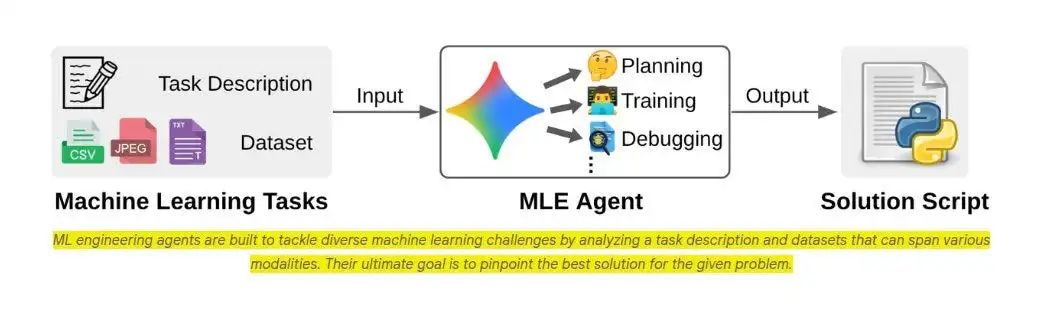
谷歌 AI 近日发布了一款名为 MLE-STAR 的机器学习工程智能体,它能够自动化处理多种复杂的人工智能任务,展现了卓越的能力。
通过巧妙融合网络搜索的广博智慧与手术刀般精准的代码微调,MLE-STAR 在 Kaggle 的 MLE-Bench-Lite 竞赛中,成功斩获了 63% 的奖牌。
它的出现,直指当前机器学习工程领域的核心痛点:工程师们不得不陷入繁琐、枯燥且无休止的手动试错循环。
相比之下,现有的许多智能体仍固守于 scikit-learn 等通用库的默认设置,遇到问题时只会全盘重写脚本,从未深入诊断并修复真正影响性能的关键模块。
核心能力揭秘
MLE-STAR 的强大之处在于其系统化的工作流程:
它首先从网络中精准捕获与任务相关的模型,然后锁定关键代码区域,进行持续迭代优化,直至性能饱和,整个过程完全无需人工干预。
在多轮尝试后,它会将效果最佳的方案融合成一个统一的解决方案,并启动内置的检查机制,主动发现并规避代码错误、数据泄露及潜在的许可证风险。
实战表现惊人
在一项涵盖 22 个 Kaggle 竞赛的严格测试中(每个竞赛均尝试 3 次),搭载了 Gemini-2.5-Pro 的 MLE-STAR 在近三分之二的挑战中成功赢得奖牌。
这一成绩是过往基准水平的三倍。即便是搭载了轻量级 Gemini-Flash 模型的版本,其表现也达到了基准水平的两倍。
告别过去的痛点
在 MLE-STAR 问世之前,构建一个高性能模型,往往意味着在海量的 Kaggle 历史项目中漫无目的地搜寻,猜测哪种特征工程技巧可能有效。
一旦某次尝试失败,工程师们又不得不推倒重来。这种低效的模式导致了模型流水线的深度不足,也极大地拖慢了创新和迭代的速度。
网络搜索:创新的起点
MLE-STAR 的工作流程始于网络搜索。它会主动寻找与当前任务匹配的高质量代码和前沿论文,为后续工作提供坚实的起点。
智能体会将每个搜索结果迅速提炼为一张简明的模型卡片,抓取核心示例代码,快速构建出第一个可执行的初始脚本。
这种从最新资源中汲取灵感的方式,使其能够跳出思维定势。例如,在处理图像任务时,它可能会选择从 EfficientNet 或 ViT 出发,而不是停留在多年前的 ResNet。
宏观架构:迭代与聚焦
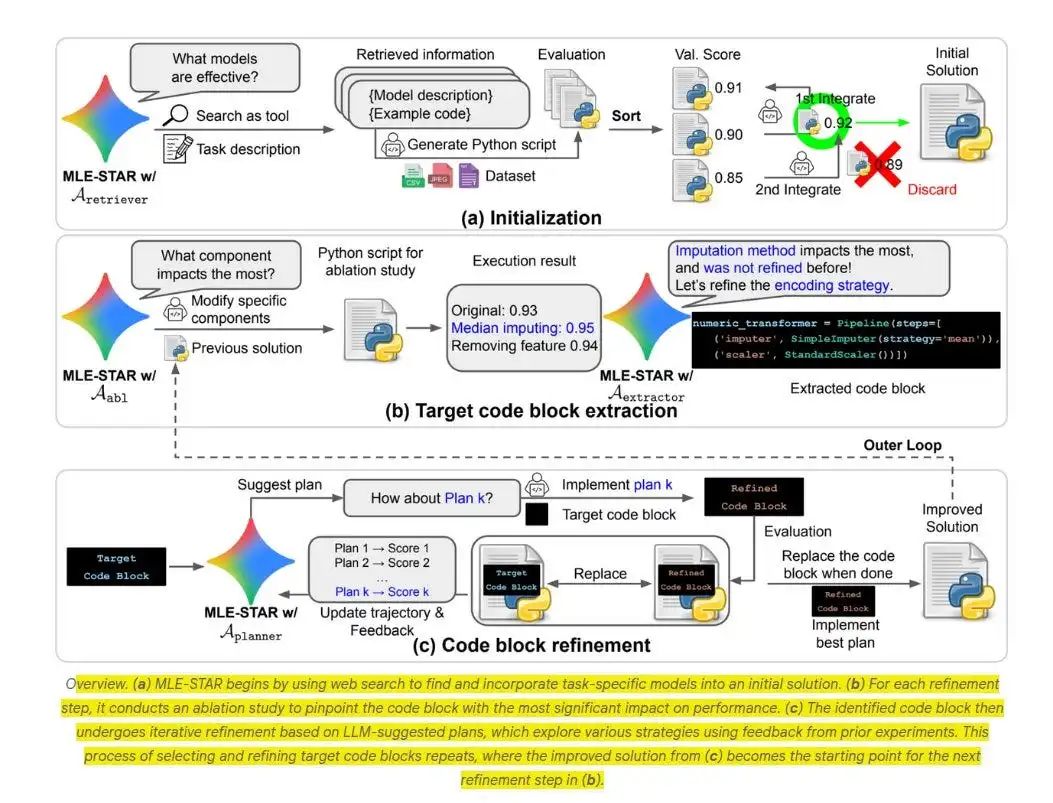
在获得首次评估分数后,智能体会立刻进行一次严谨的消融测试。它会依次关闭流水线中的各个组件,敏锐地捕捉由此引发的性能下降。
那个对模型性能影响最大的组件,将自动成为下一轮迭代的核心优化目标。
随后,大语言模型会针对这一特定代码块,生成三至五个具体的优化方案。智能体逐一测试,保留最佳方案,并以此为基础开启新一轮循环。
这种高度聚焦的策略,彻底避免了以往那种“推倒重来”的混乱与低效,确保每一次迭代都在深度挖掘潜在的性能提升空间,直至收益饱和。
更智能的模型集成
在最后的集成阶段,MLE-STAR 摒弃了简单的加权平均法,转而追求一种更为智能的策略。
它会让大语言模型设计一套精巧的集成方案,并进行实测验证。如果性能提升未达预期,方案将被果断否决并重写。
经过数轮「提出-评估-优化」的闭环迭代,多个原本独立的模型脚本,最终会收敛为一个性能卓越的混合模型,其效果通常能超越任何一个单一的候选模型。

参考资料:https://research.google/blog/mle-star-a-state-of-the-art-machine-learning-engineering-agents/
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!