
虽然电子工程专辑这些年始终在关注国产显卡,也部分理解国产显卡及其软件、生态发展情况,但实际很少有机会具象地感知国产显卡厂商和国际巨头间的差异。
可能国内为数不多的、能直接在消费市场上买到的国产显卡,也就是摩尔线程MTT S80了——社交网站也早就有了不少这款游戏显卡的体验文章或视频。但3年过去,因为一些众所周知的原因,MTT S90迟迟未能面世。
前不久有媒体直接拿摩尔线程两年前推出的MTT S4000做了图形渲染和游戏性能测试——这原本是个用于AI、面向数据中心的加速卡,就像NVIDIA A100/H100那样,并不会在图形渲染固定功能单元上下猛料。但测试结果还是令人惊喜的,在3DMark、Unigine Valley这类图形渲染测试里,MTT S4000的性能表现竟然和GeForce RTX 4060相似;《永劫无间》这类游戏的实测性能甚至还略有优势。

也许S4000比4060快,听起来好像也不怎么样。但大家要知道,H100是比4060在图形渲染性能上更弱的。至于AI性能,S4000是4060的50倍。那么自然不难想象,原本可能有机会问世的MTT S80迭代产品(传说中的MTT S90),在图形渲染方面针对优化以后,可能在游戏与视觉应用性能上表现出怎样的水平。
当然图形渲染只是张建中描述“全功能GPU”的一部分,现在大众更关注的是GPU板卡的AI加速与高性能计算能力——这也是国产显卡及AI芯片受关注的关键所在;更重要的是,当国产GPU以千卡万卡的方式构成训练推理集群,其性能、效率、稳定性等方方面面,又有着怎样的实际表现。
借着摩尔线程的技术分享日,我们大概能从中窥见一二。虽然摩尔线程当天分享的信息整体上还是偏高抽象层级和大方向的,但依然能从中看到摩尔线程做GPU的思路——毕竟现在还愿意面向媒体去谈技术的国产GPU厂商是不多的。

本文篇幅较长,可按照索引做选择性阅读:
Part 1 AI工厂的定义
Part 2 全功能GPU
Part 3 MUSA架构
Part 4 MUSA软件栈
Part 5 KUAE集群的效率与可靠性
Part 6 推理解决方案与结尾
组建“AI工厂”的逻辑
DeepSeek兴起之后,由于其训练效率的显著提升,年初很多人评价AI计算的Scaling Law不复存在。电子工程专辑和国际电子商情相继在3月刊和4月刊的封面故事,详述论证过这一说法的荒谬性。
摩尔线程副总裁王华进一步明确了Scaling Law仍在持续的大趋势。他在技术分享中给出了下面这张图:左边的散点图表示随时间推移(横轴为时间)、AI模型的算力需求变化(纵轴为FLOPS,刻度为指数级变化)——如2020年顶级AI模型训练的算力需求在10^23 FLOPS量级,2025年则有了千倍增长。“基于Scaling Law,参数量和数据量的增大,会带来大模型最终效果的提升。”

右边的表格则更明确地列出了几款主流模型,采用NVIDIA H100千卡集群、五千卡集群、万卡集群,在对应MoE和dense模型的MFU利用率之下做训练,所需的时间。如DeepSeek V3,千卡需97天,五千卡缩减至22天,万卡则要13天;虽然相较训练GPT-4所需时间的确短了不少;但对比早两年的GPT-3,仍有量级提升。
这是AI计算对于AI基础设施仍旧苛求的一部分体现。无论是当代大模型的“智力”提升幅度惊人(DeepSeek半年内的智力提升就达到了50%,基于Artificial Analysis的数据),还是模型更新频率越来越高,以及模型从单纯的文本走向对多模态的支持,成功的秘诀,除了数据之外,就是AI infrastructure人工智能基础设施了。
“算力越大越好,大到什么程度才行呢?至少我们现在还没有看到边界(limit)。”他在主题演讲中提到的另一个比较有趣的逻辑是,生成式AI相比更早期的感知式AI,技术实施的“门槛更低”,这很大程度上得益于算法层面的高度标准化,Transformer成为当代大部分生成式AI模型的基础结构。
这种算法标准化带来的门槛降低,使得竞争焦点更集中于算力资源的规模与效率。也正因如此,Grok 4有机会在Artificial Analysis的智力指数排行中名列第一,很大程度得益于其背后支撑的20万张卡。基于这些购得的显卡,马斯克能够快速构建起先进的AI infrastructure,用更少的人力、足够大的算力,并最终实现了领先地位。同时,这也再次验证了Scaling law定律,在AI发展进程中的决定性作用。

这也是摩尔线程提出“AI工厂”的大背景和基本逻辑,简单来说这就是一种对AI基础设施建设的强调,无论其内涵有多少变化。相比半导体晶圆厂一步步走向晶体管微缩更小的工艺节点,AI工厂要满足的是更大规模参数量的AI模型训练与推理。
我们理解芯片企业提类似概念的内在逻辑,在于和加速计算时代之前的芯片厂商在算力方面扮演的角色不同,GPU及AI芯片企业不仅需要具备造芯片、板卡的能力,还要有构建系统、节点、集群,以及打造承载生态的软件,甚至上层应用的能力。所以AI工厂的构建来说,不是堆万卡,就能训练出万亿参数大模型;就像不是买两台光刻机就能造出3nm芯片一样。”
“AI工厂的关键首先是算力芯片;此外片间互连、卡和卡的互连、节点和节点的互连;乃至大集群的管理方式、算法;软件层面各种不同的driver、工具、支持——包括算子、库、框架等等......都关系到AI工厂的能力。”
所以下述PPT中,从底层GPU芯片到其上基础软件,以及网络拓扑、互联协议、能效系统、故障容错、存储体系、调度系统、数据处理、分布式训练、后训练系统、大型集群推理都是在组建AI工厂时需要纳入考量的问题。如此才能像芯片晶圆厂那样,具备更高的芯片良率和产能,类比于AI工厂“多长时间能训练出海量参数与数据对应的模型,而且是以高质量的、不需要re-train方式达成的”。

基于过去我们一直在谈的,当代GPU与AI芯片企业需要具备“端到端的能力”,摩尔线程提出了:AI工厂效率 = 加速计算通用性 × 单芯片有效算力 × 单节点效率 × 集群效率 × 集群稳定性。
怎么搞定这5要素?
不过这个等式中的首个要素“加速计算通用性”存在的逻辑,第一部分未曾探讨——这里简单说一说。张建中在演讲中花了较大篇幅去谈GPU加速计算的发展史。
电子工程专辑曾在前些年的《AI芯片专用好还是通用好?遥想20年前GPU也面临这一抉择》一文中探讨过这个问题,图形加速从早年的ASIC,走向图形计算可编程,乃至在CUDA诞生后具备面向通用计算加速的编程能力,相继在超算、HPC、模拟仿真、AI领域成为主流......当时我们是为了论证AI芯片也需要具备通用性。
张建中谈这段历史则是为了表明“全功能GPU”的重要性,真正的算力绝不是仅能完成单一任务的算力。GPU带来的“算力革命”在摩尔线程看来,几乎所有算力都可以由全功能GPU驱动,所以时代需要全功能GPU,这不是普通的图形加速GPU,也不是单一功能的所谓GPGPU,而是全功能GPU。
在“AI工厂效率 = 加速计算通用性 × 单芯片有效算力 × 单节点效率 × 集群效率 × 集群稳定性”这一等式里,摩尔线程满足“加速计算通用性”的,自然就是“全功能GPU”,用以“实现加速计算通用性”。张建中明确提到,这里的“全功能”涵盖AI计算加速、图形渲染、物理仿真和科学计算、超高清视频编解码四大引擎。这都符合我们对当代GPU的主流认知,早两年英伟达宣传自家技术的三个大技术栈就分别是NVIDIA AI/HPC/Omniverse。

其GPU通用性实现基础,除图形渲染需要通用单元之外的固定功能单元——文首S4000的例子已经说明一切。一方面在于硬件层面摩尔线程GPU的“全精度”支持,包括同时满足HPC及AI计算的FP64, FP32,及包括FP8、BF16/FP16、INT8等在内的各种计算精度;另外应当也在于摩尔线程对其MUSA生态的开发——对应到CUDA生态,这是个需要投入大量人力物力的工作。
值得一提的是,当面向AI加速时,摩尔线程的全功能GPU面向“AI全场景”加速,满足AI训推的要求,在科学计算、工业智能、自动驾驶、具身智能、生物制药、AIGC、AI智能体、游戏等领域全面应用。这从今年WAIC之上的展位布置就看得出来——摩尔线程展位上展示的应用,除了AI大模型训练和推理之外,还包括GPU在生命科学、物理仿真、创娱教育、智能制造、智慧医疗、汽车座舱+ADAS,当然还有视觉方向上于空间智能、视频超分等场景的应用...


▲上面这台名为“AIBOOK算力本”,兼容CUDA/MUSA双架构;下面这两款分别是依托摩尔线程全功能GPU的物流无人机(来自紫光计算机)以及来自柳工的CLG922E挖掘机——搭载MindEdge L100边缘计算平台;WAIC现场类似的行业应用展示还有不少…
这里单独将“全功能GPU”拿出来谈,也是为了呈现摩尔线程GPU的目标应用及对自家产品的定位。从这个角度来看,摩尔线程凭借其“全功能GPU”的定位,选择了一条与NVIDIA高度重合的发展路径、形成了全面的竞争态势,这与国内其他GPU或AI芯片企业许多都尝试避开NVIDIA在通用大市场的竞争锋芒截然不同。
而针对等式的后四个要素,摩尔线程的解决方案分别是:自研MUSA架构、MUSA全栈系统软件、自研KUAE计算集群、零中断容错技术。加上全功能GPU,将这5大要素代入上述AI工厂效率的等式,就得到了:
摩尔线程高效AI工厂 = 全功能GPU × MUSA架构 × MUSA软件栈 × KUAE集群 × 零中断容错技术
那么接下来,我们就分别简单看看摩尔线程在后四个要素上具体是怎么做的。
MUSA架构:从芯片,到计算、通信、内存
摩尔线程的看家本领之一,显然就是GPU的自研MUSA架构。针对MUSA架构在AI工厂中的价值,张建中提到了几个关键技术点,其中不少应该是已经经过了迭代的:(1)MUSA多引擎可配置统一系统架构;(2)自主研发的AI计算加速系统;(3)FP8创新加速Transformer计算;(4)ACE异步通信引擎;(5)MTLink 2.0;(6)MUSA内存子系统升级。
有关第(1)点,下面这张框图给出了“一个架构覆盖各应用场景”的基本逻辑与方式。追踪电子工程专辑对NVIDIA GPU及生态技术报道的读者应该知道,NVIDIA也始终在倡导类似的设计方法路径。

一个MUSA支持所有场景,但MUSA比CUDA考虑更周到的是,摩尔线程也考虑明天的计算。MUSA全称Meta-computing Unified System Architecture——元计算统一系统架构,“我们相信,未来无论什么样的计算,我们相信元计算会支持所有应用场景。”
张建中说基于这一设计思路,“在顶层架构中,我们就考虑到计算、通信、内存,指令间的交互、协调等等”,在多方考量之下“我们发明了MUSA多引擎、可配置、统一系统架构”。
上层面向开发者时,通过统一编程接口,“利用统一编程的指令集,驱动MUSA架构之下的所有引擎”;包括图形处理、通用计算、多媒体、通信等引擎,“将图形渲染、超级计算、张量计算、编解码等操作融合起来,随意调动”;同时“所有引擎都在统一内存子系统上工作,实现效率最优化”。

作为“AI工厂”,芯片必然需要具备(2)“自主研发的AI计算加速系统”。对此,张建中谈到了TCE(张量计算引擎)、TME(张量访存引擎)和ATB(引擎异步流水)。对于TCE,尤其其中的MMA(Matrix Multiply-Accumulate,乘加单元),大大小小各种不同复杂结构,摩尔线程需要将其完美组合起来;至于访存相关的TME,何时更快、更充分地发挥存储效率,都需要TME来管理和调度。
而如何让AI工作负载“有条不紊”地高效开展,摩尔线程做了ATB(引擎异步流水),尽可能将TME、TCE和MUSA核心的工作做到流水线化(Pipelining),避免或缓解等待问题。
此外,摩尔线程也特别强调了(3)摩尔线程GPU对于FP8数据格式支持的重视和“专门设计的支持FP8的Transformer Engine”,利用FP8计算来加速Transformer运算——这是这一代平湖架构上专门设计的一大核心科技。
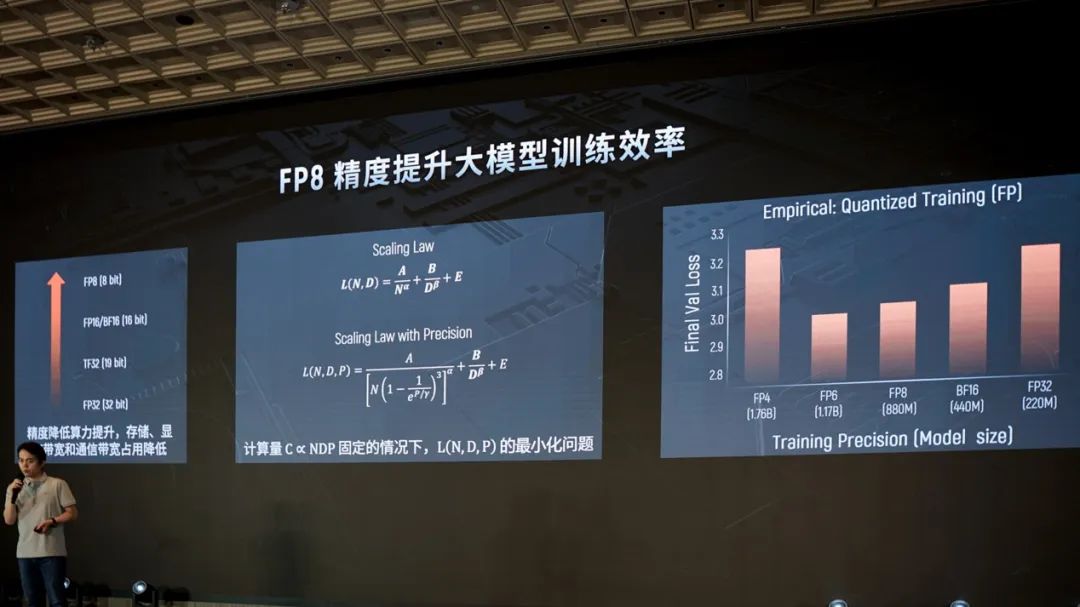
DeepSeek更好地应用混合精度训练之后,AI芯片对FP8的高效支持也显得愈发重要。王华在谈Scaling Law时就提到,当等式引入精度变量(上图中的P),除了数据量(D)和参数量(N)之外,精度也变得重要。在总的计算量固定的情况下,要考虑的是合理配置这三个值,达到L(损失函数)的最小。
从上图中的第三张柱状图可见,“从loss值来看,FP6, FP8是最佳甜点区域。”王华说道,“从这份研究结果来看,引入精度后的Scaling Law,FP8是相对合理的选择。现在我们通常用BF16来做训练,而FP8的部分替换还会令其有进一步的提升空间。”他也谈到了低精度训练存在的挑战、FP8训练的支撑技术本身的进步,以及DeepSeek-V3使用FP8混合精度训练大幅提升了效率的事实(前向与后向传播的3次GEMM矩阵乘使用FP8,激活值缓存和传输使用FP8)
平湖架构中的Transformer Engine加速,相比没有FP8(原生支持),训练性能提升了30%。这相当于花同样的钱却能得到30%的收益,这是非常有价值的。摩尔线程也希望开发者能够充分地用好它。这里所说的“引擎”应当也和NVIDIA在Hopper架构上引入的Transformer Engine相似,是某种抽象或软硬协同的框架,而不是硬件层面具体的某个物理设计。

王华也提到摩尔线程在FP8训练上,“提供了软硬件的完整支持”,尤其依托于软件栈上的Torch-MUSA(PyTorch的MUSA插件,提供MUSA后端加速支持,也实现了FP8数据类型的完整支持)、MT-MegatronLM(支持FP8混合精度训练)、MT-TransformerEngine(基于硬件层面适配优化,做到对FP8算力的充分利用)。据说摩尔线程基于这些,“成功复现了DeepSeek-V3满血版的训练过程”,“是行业里的唯一一家”,得到了相当理想的结果。
更多摩尔线程在FP8训练上的实践和探索,受限于篇幅,本文不再多做介绍。
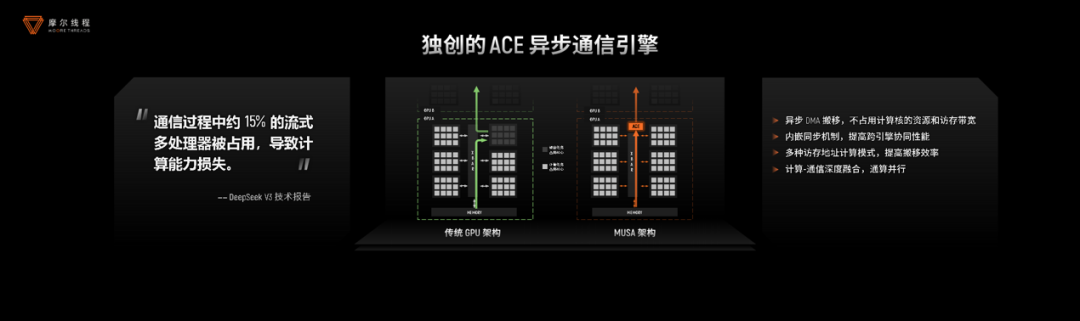
而(4)ACE异步通信引擎,则着眼于解决通信开销问题。就连NVIDIA GPU也需要“腾出一批人,专门去做通信,这就好比“雇了6个人,但却只有5个人在干活儿,另1个需要去送情报”。
摩尔线程GPU计算软件开发总监吴庆援引DeepSeek-V3发布paper时提及训练所用NVIDIA GPU,大约15%的SM(Steaming Multiprocessor,NVIDIA针对其GPU计算单元的称呼)计算资源需要用来做通信,故而“建议硬件厂商设计独特的硬件进行数据通信”,而计算单元SM理应“全部用于计算”。实际上,NVIDIA近代GPU架构都在尝试缓解该问题。
平湖设计阶段远早于DeepSeek V3发布的时间,彼时摩尔线程已洞察到行业痛点,并提供了解决方案——在GPU上增加了一个异步通信引擎。
“异步通信引擎原生支持数据Reduce操作;支持常用的ADD, MIN, MAX等操作;计算精度方面支持FP16, BF16等数据类型;ACE可以直接通过 MTLink 进行C2C数据通信。”吴庆还强调,这项技术“通过zero copy技术进一步提升性能”,“直接把数据buffer跨卡通信”。
搭配后文将提到的MTLink 2.0,尽可能实现计算与通信的并行。“将通信部分offload到单独的通信引擎上,不跟MPC(MUSA Processor Cluster,与NVIDIA SM相似层级的计算单元概念)争抢资源,在无数据依赖时还能做到完全的overlap(并行)。”“基于ACE加速的MT-TransformerEngine,能做到非常好的计算与通信的overlap。”“端到端获得10%的性能提升。”
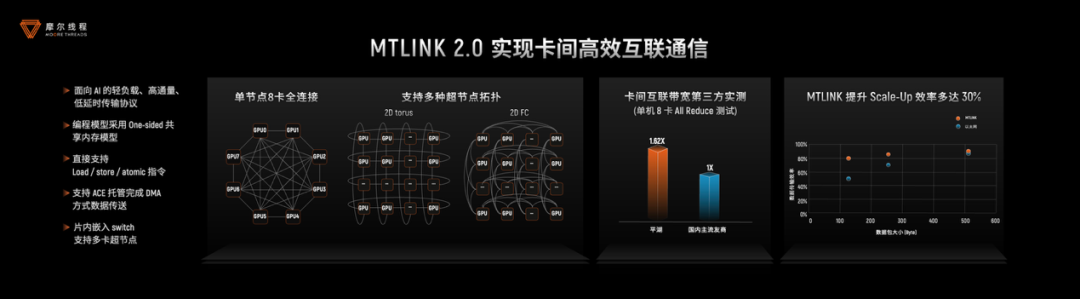
此处的MTLink应当可以对应到NVIDIA NVLink。第(5)点平湖架构升级的MTLink 2.0,相比前代达成了更高的效率。作为“面向AI的轻负载、高通量、低延时传输协议”,支持多种超节点拓扑,“在各种复杂拓扑结构之下,GPU之间的通信都能做到高效”;亮点如“编程模型采用one-sided共享内存模型”,“支持load/store/atomic所有指令”,“可以利用ACE去托管完成DMA才可以实现的数据搬送的方式”。
总的来说,数据传输效率(scale-up域内)最多提升30%,不同数据包大小传输效率平均15%以上。
吴庆给出了一些更具体的数据,ring算法做AllReduce通信,延迟大约53μs,基于FC8算法单机8卡全连接场景仅需7.8μs。而MTLink 2.0 + FC8拓扑,也就是单机8卡做scale-up,结合通信kernel优化,软件带宽利用率可达85%,和国际第一的厂商在软件效率上对齐。

另外吴庆还提到了scale-out方向上的扩展——毕竟摩尔线程的AI工厂是个大型智算集群。“我们对MCCL集合通信库做了拓扑和路由的优化:让每个GPU进出节点通信时,都能找到离它最近的网卡端口,进行RDMA通信。”同时,针对双口四网卡方案,“我们额外开发了Smart NIC Adaptar插件,实现和单口8网卡一样的RDMA通信效率。”
最终实测“双机16卡”(每个scale-up域内8张卡),每个GPU搭配200Gbps的单口八网卡或双口四网卡,“端到端RDMA带宽可达194GB/s,也就是接近97%的带宽利用率。一般行业普遍能做到的水平在80-85%之间,而我们是可以做到97%的。”

还有最后在存储方面,(6)MUSA内存子系统的升级,也能有效提升数据传输能力。摩尔线程预告,这部分预计将在10月份的开发者大会上做详解。“简单来说它不仅节约带宽、提升效率,同时更加稳健可靠。”
软件栈:提升计算效率的关键
实际上面的MUSA架构部分,已经或多或少地谈到了软件相关的内容,毕竟性能与效率提升就是软硬协同达成的。摩尔线程对这部分的综述是“通过高效的基础软件库,框架算法创新和完备的开发工具链,提供单节点计算效率”。
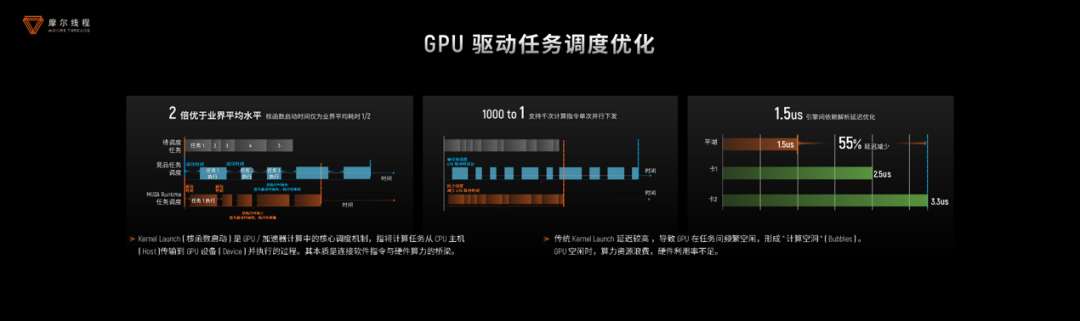
首先是GPU驱动和runtime层面的优化。任务调度上,即时任务下发(instant task dispatch)让kernel(核函数)启动时间大幅降低。“传统的kernel下发,由于kernel间需要做配置,存在开销、会产生空泡(bubble)。此时GPU的算力是闲置的。”吴庆说,“我们通过即时任务下发深度优化,将延迟降到行业平均水平的一半左右”,“在上个kernel执行结束前,就将下个kernel要做的配置提前做好,最大限度降低kernel和kernel间调度的延时开销。
同时做“批量任务下发”,批量下发计算和通信任务。“将几百上千甚至更多kernel打包,一次下发,上千次调度开销编程一次,空泡一次性挤掉”。“典型场景是MUSA Graph”,将多个kernel整合到一个graph中,通过单次CPU调度大幅减少启动开销。“具体收益取决于graph里面kernel本身的执行时间和kernel间的调度空泡”,“不同场景下,可以达到百分之几十,甚至几倍的性能收益”。
还有依托“引擎间依赖解析”——前文提到摩尔线程的“GPU是多引擎可配置的”,“不同引擎要做依赖分析、交互、同步等。传统方案往往需要回到host端,速度很慢。平湖架构支持用硬件解析这些引擎间的依赖,大幅降低延迟。”因此做到任务流依赖解析延时1.5μs,“优于业界头部算力卡”。
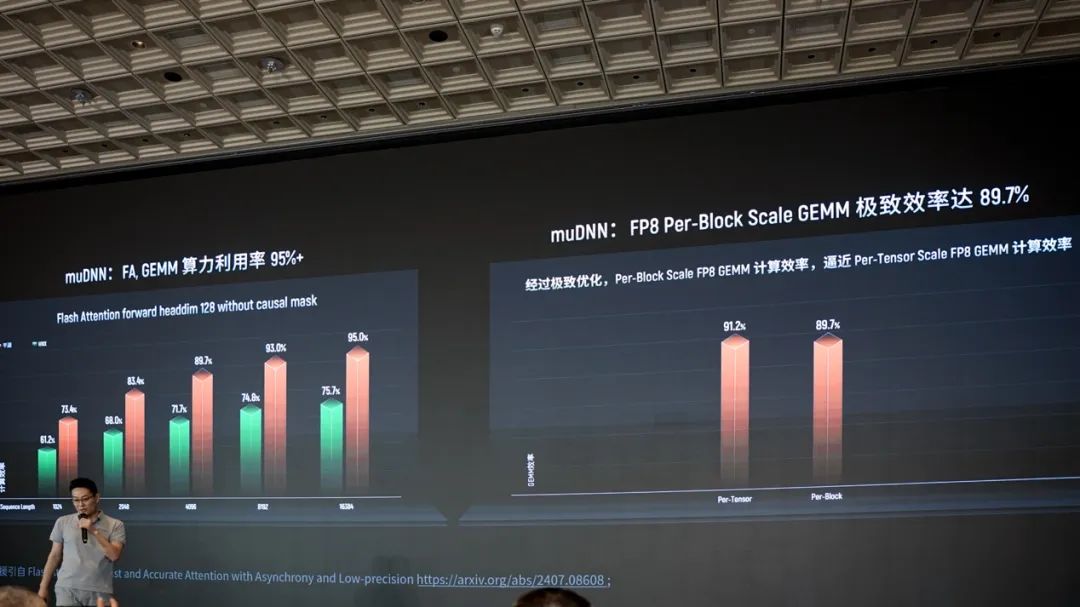
其次在MUSA算子库生态的完善和高效上。吴庆表示当前muDNN算子性能优化远超行业水平,并举例称Flash Attention算法的GEMM算力利用率超过95%(这里Hopper的利用率数据来自题为"FlashAttention-3: Fast and Accurate Attention with Asynchrony and Low-precision"的paper)。
且Per-Block Scale FP8 GEMM计算效率逼近Per-Tensor Scale FP8 GEMM计算效率(91.2% vs 89.7%)。Per-tensor和per-block是应用scaling factor颗粒度上的差异。通常我们说per-tensor scaling更快、更简单,但可能损失精度;而per-block scaling在操作上更细粒度。两者达成相似效率,应该是能够表明摩尔线程在软硬件上下的优化工夫的。
有关MUSA算子库生态,吴庆总体上介绍了摩尔线程的三大算子库(a)muDNN——标准算子库,覆盖完整的前向和反向运算;(b)MUTLASS——开源的高性能线性代数模版库,也提供优化示例,降低开发者去做自定义算力的工作量,“已经迭代过一个版本”,目前支持S5000的所有特性;(c)还有预计下半年要发布的MUSA AI Tensor Engine——特别面向LLM的开源推理算子库,据说对标PTX虚拟指令集的MTX届时也会问世。
当然还有前文已经提到的MCCL集合通信库的进一步优化,实现“硬件级异步通信与自适应高效互联”,给大模型训练集群整体性能带来10%的收益,RDMA通信带宽利用率97%;
以及FP8计算优化,软件层面从AI框架和算法上着手;且“首创细粒度Variant Recompute”,“让训练精度可保持更高、累积误差更小”,同时“计算开销减少4倍”(相比于Megatron-LM Recompute,recompute本身是一种节约存储资源的技术方案,在向后传递过程中进行部分重算);
其他软件相关的开发生态建设工作还包括了如Triton-MUSA(嫁接Triton语言和和MUSA架构),达成对vLLM, SGLang等的广泛支持;MCC自研编译器;面向开发者的用于开发、优化、部署、运营等不同环节的工具套件等等。
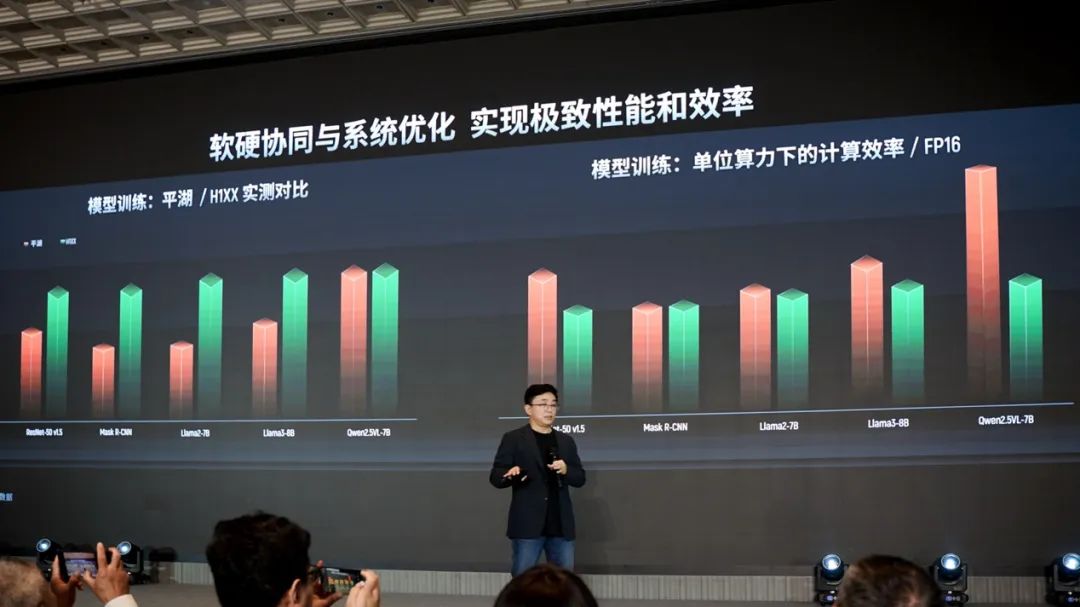
综合上述软硬层面的各种特性和优化,上面这张图给出了摩尔线程平湖架构显卡与NVIDIA Hopper架构显卡(H100)间模型训练的性能和效率对比——虽然这张图的纵轴是没有比例尺的,但大方向是为了表达主流模型训练下的表现。虽然上述所有对比,我们还是需要考虑其中暂时还没有GB200/300 NVL72的身影。
KUAE:上升到计算集群
光有芯片、板卡、节点及软件,在生成式AI、Agentic AI时代是不够的。我们常说NVIDIA的“生态优势”不只是CUDA,另一方面也表现在scale-up和scale-out规模扩展过后构建起来的大规模计算集群上,乃至今年才发布的实践AI工厂效率进一步提升的Dynamo(一个分布式推理服务库)。
就像文首提到随AI模型规模的增大,AI工厂的组建面临各种各样的问题。而摩尔线程的计算集群解决方案名为KUAE。实际上前文提到的MTLink 2.0、ACE异步通信引擎等,应该都可以算作构建KUAE集群的技术基础,但这不是全部。

KUAE集群建设需要考虑方方面面。包括“大规模分布式5D并行训练策略”,涵盖数据并行、张量并行、序列并行、专家并行、流水线并行;端到端模型训练则涉及数据处理、预训练、后训练——微调和强化训练、模型评估等;还有针对模型种类的全支持——作为AI工厂不仅要支持LLM/VLM,各类多模态生成模型、MoE模型也要支持,以及现在很流行说的世界模式(像是Cosmos),和应用到各个垂直领域的各类模型。...
此外针对模型训练的效率、性能评估,摩尔线程还推出了SIMUMAX,这也是个已经在Github上开源的软件。王华介绍说基于SIMUMAX的性能仿真工具,由于它支持各种并行与优化策略,“借助理论和仿真的结合”,针对主流大模型的训练就能“估算开销”和“大致的资源消耗”;从而尽可能找到最优解。

同时藉由软硬协同——摩尔线程能够一步步给出路线,告诉用户如何优化系统。比如图中列出的针对DeepSeek的训练,基于FP8做性能提升,再糅合recompute重算、通信、并行等各方面的优化,最终可能“逐步达到2倍以上的性能提升”。
摩尔线程给出KUAE2集群相比H100集群(主要是千卡规模),在Llama3-8b, DeepSeek-236b, Llama3-70b模型上的训练,“实测MFU(Model FLOPs Utilization)”算力利用率分别有1.12倍、1.2x倍和1.03倍的优势。相信经过极致的优化,KUAE集群今后性能可能还会有大幅度提升。

以上谈的主要都是性能、效率相关的策略与技术,“摩尔线程高效AI工厂 = 全功能GPU × MUSA架构 × MUSA软件栈 × KUAE集群 × 零中断容错技术”等式中的最后一个要素,是大规模集群训练可靠性相关的。毕竟当集群规模大了以后,整个系统的故障率或性能颠簸出现的概率就会大幅提升。
针对可靠性问题,王华谈到摩尔线程的策略分成三大块:训练检查、慢节点探测、容错训练。训练检查涵盖训练开始前对整个栈的检查(“甚至会跑一些小型负载”),发现异常节点会自动替换备机;训练过程中则包括对training hang(AI模型训练过程意外停止)、慢节点(straggler node)、loss值异常等的检查,发现问题后需要做出响应;还有“落地检查”,是在训练停止以后,找到故障点、抓取上下文,并做分析...
尤其针对慢节点会成为拖慢训练流程的整体瓶颈,在训练前、训练中都尝试“抓到慢节点”,解决后“经常会得到10%、20%的性能提升”——王华表示,还能“通过一些非监督学习的方式,将慢节点找出来”。

而“容错训练”则是基于大量节点的训练故障率指数级升高这一点,将“同步模式转为异步模式,单节点故障不影响整体训练”。上面这张PPT中的逻辑应该是对于TP Group(tensor parallel group),原本DP(data parallelism)实例出问题,需暂停训练,将出问题的DP移除,并重载chekpoint、重启流程。
而在“零中断容错方案”之下,系统检测到错误并断联对应的DP,但继续保持健康节点的运行,不需要停止训练或回退。“这批数据发不了,下一批数据再加进去。”张建中对这一机制并未做更多解释。王华则补充提到,“一个DP内的这个节点会承担一部分参数计算或更新。在此过程中将这部分参数更新跳过。这个过程丢弃了一点点数据,对整体的影响并不大,且相比停掉整个集群带来的影响和开销低得多。”所以就能达成达成ETTR>99%。
还有推理解决方案:“速度新标杆”
本场技术分享活动的主体似乎都是训练。摩尔线程最后只花了少量篇幅谈到MTT S5000达成DeepSeek“全量模型推理速度新标杆”,以及摩尔线程的推理解决方案,这里我们也简单谈一谈。虽然这实际上才是如今国产GPU和AI芯片企业征战的主场,也是Agentic AI时代价值链偏向的部分。不过或许这也一定程度表明了摩尔线程要实现全面国产替代的决心。
摩尔线程的AI推理套件主要包括MT Transformer——面向LLM的优化;TensorX——“针对CV, ViT(Vision Transformer), DiT(Diffusion Transformer)算法,能加速到极致”;以及主要考虑兼容性的vLLM-MUSA——“用户可以选择vLLM,同样能达到我们自研推理引擎最高性能的80%,让用户快速适配。”
推理工具方面,摩尔线程还提供Neuro-Trim(模型量化工具)、Torch-MUSA(加速在MUSA架构上跑基于PyTorch的AI负载,PyTorch的后端插件)、Ollama-MUSA(端侧AI推理部署工具)等。
摩尔线程特别演示了用MTT S5000做DeepSeek推理,相较DeepSeek官网——也就是基于NVIDIA的推理卡,以及采用“国内友商GPU”,在问出同一道数学题之后,MTT S5000这套方案能够以大约100 tokens/sec的推理速度输出,其他两者的速度分别在50 tks/s和15 tks/s上下。虽然这个对比还是缺一些上下文数据的,但更高的效率应当就是摩尔线程期望在AI大模型推理场景中呈现的。
其他生态和产业链建设还有诸如开设“摩尔学院”,举办线上线下的、掌握MUSA体系结构的课程;和高校合作联合开发课程、“让学生大三大四就掌握MUSA开发的核心技术”;通过教育项目推广生态……

最后值得一提的是,摩尔线程计划在今年10月份召开MUSA开发者大会——这应该是摩尔线程首次举办开发者大会。从媒体的角度来看,一家企业尝试召开开发者大会,通常意味着其生态逐步走向成熟阶段,且不再单纯以“点”的方式实现生态建设的早期突破。这从摩尔线程在本次技术分享会上展示的,从芯片到系统,再到软件与生态的综合能力,就能看得出来。
而真正具备AI工厂的落地和建设能力,在国内GPU与AI芯片市场也是不多见的;更不用说大部分市场参与者还选择完全避开NVIDIA在这一市场锋芒的做法。在业已高度成熟的桌面显卡市场有所作为,且尝试在AI工厂训推领域寻求突破,摩尔线程选择了一条相当难走的路,即便潜在AI应用仍然存在着海量市场。
既然本文以游戏开头,那么也以游戏来收尾。摩尔线程在开场时提到了《黑神话:悟空》,这款游戏的问世表明“中国的游戏开发者已经成为世界上领先的3A大作制作者,中国正从player成为creator和developer,这是市场的巨大变化”。而在AI HPC市场,提供底层算力基础和工具的摩尔线程,大概也有践行这一转变的机会。











