
V3.1 将早前的 V3 聊天模型和 R1 推理模型整合为一个能够以两种模式运行的系统。DeepSeek-V3.1 允许用户在两种模式间切换。
快速摘要
DeepSeek 发布了 V3.1,一个可以在快速聊天和深度推理之间切换的混合模型。
性能略有提升,成本保持极低,且思考过程消耗的 Token 更少。
DeepSeek 的策略正转向 Anthropic 的混合模式。
思考模式 (deepseek-reasoner) 专为多步推理和工具使用 (Tool Use) 进行调优,而非思考模式 (deepseek-chat) 则为较简单的任务设计。
两种模式均支持 128,000 Token 的上下文窗口。非思考模式同样支持工具使用。
模式的选择通过提示词中一个特殊的闭合思考标签,或通过应用内的开关来决定。官方的模型卡片精确地展示了切换机制:非思考模式的提示词以前缀 </think> 开头,立即关闭思考标签;而思考模式的提示词则以 <think> 开头。因此,同一个模型会根据前缀的不同而表现出不同的行为。
两种模式共享一个 128,000 Token 的上下文窗口,因此长输入在两种模式下的处理方式是相同的。 推理模式针对多步问题,而非推理模式则为常规任务保持了高速率和低成本。
该模型还增加了对 UE8M0 FP8 的支持,旨在适配国产芯片。
DeepSeek 表示,该模型在训练时采用了 UE8M0 FP8 尺度数据格式,以确保与微缩放数据格式的兼容性。该模型特别“为即将发布的国产芯片设计”。
这一消息暗示,中国在构建由国内技术组成的、自给自足的人工智能技术栈方面已取得关键进展。这一发展有望帮助中国摆脱美国芯片出口的限制。
对函数调用的影响
DeepSeek 声称函数调用功能得到了整体改进,但在推理模式下,函数调用功能却被禁用了,这对于那些在思考过程中需要使用工具的智能体工作流造成了不便。
这一点至关重要,因为一个智能体在规划时常常需要代码运行器、网页抓取器或数据库调用。在推理过程中阻止这些调用,会使复杂的循环变得更加困难。
架构与训练
模型架构保持不变,总参数量为 6710 亿,每个 Token 的激活参数为 370 亿,这意味着每次只有网络的一部分被激活,从而节省计算资源。
训练过程额外增加了 8400 亿 Token 的数据,并更新了分词器和聊天模板,以便更清晰地将文本映射为 Token。
在 Artificial Analysis 的智能指数上,V3.1 推理模式得分为 60,高于 R1 的 59,但仍落后于 Qwen3 235B 2507 推理模式的 64 分,以及顶尖闭源模型的约 69 分。
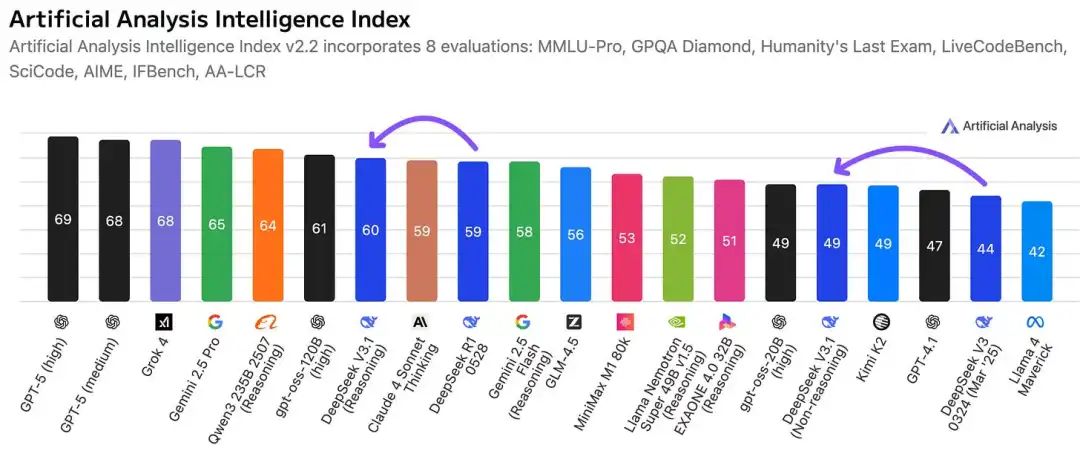
非推理模式的 V3.1 得分为 49,高于 V3 0324 版本的 44 分,与该图表上的几个中端系统水平相当。
Token 效率体现在数据上
在 AIME 2025 测试中,V3.1 推理模式使用 15,889 个 Token,准确率为 88.4%;而 R1 使用 22,615 个 Token,准确率为 87.5%。 在 GPQA Diamond 测试中,V3.1 使用 4,122 个 Token,准确率为 80.1%;相比之下,R1 使用 7,678 个 Token,准确率为 81.0%。 在 LiveCodeBench 测试中,V3.1 使用 13,977 个 Token,得分为 74.8%;而 R1 使用 19,352 个 Token,得分为 73.3%。
因此,现在的答案质量与之前相当甚至略有提升,同时思考过程使用的词语更少,这既节省了时间也降低了成本。
API 定价与集成
API 定价保持了极强的竞争力:

缓存未命中的输入:每百万 Token 0.56 美元。 缓存命中的输入:每百万 Token 0.07 美元。 输出:每百万 Token 1.68 美元。 这比 GPT-4o 便宜 2 倍。
该 API 通过一个模板同时服务于聊天和推理两种模式,模式切换仅取决于是否存在闭合的思考标签,这使得集成过程非常简单。
美中不足的是,那些需要在推理轨迹内部调用工具的智能体构建,仍然需要变通方案,例如将模型拆分为更短的、非推理模式的片段来运行,并在步骤之间调用工具。
尽管在综合指数上的提升不大,但在软件任务上的巨大进步和更低的 Token 使用量表明,该模型的发展方向更侧重于效率和开发者工作流,而非仅仅追求排行榜上的高分。
对国产 FP8 芯片的支持也预示着一条通往供应弹性的道路。因为经过优化的数值格式,可以让编译器和内核在本地芯片上每个时钟周期移动更少的数据并调度更多的工作。
如果这些加速器能够规模化,同样的模型权重每次查询的运行成本将更低,这对于任何每天服务数百万 Token 的产品都至关重要。
现在,产品的故事线变得更加简单,因为一个模型系列通过一个开关就覆盖了快速聊天和深度思考两种场景,为采用该技术栈的团队减少了决策开销。
如何访问 DeepSeek V3.1
官方网页应用:访问 deepseek.com并使用浏览器聊天。API 访问:开发者可以通过官方 API 调用 deepseek-chat(通用) 或deepseek-reasoner(推理模式) 的端点。该接口与 OpenAI 兼容,因此如果您使用过 OpenAI 的 SDK,其工作流程会感觉非常熟悉。Hugging Face:V3.1 的原始权重已根据开放许可发布。如果您有相应的硬件,可以从 DeepSeek Hugging Face 页面下载并在本地运行。
UE8M0 FP8 到底是什么?
DeepSeek 在其微信公众号文章和媒体报道中明确将 UE8M0 与那些“即将发布的国产芯片”联系起来,因此,这是一种软硬件的协同,而不仅仅是随意的数值调整。
FP8 (8位浮点数) 是一种 8 位数据格式,它通过降低精度来减少内存和带宽使用,从而加速 AI 的训练和推理。UE8M0 是一种拥有 8 位指数和 0 位尾数的格式,它可以进一步提高训练效率,进而降低硬件要求,因为它最多可以减少 75% 的内存使用。
如果 DeepSeek 将这些格式与中国国产芯片相结合,可能会转化为硬件-软件协同方面的新突破。
这是一种用于微缩放 FP8 (MXFP8) 中尺度值的 FP8 格式,而不是用于实际权重或激活值的。 E8M0意味着 8 位指数和 0 位尾数,所以每个值实际上都是 2 的幂次方。因为没有尾数,所以该值没有符号,这就是为什么人们添加 U(代表无符号) 并写作UE8M0。NVIDIA 的文档将 e8m0类型描述为“带有偏置指数的 2 的幂”,范围从2^-127到2^127,并将 255 保留为NaN(非数字),这正是尺度值所需要的,而不是数据值。开放计算项目规范也指出,当尾数位为 0时,符号位被省略,这与UE8M0中的 “U” 相符,也符合微缩放 FP8 使用的标准表示法。
UE8M0 FP8 在实践中如何使用?
微缩放 FP8 (MXFP8)通常将每个小数据块(比如 32 个元素)以 FP8 格式存储,然后附加一个以 E8M0 编码的共享尺度值。
数据块中的每个值都通过 尺度值乘以元素值 的方式重构。这样,你既可以保留微小的 FP8 张量,又能通过调整尺度值来覆盖广泛的数值范围。
MX 标准明确指出,所有 MX 格式都使用 E8M0作为共享尺度,并将其与用于元素的E4M3或E5M2格式配对。NVIDIA 的训练技术栈也解释了同样的概念,并补充说 Blackwell 架构引入了一流的 MXFP8支持,其中块级尺度是E8M0而不是 FP32,从而使整个数据包都对 8 位友好。
DeepSeek 特别指出 UE8M0 为何重要?
这意味着它的数值计算、校准和损失缩放都是在循环中针对该尺度表示进行调优的。这使得在任何实现 MXFP8 并采用 E8M0 尺度的加速器上部署模型变得更加安全,因为训练时和运行时的格式是匹配的。
DeepSeek 还表示,这是为了“即将发布的下一代国产芯片”,因此他们正在使其模型与这些芯片计划支持的标准保持一致。
从 UE8M0 和 FP8 中,你实际上能得到什么?
从 FP16 或 BF16 降至 FP8,大致可以将内存占用减半,并在支持 FP8 通用矩阵乘法 (GEMMs) 加速的硬件上使数学吞吐量翻倍。这就是为什么供应商在训练和推理中大力推广它的原因。 与 FP32 相比,内存占用下降了 75%,因为 FP8 每个数字使用 1字节,而 FP32 使用4字节。在实践中,像 TensorRT-LLM 这样的技术栈和云平台报告称,在 H100 级别的部件上使用 FP8 可以在延迟和吞吐量方面取得显著的胜利,在计算密集型阶段通常超过 2 倍,不过结果取决于具体的工作负载和内核。
为什么这对国产芯片尤其重要?
如果即将推出的国产加速器实现了带 E8M0 尺度的 MXFP8,DeepSeek 的模型就可以高效运行,无需脆弱的转换路径,从而降低内存流量并提高矩阵乘法 (Matmul) 吞吐量。
这有助于通过从每瓦特电力和每 GB 的高带宽内存 (HBM) 中榨取更多有效工作,来缩小与受出口管制的 GPU 之间的差距。
几个需要注意的细微之处,以保持现实的期望
UE8M0是用于尺度的,而不是用于实际张量元素的,后者仍然是E4M3或E5M2;这就是为什么准确性能保持的原因。MXFP8需要仔细的数据布局,转置 MX 张量通常意味着需要用新的块级尺度进行重新量化,现在的框架可以处理这个问题,但这是一个需要关注的实际实现细节。FP8 并不能在所有地方取代更高的精度;许多操作仍然在 BF16 或 FP32 中运行以保证稳定性,这一点在 FP8 训练论文中也得到了强调,同时该论文也表明,如果操作正确,FP8 的性能可以与 16 位精度相媲美。
关于 “UE8M0 FP8” 的底线
UE8M0 使 DeepSeek-V3.1 在数值上与 MXFP8 硬件兼容,这意味着更小的内存占用、更高的吞吐量,以及在即将推出的、选择相同标准尺度的国产加速器上更容易运行的路径。
参考资料:https://huggingface.co/deepseek-ai
https://www.deepseek.com/
https://api-docs.deepseek.com/news/news250821
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!










