编辑丨具身智能之心
本文只做学术分享,如有侵权,联系删文
更多干货,欢迎加入国内首个具身智能全栈学习社区:具身智能之心知识星球(戳我),这里包含所有你想要的。
写在前面
具身智能目前已经成为人工智能研究的前沿领域。随着机器人技术的快速发展,如何让机器人更好地理解和执行复杂任务成为了一个重要的研究方向。扩散策略(Diffusion Policy)发挥了扩散模型(Diffusion models)对复杂分布的拟合能力,成为了构建视觉-语言-动作(VLA)模型的主流范式。然而,现有的扩散策略在训练效率上仍然存在不足。本文发现了扩散策略训练低效的一个关键挑战:当扩散模型神经网络难以区分生成条件——即视觉输入和语言指令时,训练目标会发生退化,变成对边际动作分布的建模,该现象被称为损失崩塌(loss collapse)。为了解决损失崩塌的问题,可以简单地将动作生成的源分布(source distribution)修改为依赖于生成条件的分布(Condition-conditioned source distribution),简称为Cocos。本文提供了理论证明和广泛的实证结果,涵盖了模拟和现实世界基准测试。通过Cocos进行扩散策略训练实现了更快的收敛速度和更高的成功率。Cocos只需要修改源分布,非常轻量且易于实现,与各类扩散策略架构兼容,为扩散策略训练提供了一种通用改进。

论文链接:https://arxiv.org/pdf/2505.11123 代码链接:https://github.com/ZibinDong/cocos
问题背景与条件分布的流匹配
流匹配方法 (Flow Matching)是扩散模型的核心方法之一,能够涵盖 Value Exploding, Value Preserving扩散模型,流匹配模型,Rectified Flow等多种模型。以此作为本文的框架基础。流匹配方法通过求解常微分方程(ODE) 将一个简单的源分布 (source distribution)转化为一个复杂的目标分布 (target distribution)。速度场 可以通过神经网络 优化以下目标来近似:
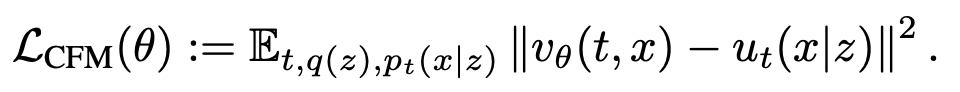
对于扩散策略而言,需要拟合的分布是一个条件分布 ,其中 是动作, 是条件(如视觉输入和语言指令)。可以通过类似的方式证明条件分布流匹配的一种优化目标:

这种优化目标是目前VLA模型中最常用的流匹配目标,可以解释为对数据集同时采样,即(动作,视觉输入,语言指令),再对源分布单独采样 ,然后计算优化目标。
损失崩塌与Cocos
本文发现这一种优化目标在训练过程中很容易发生损失崩塌(loss collapse)现象,即当神经网络难以区分生成条件时,优化目标会退化为对边际动作分布的建模。具体而言,假设有一个难以区分的条件集合,对于该集合中任意两个条件 和 ,如果神经网络难以区分 ,那么对应的优化目标的梯度距离就会被限制在一个很小的范围内,范围上界随着区分的差异一并减小,导致梯度差异消失,收敛到这些难以区分条件上的平均分布。


图1. 损失崩塌现象的示意图。当发生损失崩塌后,扩散策略的训练目标会退化为对边际动作分布的建模,放弃区分生成条件。
损失崩塌问题本质上源于源分布从无关条件的分布 上采样,将源分布替换为依赖于生成条件的分布 (Cocos),可以有效解决损失崩塌问题。

为了在实验中验证损失崩塌现象与Cocos的有效性,需要设计一个扩散策略进行实验。本文使用与先进VLA模型RDT(Robot Diffusion Transformer)相同扩散策略架构——在DiT(Diffusion Transformer)基础上插入一个交叉注意力层(cross-attention layer)交替融入视觉输入和语言指令信息,视觉输入使用Dinov2编码,语言指令使用T5编码。 使用最常用的标准高斯分布, 使用一个固定标准差的高斯分布,均值为条件 的自动编码器隐空间特征,标准差为固定值。(的具体形式可以合理地任意设计,并不限制于本文使用的这一种,由于并不是本文的重点,因此不进一步探究)

图2. 实验中使用的扩散策略架构与Cocos的源分布设计。
Cocos能够解决损失崩塌问题提高训练效率与策略性能

图3. Cocos解决损失崩塌示意图。
为了测试神经网络对生成条件的区分能力,我们对比了生成条件特征融入神经网络前后,网络隐藏状态的模长变化与余弦相似度,越大的模长变化和越小的余弦相似度表明神经网络对生成条件的区分能力越强。在LIBERO benchmark的实验中表明,使用Cocos训练的网络对生成条件的区分能力明显更强,并且模型的训练效率和策略性能也相应地更好。
下面的图表中展示了定量实验结果,包括LIBERO和MetaWorld两个仿真benchmark,以及现实世界的xArm和SO100两种机械臂上的操作任务测试。可以看到,Cocos在所有任务上都显著提高了训练效率和策略性能。

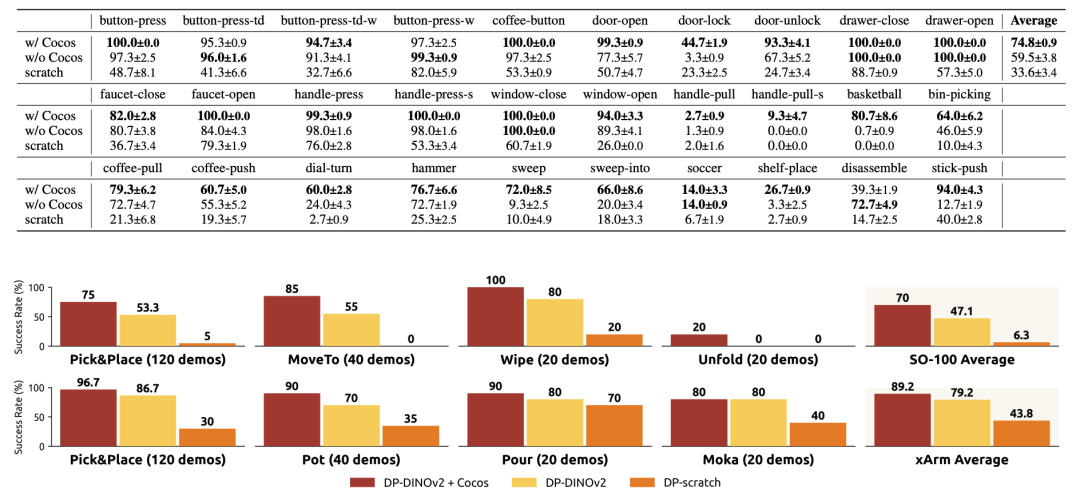
图4. 定量实验结果。

图5. 真机实验,包括xArm和SO100两种机械臂上的操作任务测试。
案例研究
本文在仿真中进行了案例研究,展示了Cocos在实际应用中的效果。 下方图一展示了LIBERO benchmark中的一个案例,该任务要求机械臂将盘子向前移动,向右移动,再回推到电炉前方。第一行的图例展示了Cocos训练策略的成功案例。第二行图例展示了没有使用Cocos策略的失败案例,外部相机被崩塌,策略仅关注到腕部相机,当腕部相机意外脱手无法看到盘子的时候(虽然外部相机能看到),策略无法定位盘子的位置,向错误的方向寻找盘子,导致任务失败。第三行图例展示了没有使用Cocos策略的成功案例,外部相机被崩塌,策略仅关注到腕部相机,虽然机械臂意外脱离盘子,但因为腕部相机仍然能看到盘子,策略仍然能定位盘子的位置,任务成功完成。第四行图例展示了没有使用Cocos策略的成功案例,外部相机被崩塌,策略仅关注到腕部相机,忽略了外部相机中电磁炉的位置,导致机械臂不知道在何处回推,任务失败。最下方的表格中也通过余弦相似度对比了Cocos与非Cocos策略对不同视角相机的分辨能力,尽管对腕部相机的区分能力都要高于外部相机,但Cocos策略对所有视角相机的区分能力都明显高于非Cocos策略。

图6. 案例研究:LIBERO benchmark中的一个任务案例。
源分布设计实验
在本文的实验中默认使用固定标准差的高斯分布作为源分布 ,其标准差被设定为0.2,该实验对比了标准差为0.1和0.4时的策略效果,对比了使用VAE训练源分布的效果(相当于自动学习标准差),以及源分布和扩散策略同时训练的效果,如下:

图7. 源分布设计实验结果。
可以发现过于小的标准差可能导致性能下降,标准差为0.2和0.4时效果接近。使用VAE训练源分布能够自动学习合适的标准差,与手动设计的0.2标准差效果相当。先训练源分布再训练扩散模型对于一些大型数据集任务可能导致繁重的计算负担,源分布和扩散策略同时训练会导致训练不稳定,如果给源分布增设一个EMA更新机制,则可以稳定训练过程,实验中发现这种训练方式和分阶段训练源分布的效果相当。
总结
Cocos通过将源分布设计为依赖于生成条件的分布,有效地解决了扩散策略训练中的损失崩塌问题。实验结果表明,Cocos能够显著提高训练效率和策略性能,并且与现有的扩散策略架构兼容,易于实现。Cocos为扩散策略训练提供了一种通用改进,为未来的研究和应用奠定了基础。