
全文约 2000 字,预计阅读时间 6 分钟
如何在保证响应速度的同时,大幅提升大模型服务的效率?这篇论文给出了惊艳答案。
随着大语言模型(LLM)在聊天机器人、代码生成、文档分析等领域的广泛应用,其高昂的推理成本已成为服务提供商的巨大负担。如何在满足用户对响应速度(如首字延迟)和生成流畅度(如每字延迟)双重体验要求的前提下,最大化系统能处理的请求数量(即好吞吐量(goodput)),是当前LLM 服务系统的核心挑战。
长久以来,业界围绕预填充-解码分离(PD Disaggregation)与聚合(PD Aggregation)两种架构争论不休。前者通过物理隔离两个阶段来减少干扰,提升生成速度;后者则通过共享资源来提高利用率,优化响应速度。然而,这两种“非此即彼”的方案都存在明显短板。这篇论文没有选择站队,而是提出了一个颠覆性的统一方案——TaiChi,成功将好吞吐量提升了最高 77%。

核心看点

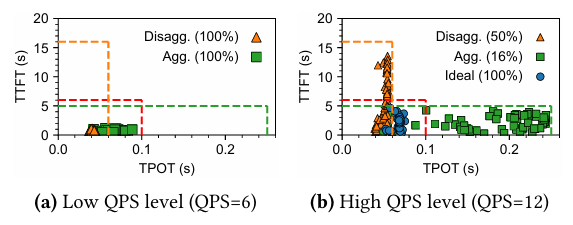
本文的核心亮点在于,它没有固守传统的技术路线,而是通过深入分析发现:PD 聚合在首字延迟(TTFT)要求严格时表现最佳,而PD 分离在每字延迟(TPOT)要求严格时更胜一筹。然而,当用户对两者都有均衡要求时,现有方案均会顾此失彼。
基于此洞察,研究团队提出了TaiChi系统,它创造性地统一了聚合与分离架构。其关键创新是“延迟迁移”(latency shifting)——通过智能调度,将那些远超服务等级协议(SLO)的请求所“浪费”的资源,动态地转移到那些即将违反 SLO 的“濒危”请求上。这就像在交通高峰期,为急救车动态开辟绿色通道,从而最大化整体通行效率。
TaiChi已成功集成于开源项目 vLLM,并计划开源,为整个 LLM 服务领域提供了一个全新的、可落地的高性能解决方案。
研究背景
传统的 LLM 推理分为两个阶段:预填充(Prefill)阶段需要一次性处理用户输入的全部提示词,计算密集,决定了首字延迟(TTFT);解码(Decode)阶段则逐个生成输出 token,内存密集,决定了每字延迟(TPOT)。一个理想的系统需要同时优化这两个指标。
现有的PD 聚合方案(如 Orca、Sarathi-Serve)将两个阶段放在同一 GPU 实例上,虽然资源利用率高,但长提示词的预填充会严重干扰正在进行的解码任务,导致 TPOT 急剧上升。相反,PD 分离方案(如 Splitwise、DistServe)将预填充和解码分别部署在专用实例上,消除了干扰,但用于预填充的实例数量有限,导致在高负载下预填充队列积压,TTFT 大幅增加。
这导致了一个根本性的困境:现有方法在平衡的 SLO(即 TTFT 和 TPOT 都要求严格)下表现糟糕。例如,在实验中,当 SLO 设定为 6 秒 TTFT 和 100 毫秒 TPOT 时,PD 聚合和 PD 分离的 SLO 满足率分别仅为 16%和 50%。这表明,单纯优化一个指标会牺牲另一个,无法实现整体好吞吐量的最大化。
核心贡献
方法创新:混合模式推理与差异化实例
TaiChi的核心是构建了一个统一的聚合-分离架构。它将 GPU 实例分为两种类型:预填充重实例(P-heavy)和解码重实例(D-heavy)。P-heavy 实例配置大 chunk size,擅长快速处理预填充,但解码时干扰严重;D-heavy 实例配置小 chunk size,解码干扰极低,但预填充速度较慢。
系统通过三个可配置的“滑块”(Sliders)进行调控:P/D 实例比例、P-heavy 的 chunk size、D-heavy 的 chunk size。这使得系统能灵活适应不同场景:当 TTFT 是瓶颈时,可调为类似聚合的模式;当 TPOT 是瓶颈时,可调为类似分离的模式;而在平衡 SLO 下,则启用其独创的混合模式推理(Hybrid-Mode Inference)。
在这种模式下,单个请求的预填充和解码阶段可以运行在不同类型的实例上,实现了前所未有的调度灵活性。例如,一个长提示词请求的预填充可以放在 P-heavy 实例上以保证 TTFT,而其解码则被“流”到 D-heavy 实例上以保证 TPOT。
理论突破:实现请求级的精细延迟控制
在混合模式的基础上,团队提出了两大核心调度机制,实现了请求级的延迟迁移。

首先是流动解码调度(Flowing Decode Scheduling),用于控制 TPOT。所有解码请求初始都在低干扰的 D-heavy 实例上运行。当 D-heavy 实例内存接近饱和时,系统会将当前输出长度最长的请求迁移到高干扰的 P-heavy 实例上,从而“降级”其 TPOT,为新请求腾出资源。这巧妙地解决了“输出长度未知”的难题——长输出请求有更大的延迟预算来吸收性能降级。一旦被降级的请求 TPOT 接近 SLO 阈值,它又会被“流回”D-heavy 实例。
其次是长度感知预填充调度(Length-Aware Prefill Scheduling),用于控制 TTFT。系统会预测每个预填充请求在不同实例上的总延迟(排队+执行+传输)。对于短提示词请求,即使将其分配到较慢的 D-heavy 实例也能满足 TTFT,系统就会主动“降级”它,从而将快速的 P-heavy 实例留给更紧急的长提示词请求。

实证成果:性能飞跃

实验在 Qwen2.5 系列模型上进行,结果令人瞩目。在平衡 SLO 下,TaiChi相比PD 聚合将好吞吐量提升了9%至 47% ,相比PD 分离提升了29%至 77% 。
更具体地,在摘要生成任务中,对于 14B 和 32B 模型,TaiChi 在 SLO2 下的好吞吐量分别比 PD 分离高出77%和74% 。同时,其尾部延迟也显著降低:相比 PD 分离,TTFT 降低了 2.42 至 13.20 倍;相比 PD 聚合,TPOT 降低了 1.11 至 1.69 倍。这直接证明了其“延迟迁移”策略的有效性。
行业意义
TaiChi的研究成果,为LLM 服务技术路线指明了一个新的方向:从“二选一”的对抗走向“聚合与分离”的统一。这种方法论的转变,有望成为下一代 LLM 推理引擎的标准范式。
其设计思想与国家倡导的降本增效和绿色计算政策高度契合。通过最大化硬件资源利用率,TaiChi 能显著降低单位请求的能耗和碳排放,推动 AI 产业向可持续发展迈进。
更重要的是,这种精细化的资源调度能力,可能引发产业变革。它使得服务提供商能够以更低的成本,为用户提供更高质量、更稳定的服务体验。无论是需要快速响应的客服机器人,还是要求流畅生成的创作工具,都将从中受益。TaiChi不仅是一项技术突破,更是推动整个大模型应用生态升级的关键力量。
论文链接:https://arxiv.org/abs/2508.01989
-- 完 --
机智流推荐阅读:
1. LLM思维链是海市蜃楼? R-Zero零数据自进化,DeepPHY物理推理,Qwen-Image,HF本周TOP20论文速览!
2. 仅一行代码即可极大优化SFT泛化能力!东南大学等顶尖高校揭示SFT泛化能力差的根本原因,并提出高效改进方案
3. 还在手写CUDA?上交KernelPilot用AI帮你写又快又好的CUDA!
4. 一张截图就能生成前端页面?MMLab实验室推出SCREENCODER大模型 | 开源
关注机智流并加入 AI 技术交流群,不仅能和来自大厂名校的 AI 开发者、爱好者一起进行技术交流,同时还有HuggingFace每日精选论文与顶会论文解读、Talk分享、通俗易懂的Agent知识与项目、前沿AI科技资讯、大模型实战教学活动等。
cc | 大模型技术交流群 hf | HuggingFace 高赞论文分享群 具身 | 具身智能交流群 硬件 | AI 硬件交流群 智能体 | Agent 技术交流群








