编辑:严浠
目前,VLA模型已取得显著进展,成为机器人操作领域的关键范式,旨在赋予机器人自主感知、推理及在真实世界中执行复杂任务的能力。但大规模、高质量、开放世界的机器人数据的稀缺仍是重大瓶颈。现有数据集,如Open-X Embodiment,主要存在任务真实性不足和场景不够丰富的问题,造成了基于此训练的模型在面对复杂真实世界中的任务泛化性不足。
为此,星海图团队构建了全球首个开放场景高质量真机数据集(Galaxea Open-World Dataset)。该数据集包含了机器人在真实人类工作和生活场景中系统采集的500个小时的高保真数据,涵盖了50个不同场景下的150余项任务;并且所有数据均使用单一的机器人本体持续采集,确保了数据的统一性和可靠性。
基于此数据集,该团队又发布了端到端双系统全身智能VLA模型——星海图G0。G0模型采用快慢双系统架构,利用系统2(G0-VLM)进行通用多模态规划,系统1(G0-VLA)实现精准的动作执行。两个系统以不同频率异步运行,既支持高效训练,也支持实际部署,实现了从视觉和语言指令到23自由度全身控制的长程任务执行。
G0模型评测结果全面优于π0。Galaxea Open-World Dataset 数据集也即将全面开源。

论文标题:《Galaxea Open-World Dataset and G0 Dual-System VLA Model》
项目主页:https://opengalaxea.github.io/G0/
1
数据集
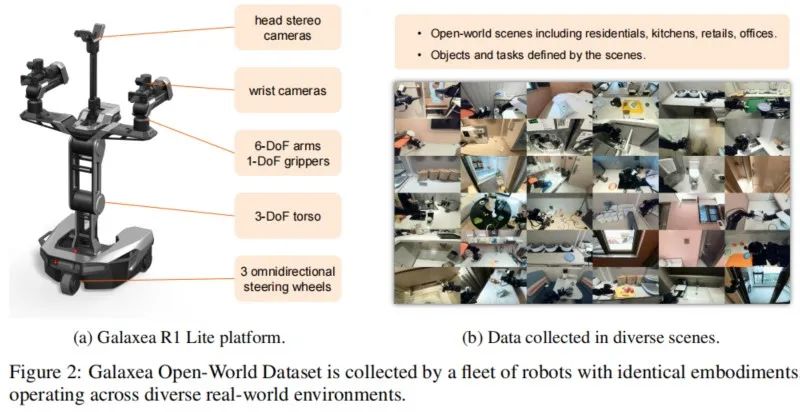
星海图开放场景高质量真机数据集(Galaxea Open-World Dataset)是一个大规模、高质量、全标注的数据集。它包含100,000条演示轨迹,涵盖了在50个真实场景中执行的150个任务类别。这些演示覆盖了超过1,600个独特物体和从精细的分拣放置到协调的全身操作的58种操作技能。所有数据均采用统一的机器人平台星海图 R1 Lite采集,整个数据集中的感知、动作和语言标注完全对齐。硬件配置正装双6自由度机械臂、3自由度躯干、可全向移动的底盘,以及多视角RGB-D摄像头。
为确保动作自然可行,该团队采用了同构遥操作方案,将操作者的动作直接映射到机器人上。与VR遥操作相比,该方法能保证手臂动作的可行性,并无需在人体与机器人形态之间进行动作重定向。
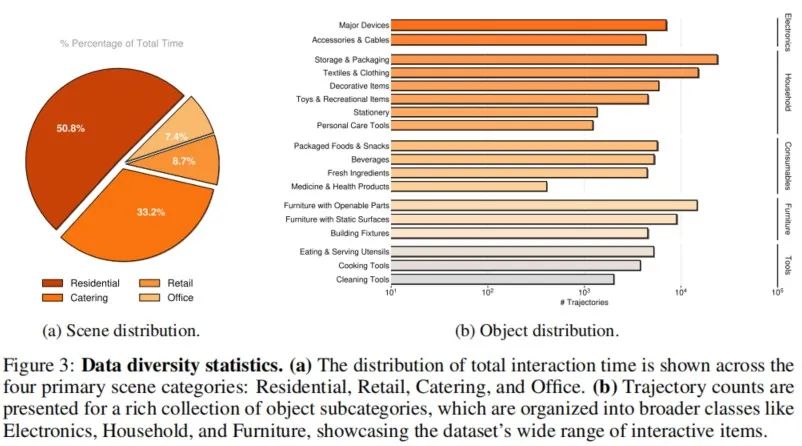
环境与物体多样性: 数据集在11个真实场地采集,包括住宅、餐饮、零售和办公空间。每个场地提供多个操作区域,共50个场景。对于不安全或不便反复操作的物品(如食品),则使用高保真复制品。
标注流程:对每个任务进行了子任务级语言标注,即将一个完整任务分解为多个具有明确语义的步骤,并精确对齐对应的感知与执行数据。这种细粒度标注不仅支持动作级别的监督学习,还为训练高层任务规划模块提供了可直接利用的序列化知识。这种标注方式不仅定义了人类与机器人之间的交互界面,还能将长程任务拆解为更易执行的小任务,从而帮助机器人更高效地完成目标。

与其他数据集对比:将该数据集与其他大规模机器人数据集对比,包括BridgeData、RT-1、Open-X-Embodiment和AgiBot World。Galaxea Open-World Dataset在场景真实性、任务多样性和动作复杂度上均有显著优势。
2
方法
2.1 G0双系统概述
G0双系统由系统 1(System-1)和系统 2(System-2)组成。
System-1是快速响应系统,是一个端到端的VLA模型G0-VLA 。它负责感知环境、解析子任务指令并执行动作,用于控制双臂机器人。
System-2是慢思考系统,是一个视觉语言模型G0-VLM。它能够处理高级自然语言任务指令,理解场景,并为System-1规划子任务指令。

2.2 训练范式
针对这两个模型采用了不同的训练方案:
G0-VLA模型采用三阶段训练策略,利用不同的数据集逐步提升其性能和适应性。
G0-VLA预训练阶段1:仅训练VLM组件,为了使VLM的语言模型主干能够预测机器人动作,采用FAST tokenizer 作为动作分词器,它将原始的连续动作组转换成一串离散索引序列。该阶段旨在从广泛的机器人数据中获取一个通用先验模型。
该阶段使用的数据混合了多种机器人数据,包括约1,000小时的Open-X Embodiment (OXE) 轨迹数据,500小时Galaxea Open-World Dataset(无标注),以及200小时内部数据。
G0-VLA预训练阶段2:该阶段在标注好的Galaxea Open-World Dataset上训练。G0-VLA由预训练好的VLM和一个动作专家组成。动作专家基于本体感知状态和VLM生成的表征来生成连续的动作。
微调阶段:使用少量高质量的演示数据对模型进行微调,以掌握特定的复杂任务技能。为了测试预训练模型的泛化能力,使用不同的预训练权重,在下游任务上使用少量高质量的演示数据对VLA进行微调,以掌握特定的复杂任务技能。对于每个任务,将微调数据限制在最多100条轨迹。

G0-VLM训练:
G0-VLM是双系统的高层规划器,其作用包括:解析人类的高级指令、用语言进行回应、执行任务规划、以及向G0-VLA发送低级原子动作指令以供执行。该基于开源的Qwen2.5-VL,并使用从Galaxea Open-World Dataset中采样的数据进行指令微调。G0-VLM使用从Galaxea Open-World Dataset中提取的图像和子任务标注对进行训练。
3
G0-VLA 评估
该团队构建了具有挑战性的基准测试集,并进行了微调实验,用来评估G0-VLA模型的性能以及所提出数据集的有效性。探究的核心问题是预训练数据如何影响VLA模型? 从以下三个角度展开探讨:
预训练是否能提升下游任务微调性能?预训练权重的重要性;
在单一机器人平台上的预训练能否加速少样本迁移?
在机器人特定的动作方面,单机器人预训练与跨机器人本体预训练效果相比如何?
基准测试包含桌面整理(Table bussing)、用微波炉加热食物(Microwave operation)、铺床(Bed Making)、用积木堆叠出特定单词(Blocks Stacking)这4个任务,这些任务涵盖了精确抓放、双臂协同操作、设备操作、全身运动控制以及语言指令跟随等多种能力。采用进度评分来评估这些任务。每个测试均进行10次,取各个任务的平均分。
3.1 预训练权重
在本实验中,测试了不同预训练权重的有效性。在所提出的基准测试上对以下预训练模型进行微调,每个任务使用100条训练轨迹,共进行4轮训练。
• G0(Stage-1): 仅经过阶段1预训练的VLA模型。
• G0(Stage-2 200h): 仅经过第2阶段预训练的VLA ,使用200h数据。
• G0(Stage-2 400h): 仅经过第2阶段预训练的VLA ,使用400h数据。
• G0(Full):经过阶段1和阶段2预训练的VLA模型,阶段2使用400h数据。
• G0(Scratch):未经任何动作预训练的VLA模型,从原始VLM权重初始化。
• π0:作为Benchmark。

实验结果如上图所示,G0(Full)模型表现最佳,特别是在桌面整理、微波炉操作和铺床任务中,展现了卓越的物体抓取能力,全面超越了模型π0。G0(Scratch)表现最差,证明了预训练的有效性。
通过观察可得,预训练阶段1主要增强了VLA执行简单动作的能力,如抓取放置和推拉;而预训练阶段2则将模型适配到机器人平台上,提升了动作稳定性和指令遵循能力。
3.2 少样本迁移实验
实验结果如下图所示,单机器人本体预训练可显著提升适应性,仅用20条轨迹即可在新任务中实现平稳、连贯的执行。实验结果表明,跨本体预训练效果显著低于单本体预训练,VLA模型的能力与本体高度相关。

3.3 本体构型特定动作
该团队对本体构型特定动作进行深入分析。铺床是一个长时序任务,需要频繁、协调且精确的全身控制,包括底盘、躯干和双臂。这些都是跨本体数据集中未体现的特定行为。
实验结果表明,仅经过跨本体预训练的G0(Stage-1)模型,由于与目标平台存在较大的构型差异,在这些技能上表现较弱,甚至有时不如从零训练的模型。这说明跨本体数据并不能替代单本体数据在学习构型特定动作上的价值。

4
G0-VLM 评估
在双系统框架中,G0-VLM是任务规划器,它负责处理人类指令并观察周围环境,为G0-VLA模块生成可执行指令。该团队着重探究以下两个关键问题:
与直接使用预训练模型相比,微调是否必要?
监督微调(SFT) 如何提升VLM在机器人任务中的性能,特别是如何提高动作的准确性?
该团队将微调后G0-VLM模型与Gemini-2.5-pro、Qwen2.5-VL各个版本的模型进行对比,实验结果如下表所示。经任务特定指令微调后的G0-VLM指令准确性显著超过其他VLM模型,证明了微调的有效性。

5
总结
星海图团队构建了一个大规模、高保真且带标注的开放场景高质量真机数据集(Galaxea Open-World Dataset)。基于此数据集进行预训练,提出了由G0-VLM和G0-VLA共同构成的双系统框架G0。G0模型在一系列多样化的测试中均达到了SOTA性能。
END
推荐阅读
20亿参数+全面超越π0!清华朱军团队&地平线提出全新VLA模型H-RDT,有效从人类操作数据中学习
机器人非抓取操作重大突破!北大&银河通用王鹤团队提出自适应世界动作模型DyWA | ICCV 2025
清华联合生数提出具身视频基座模型Vidar,20分钟真机数据实现跨本体泛化!
星海图联合创始人赵行:定义具身智能的ImageNet | 演讲回顾
RSS 2025最佳Demo奖!UC伯克利联合谷歌开源机器人强化学习框架MuJoCo Playground
点击下方名片 即刻关注我们










