编辑丨具身智能之心
本文只做学术分享,如有侵权,联系删文
更多干货,欢迎加入国内首个具身智能全栈学习社区:具身智能之心知识星球(戳我),这里包含所有你想要的。

写在前面&出发点
基准是机器人学和具身AI领域评估进展的核心工具,但当前基准存在显著割裂:高层语言指令遵循类基准常假设低层执行完美,而低层机器人控制类基准仅依赖简单单步指令。这种割裂导致无法全面评估“任务规划+物理执行”均关键的集成系统。

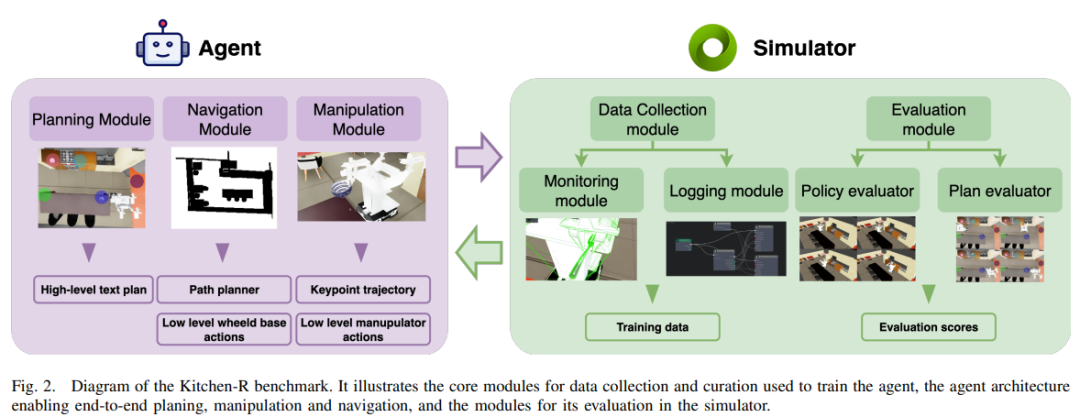
为填补该空白,这里提出Kitchen-R基准——一个在仿真厨房环境中统一评估任务规划与低层控制的新基准。其核心特点包括:
基于Isaac Sim模拟器构建真实厨房的数字孪生; 包含500+条复杂语言指令,支持mobile ALOHA移动操作机器人; 提供基线方法:基于视觉语言模型(VLM)的任务规划策略、基于扩散策略(Diffusion Policy)的低层控制策略,以及轨迹收集系统; 支持三种评估模式:独立评估规划模块、独立评估控制策略、关键的全系统集成评估。
Kitchen-R填补了具身AI研究的关键空白,为语言引导机器人代理提供了更全面、更贴近真实场景的基准测试平台。
领域背景介绍
1)基准的重要性
基准在自然语言处理(如GLUE)、计算机视觉(如Visual Genome)中广泛用于评估模型进展;在机器人领域,基于模拟器的基准(如Behavior-1K)同样常见,兼具模型评估与训练功能,且需准确模拟低层动作以支持真实机器人的结果迁移。
2)现有基准的割裂问题
近年来,大语言模型(LLMs)和视觉语言模型(VLMs)被广泛用于机器人任务规划与指令遵循,但现有基准存在明显缺陷:
高层指令遵循基准(如VirtualHome、ALFRED):仅聚焦任务规划评估,常假设原子任务执行100%成功,或简化物理交互(如仅操作目标物体掩码); 低层控制基准(如Arnold、BEHAVIOR-1K):强调真实动作执行,但依赖短单步语言指令,或完全省略语言引导。
3)Kitchen-R的核心价值
Kitchen-R通过“数字孪生厨房+多模态评估”解决上述割裂,具体包括:
环境:基于Isaac Sim构建真实厨房的数字孪生,支持mobile ALOHA机器人; 数据:500+条复杂语言指令,覆盖移动操作任务; 基线:VLM-based任务规划基线、Diffusion Policy低层控制基线; 评估:支持“规划独立评估、控制独立评估、全系统集成评估”三种模式; 应用:已用于2024年AIJ竞赛具身AI赛道的数据收集与验证,累计收集约2700条移动操作轨迹。
4)关键贡献
Kitchen-R基准:提供具身AI研究所需的数字孪生厨房环境与500+语言指令;
基线方法:VLM驱动的任务规划基线与Diffusion Policy低层控制基线;
灵活框架:支持系统组件模块化评估的数据收集与评估体系。
相关工作
现有基准因设计目标不同,难以同时覆盖“高层语言规划+低层物理执行”的联合评估,具体对比如下:

Kitchen-R的定位:融合上述框架优势,实现“规划模块独立评估、控制模块独立评估、全系统集成评估”三位一体,同时支持轨迹日志记录与Isaac Sim的照片级真实模拟。
问题公式化
将移动操作机器人的指令遵循问题拆解为任务规划与移动操作两个子问题,明确输入输出与目标。

1)任务规划子问题(高层控制)
核心目标:基于VLM将自然语言指令转化为可执行的任务计划,需考虑虚拟环境的特征与限制。 输入:
自然语言指令(导航+物体操作任务); 场景俯视图。
2)移动操作子问题(低层控制)
核心目标:生成移动操作机器人的动作轨迹,确保物理执行的准确性。 输入:
分解后的单步自然语言任务; 机器人搭载的两个相机视觉信息(夹爪相机+底座中央相机)。
,:机器人底座的线速度/角速度; :末端执行器的偏移坐标; :末端执行器姿态的四元数; g:夹爪开合度(0=闭合,1=打开)。
评估指标
Kitchen-R针对“离线独立评估”与“在线联合评估”设计了两类指标,确保全面衡量系统性能。
1)离线独立评估指标
任务规划:精确匹配率(EM)
衡量生成计划与真实计划的步骤一致性,字符级完全匹配才算正确步骤。
:总计划数; :第(i)个计划中正确预测的步骤数; :第(i)个真实计划的总步骤数; 高EM值表示计划生成的准确性高。
移动操作:均方误差(MSE)
衡量预测轨迹与专家轨迹的偏差,平均所有轨迹的MSE作为最终结果,值越小表示控制精度越高。
综合指标(P)
融合规划与控制性能,值越小表示系统整体表现越好:
:总指令数; :第(i)条指令对应的任务数; :第(j)个任务的轨迹MSE。
2)在线联合评估指标
在模拟器中实时执行任务,同时评估规划与执行,核心指标为EM与成功率(SR),最终合并为指标(M)。
成功率(SR)
单任务成功定义: 导航任务:机器人底座几何中心与目标位置的距离≤10cm; 操作任务:被操作物体几何中心与目标位置的距离≤5cm; 时间限制:单任务需在120秒内完成(超时视为失败)。 SR取值:成功=1,失败=0。
在线评估流程
规划模块输入高层指令,生成计划,与真实计划对比计算EM;
用真实计划执行(隔离规划误差),确保公平评估控制模块;
控制模块执行每个任务,记录SR与完成时间。
最终联合指标(M)
:第j个任务的计划EM值; :第j个任务的成功率; 高M值表示规划准确且执行可靠;
Kitchen-R基准核心设计
Kitchen-R基于Isaac Sim构建模块化框架,支持数据收集、任务执行与评估,核心模块如下:
1)策略评估器(Policy Evaluator)
功能:执行高层任务计划,是规划与控制的“桥梁”; 流程:
输入:从高层规划器接收分解后的子任务; 数据交互:从模拟器获取场景数据; 模块调用:依次触发导航模块与操作模块执行子任务。
2)导航模块
负责机器人底座的移动,由路径规划器与低层控制器组成。
路径规划器
算法:采用Theta*算法(支持任意方向的栅格规划,确保路径与障碍物距离≥机器人占地面积半径(R)); 输入:机器人当前位姿、目标点、2D占据栅格地图(预计算,可每(N)步更新或固定); 输出:折线型路径(含最多100个路点)。
低层控制器(ROS框架+C++实现)
基于里程计计算位置误差,动态调整速度,核心逻辑:
距离误差(路点切换条件):当时,切换到下一个路点(为当前路点索引)。 角度误差(航向校正):其中,角度误差被包裹在区间以确保连续性。 速度控制策略:
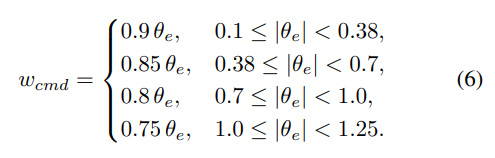
近目标减速:当且时,逐步降低线速度上限;当时,校正最终航向(为目标航向),旋转至。
3)操作模块
负责末端执行器的抓取、放置等动作,核心是RMPs运动控制与10阶段有限状态机(FSM)。
(1)RMPs(Riemannian Motion Policies)
功能:计算8DoF关节(不含夹爪)的加速度,平衡“目标吸引”“碰撞排斥”“关节限位”“阻尼”等约束; 原理:
每个任务(如末端执行器位姿、关节配置)定义任务映射、黎曼度量(任务惯性)、期望力(政策行为); 通过雅可比矩阵将任务空间的映射到关节空间; 合并得到关节加速度,积分后发送至Isaac Sim的关节控制器。
(2)10阶段FSM(拾取-放置循环)
每个阶段对应一个子动作(如接近物体、下降、抓取、提升、运输、释放),阶段间采用余弦混合运动插值确保平滑过渡:插值覆盖末端执行器的位置、高度与姿态,确保动作连续且无突变。
4)日志模块
支持两种数据格式: rosbag:兼容标准机器人接口,模拟真实机器人数据格式; hdf5:读写快、内存效率高,但不兼容机器人标准接口; 数据传输:通过Isaac Sim的ROS Bridge扩展,将模拟器数据转换为ROS话题(相机、IMU、LiDAR、TF、里程计),再通过ROS重发布器记录。
5)监控模块
实时验证数据质量与动作执行,避免无效轨迹收集:
动作成功检查:每步验证“移动、拾取、放置”是否成功,超时(配置文件设定阈值)则标记轨迹失败并终止; 关键物体检查:操作过程中检测物体是否掉落,拾取时检查夹爪与物体的距离(需≤配置阈值),放置后检查物体与目标点的距离; 日志速率监控:实时检查ROS话题的日志频率,低于阈值则终止记录(避免低频率数据影响模型训练); 碰撞网格预检查:执行前验证物体碰撞网格的正确性,避免因网格错误导致的抓取失败。
6)定制化与随机化
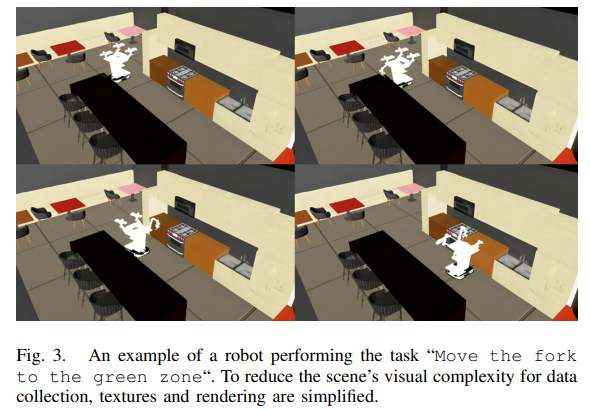
场景/物体添加: 新场景:配置中指定USD文件路径与缩放比例; 新物体:同场景添加逻辑,仅需补充物体USD路径; 随机化设置: 关键物体:位置在配置的圆形区域内随机; 机器人:初始区域与区域内的位置随机; 背景物体:模型、纹理、位置随机(不与机器人交互); 场景纹理:地板、墙壁等纹理随机。
7)传感器支持
多模态数据收集:RGB-D图像(相机)、点云(LiDAR); 传感器添加:仅需在机器人/场景模型中添加传感器,配置中补充其路径即可(数量受硬件性能限制)。
8)新任务创建
基于“移动、拾取、放置”三个基础动作,通过配置文件定义:
基础动作序列(如“移动到点1→拾取物体1→移动到点2→放置物体1”); 关键点位(如移动的接近点、拾取的物体位姿与偏移量); 物体列表(背景物体:USD文件夹路径;关键物体:USD路径+抓取偏移量)。
9)语言指令
规模:563条自然语言指令,覆盖厨房移动操作任务; 生成逻辑:
选择场景→选择58个模板中的1个→选择4-8步的计划; 替换模板中的物体为场景中存在的物体,确保指令可执行;
基线方法
Kitchen-R提供两类基线,分别对应任务规划与移动操作,为后续研究提供对比基准。
1)VLM规划基线(基于OmniFusion)
核心流程
输入:场景俯视图(含彩色区域标记)、自然语言指令; 输出:分解后的单步任务计划; 优化策略:
上下文示例:提供正确计划的示例(因OmniFusion仅预训练单图对话,示例用文本描述替代图像); 约束生成:限制输出格式,避免生成无法解析的指令。
性能提升(EM指标)

可见,上下文计划示例是提升规划准确性的关键,约束生成可进一步优化。
2)移动操作基线(基于Diffusion Policy)
(1)模型结构
输入条件:
视觉特征:两个相机的图像特征(历史窗口大小=2),通过视觉backbone提取(不同相机backbone不共享权重,训练时学习率更新权重为10%); 机器人状态:10维状态(末端执行器平移3维、姿态6维、夹爪开合1维),历史窗口大小=2;

基线验证与结果
1)验证流程(四步)
步骤1:定义分布参数
设定环境初始状态的采样范围:
机器人初始位置:在指定线段集合上均匀采样; 操作物体:从{苹果、碗、杯子、叉子、盘子}中选1个; 物体位置:从5个候选点中选“起点”和“终点”,在点的周围圆形区域内采样初始/目标位置; 采样半径:配置文件指定物体初始/目标位置的采样半径。
步骤2:生成环境配置
若评估语言指令可行性:固定物体类型与初始/目标位置; 若评估通用政策:随机采样物体类型与位置; 可预生成配置批次并保存,确保不同政策在相同环境下对比。
步骤3:创建环境
基于配置,生成符合OpenAI Gym接口的环境。
步骤4:执行评估
环境重置:恢复到初始配置状态; 交互循环:政策接收环境观测(分解后的任务+相机视觉)→生成动作→环境执行动作; 终止条件:任务成功或超时(120秒); 结果记录:每个子任务的成功标志与执行时间,最终平均得到性能指标。
2)执行效率
单 episode 时间(NVIDIA GeForce RTX 3060 Ti): oracle政策(完美执行):约1分钟; 高推理时间政策:最长50分钟。
未来,Kitchen-R可进一步扩展场景复杂度(如多机器人协作、动态环境),推动语言引导的移动操作机器人向更真实的应用场景落地。
参考
[1] Mind and Motion Aligned: A Joint Evaluation IsaacSim Benchmark for Task Planning and Low-Level Policies in Mobile Manipulation.