真空期”。尽管没有专门针对GPT-5的法规,但过去对强大AI模型的普遍担忧无疑将因GPT-5的强大能力而被放大。此前要求暂停更高级AI研发的呼声,可能会再次出现。
OpenAI在发布时重点强调GPT-5在“减少事实性幻觉”和“抑制谄媚”方面的巨大进步,可以看作是一种主动的、先发制人的“治理公关”。他们试图向监管机构和公众表明,自己正在认真对待并用技术手段解决AI最受诟病的几个核心问题。
这个“真空期”是各国政府和国际治理机构进行观察、研究和制定对策的关键窗口。未来的监管辩论将可能围绕以下几个新焦点展开:
首先是评估标准的权威性,到底由谁来定义和验证一个模型是否“安全”、“可靠”或“更好”?是否需要建立独立于开发商的全球性AI测评机构?
其次,产品策略的伦理边界在哪?AI公司是否有权在未提供替代方案的情况下,单方面淘汰用户高度依赖的旧模型版本?这是否构成一种新的数字权力滥用?
再次,开发者工具与公众应用的差异化监管。鉴于GPT-5在专业和通用场景下表现出的巨大差异,是否需要对作为生产力工具的AI和作为信息与情感伴侣的AI采取不同的监管方法?
GPT-5的全球亮相,标志着人工智能技术迈入一个矛盾交织的新纪元。其突破性的系统架构与性能优化,在解决“幻觉”“谄媚”等核心顽疾上取得了可量化的成就,技术指标的“屠榜”彰显了OpenAI从追求规模转向追求效能与可靠性的战略转型。然而,发布会中的图表失误与技术叙事的草率,暴露了科技巨头在严谨性上的软肋,也为对手提供了攻击的切口。
GPT-5的破晓之光,既照亮了技术前行的复杂路径,也投下了治理与伦理的浓重迷雾。其启示在于,AI的未来竞赛,绝非仅是性能分数的角力,更是综合体验、场景可靠性及人文契合度的整体较量。唯有推动技术能力、用户体验与治理框架三者的协同进化,在追求效率与精准的同时,守护创造的温度与选择的自由,人类方能在智能黎明中,真正驾驭而非迷失于自己创造的奇迹。
排版丨李森(北京工商大学)
审核丨梁正 鲁俊群
清华大学人工智能国际治理研究院(Institute for AI International Governance, Tsinghua University,THU I-AIIG)是2020年4月由清华大学成立的校级科研机构。依托清华大学在人工智能与国际治理方面的已有积累和跨学科优势,研究院面向人工智能国际治理重大理论问题及政策需求开展研究,致力于提升清华在该领域的全球学术影响力和政策引领作用,为中国积极参与人工智能国际治理提供智力支撑。
新浪微博:@清华大学人工智能国际治理研究院
微信视频号:THU-AIIG
Bilibili:清华大学AIIG










