编辑:严浠
目前,视觉-语言-动作(Vision-Language-Action, VLA)模型取得了显著进展。大多数VLA模型是以VLM模型为基础,在大规模具身交互数据上进行训练,从而提升在机器人操作任务中的泛化性。
但这些VLA模型仅使用机器人数据微调会面临着“灾难性遗忘”问题,即原本继承自预训练VLM的多模态推理能力逐渐衰退。但这并不是一种知识性丧失,而是临时的遗忘,也被称为“虚假遗忘”。为减轻这种灾难性遗忘,先前工作主要有两种策略:
第一种是联合训练方式,在保留通用多模态能力的同时学习操作技能,如ChatVLA和Magma。这种方式通过联合视觉语言数据与机器人操作数据进行训练,但往往忽视了具身推理的复杂性。
第二种侧重于将具身推理整合到操作数据集中,以迁移VLM能力,例如ECoT和Emma-X将思维链推理嵌入到操作数据集中。但这种方法通常依赖于预训练的动作模型并嵌入固定的推理模板,限制了模型的多模态泛化能力。
为解决上述问题,中国科学技术大学联合浙江大学和上海AI Lab提出通用端到端VLA模型InstructVLA。

该模型基于预训练VLM,在保持强大的多模态理解能力的同时,还能够精确的动作生成。InstructVLA采用了一种新颖的训练范式,将语言驱动的动作生成视为指令遵循的一部分,来弥合视觉语言理解与动作生成之间的鸿沟;并围绕这一目标构建了VLA-IT数据集。该数据集包含约65万条人机交互数据,标注了多样化的指令、场景描述以及基于高质量操作任务的问答对。训练过程分为两阶段:动作预训练和视觉-语言-动作指令微调。
实验表明,InstructVLA在SimplerEnv-Instruct基准上优于微调版OpenVLA 92%,也超过了由GPT-4o辅助的动作专家29%。InstructVLA在多模态任务上还超越了同等规模的VLM模型,在闭环操作上较Magma提升了27%。

论文标题:《Vision-Language-Action Instruction Tuning: From Understanding to Manipulation》
论文链接:https://arxiv.org/abs/2507.17520
项目主页:
https://yangs03.github.io/InstructVLA_Home/
1
方法
1.1 模型架构
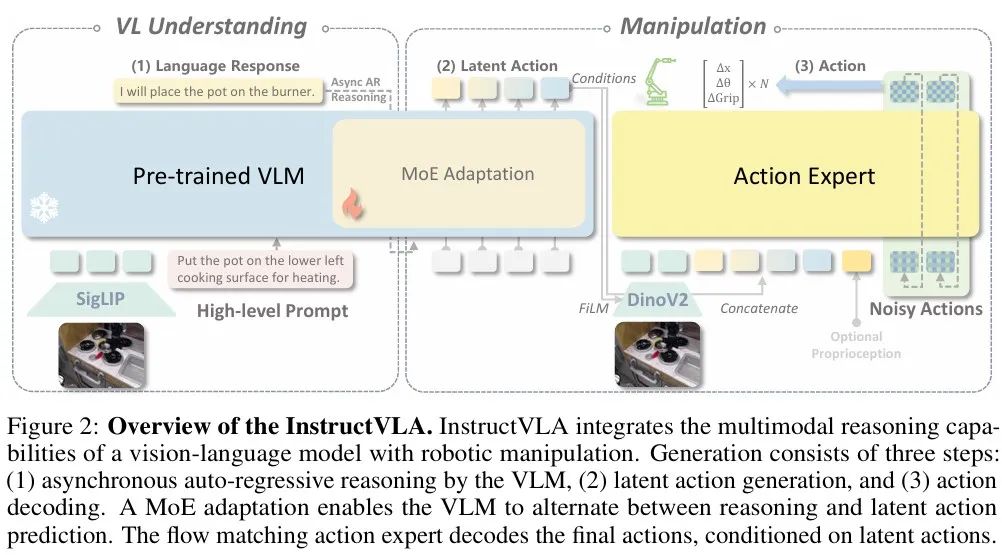
InstructVLA模型将视觉语言模型(VLM)的多模态推理能力与机器人操作能力相结合。该模型首先输出文本,用以保持预训练 VLM 的语言理解与多模态推理能力,随后生成潜在动作向量,用于下游的操作任务,过程包含以下三个步骤:
(1) 异步自回归推理(Asynchronous auto-regressive reasoning):由 VLM 执行;
(2) 潜在动作生成(Latent action generation);
(3) 动作解码(Action decoding)。
研究人员采用专家混合机制( MoE),VLM能够在推理与潜在动作预测之间动态切换。为了进一步解耦高层理解与低层控制,最终动作由流匹配动作专家进行解码,该解码过程以生成的潜在动作为条件。
1.2 两阶段训练方案
第一阶段:动作预训练
InstructVLA使用异构的操作数据集Bridge data和Rt-1进行预训练。模型能够同时输出机器人动作指令和基于规则标注的语言化运动描述两类预测结果。其中,语言化运动描述通过交叉熵损失进行监督,最终的损失函数是语言损失与flow matching损失之和。
在该阶段,仅对动作查询的输入/输出嵌入和LLM中的动作LoRA适配器进行微调,约6.5亿参数。该阶段训练后的模型被称为 “专家模型”(Expert)。
第二阶段:视觉-语言-动作指令微调
这一阶段基于视觉指令微调的思路,采用一种简洁高效的训练策略。当动作专家模型学会遵循VLM生成的潜在动作后,进一步调整LLM主干参数,能够显著提升模型处理复杂指令的能力并生成精准合理的响应。
本阶段使用的数据将VLM预训练能力与具身任务结合,并融合多个多模态数据集联合训练,最终得到的模型被称为 “通用型模型”(Generalist),即深度融合了视觉语言理解与机器人操作能力的模型。
1.3 VLA数据集与评测基准
InstructVLA微调数据集
研究人员从大规模操作数据集Bridge data和Rt-1中构建了多样化的层级式语言标注,涵盖用于预训练的语言运动和基于规则的标签,以及用于指令微调和推理迁移的VLA-IT(视觉-语言-动作指令微调)数据集。VLA-IT数据集包括65万条人机交互数据,并结合操作轨迹与语言动作进行标注。
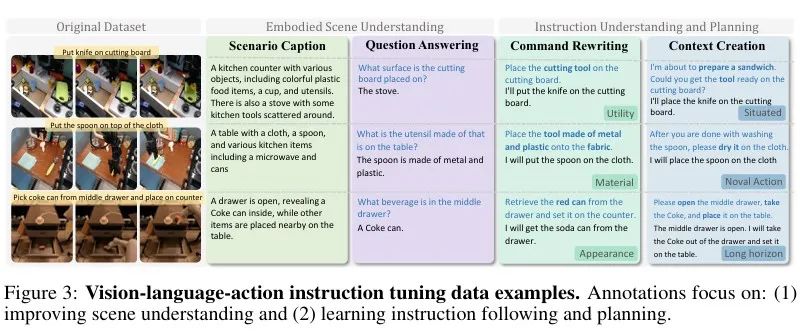
研究人员使用 GPT-4o为每个任务片段中的三帧图像及对应指令进行数据标注。但在具身任务中,使用GPT-4o会导致性能gap。
SimplerEnv-Instruct 评测基准
基于SimplerEnv平台,研究人开发了SimplerEnv-Instruct 评测基准,用于评估VLA模型在零样本环境下的指令遵循与推理能力,覆盖动词扩展、指令重构、多语言表达及任务推理等共1100项挑战任务。该评估遵循“技能可迁移性”与“人类可解释性”两大原则,确保任务既具挑战性又贴近真实的人机协作场景。

2
实验
2.1 主要结果
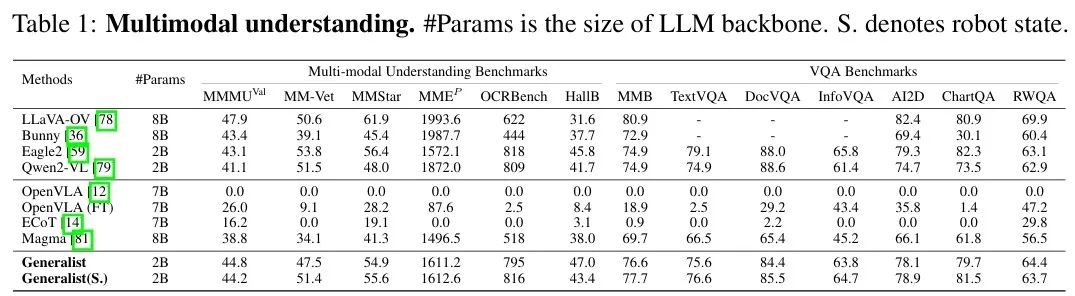
在多模态基准测试中,InstructVLA展现出了显著的性能优势,其通用模型在多个多模态任务中全面超越现有主流VLM(如 Bunny、Eagle2),并在 MMMU、MMB、RWQA 等基准上表现领先。实验结果如下表所示。
在机器人操作任务的实验结果如下表所示。InstructVLA专家模型比基线SpatialVLA高出30.5%,其通用模型在SimplerEnv-Instruct上比SOTA基线(OpenVLA + GPT-4o)高出29.5%。

值得注意的是,即便通过集成GPT-4o作为基于API的System-2模块来改写指令(OpenVLA(FT&GPT))可以提升性能,但仍无法超越InstructVLA (通用模型)。
2.2 真实世界实验
为了评估InstructVLA在真实场景的表现,进行了零样本实验和少样本实验,将InstructVLA与OpenVLA进行对比。
在厨房场景中,将模型部署到WidowX-250机械臂上进行零样本推理实验。InstructVLA的成功率比OpenVLA高出46.7%。
少样本推理实验是在Franka Research 3机器人上进行的,包括从货架中进行抓取放置任务和整理杂乱桌面任务。InstructVLA在少样本实验中成功率比OpenVLA高出41.7%。

3
总结
本论文提出了一个通用端到端VLA模型InstructVLA。该模型基于预训练VLM,在保持强大的多模态理解能力的同时,将机器人操作纳入指令跟随体系。构建了包括65万条标注的VLA-IT数据集与一个用于评估VLA模型的指令泛化能力的评测基准SimplerEnv-Instruct 。该模型通过保留预训练VLM的泛化能力;并将语言、感知与控制整合为一个协调的流程,有效解决了VLA模型中常见的灾难性遗忘问题与推理脱节现象。InstructVLA在多模态基准测试、机器人操作任务和真机实验中性能均达到领先水平。
END
推荐阅读
20亿参数+全面超越π0!清华朱军团队&地平线提出全新VLA模型H-RDT,有效从人类操作数据中学习
机器人非抓取操作重大突破!北大&银河通用王鹤团队提出自适应世界动作模型DyWA | ICCV 2025
清华联合生数提出具身视频基座模型Vidar,20分钟真机数据实现跨本体泛化!
星海图联合创始人赵行:定义具身智能的ImageNet | 演讲回顾
RSS 2025最佳Demo奖!UC伯克利联合谷歌开源机器人强化学习框架MuJoCo Playground
点击下方名片 即刻关注我们