
编辑丨具身智能之心
本文只做学术分享,如有侵权,联系删文
更多干货,欢迎加入国内首个具身智能全栈学习社区:具身智能之心知识星球(戳我),这里包含所有你想要的。
当机器人 “看懂” 指令还能 “自主干活”:大型 VLM 如何改写机器人操作的游戏规则?
你是否想象过这样的场景:对着机器人说一句 “把阳台晾干的衬衫叠好放进衣柜第三层”,它就能看懂衣物位置、理解 “叠好”“放进” 的动作逻辑,甚至避开衣柜里的杂物完成任务?放在几年前,这更像科幻电影里的情节 —— 传统机器人要么困在 “预定义任务牢笼” 里,换个新杯子就认不出;要么面对模糊的自然语言指令 “手足无措”,更别提在杂乱的真实环境里灵活调整动作。
但现在,一场由 “视觉 - 语言 - 动作(VLA)模型” 掀起的变革,正在打破这些局限。而这场变革的核心推手,正是我们如今耳熟能详的大型视觉语言模型(VLM)。
过去,机器人操作的研究总在 “模块化陷阱” 里打转:视觉识别、语言解析、动作控制各成一派,像被割裂的齿轮,很难协同运转。直到大型 VLMs 的出现 —— 这些在海量图文数据上 “吃透” 视觉与语言关联的模型,不仅能看懂图片里的细节、理解人类指令的深意,还能把这种 “理解” 转化为机器人能执行的动作逻辑。于是,基于大型 VLM 的 VLA 模型应运而生:它像给机器人装了 “通感大脑”,既能通过视觉捕捉环境动态,又能通过语言锚定任务目标,最终生成连贯、灵活的操作动作。比如让它 “把红色马克杯放到笔记本旁的书架上”,它能自动完成 “找杯子 - 判断位置 - 规划移动路径” 的全流程,甚至应对杯子被书本挡住的突发情况。
不过,这个快速发展的领域也藏着不少 “迷雾”:有人把 VLA 模型拆成多个模块,有人追求 “端到端” 的统一架构;数据集要么是模拟环境的 “理想数据”,要么是真实世界的 “零散样本”;更别提大家对 “如何让机器人记住过往动作、完成长期任务”“怎样让模型在不同机器人上通用” 这些问题,还没形成统一答案。
为了理清这些脉络,哈尔滨工业大学(深圳)的研究者们撰写了这篇《Large VLM-based Vision-Language-Action Models for Robotic Manipulation: A Survey》。它不仅是首个系统梳理 “大型 VLM + 机器人操作” 的综述,更像一张 “领域地图”—— 从 VLA 模型的定义、两种核心架构(单体式 / 分层式),到如何结合强化学习、从人类视频里学技能,再到未来要突破的 4D 感知、记忆机制等方向,都被清晰地呈现出来。
如果你想知道 VLA 模型如何让机器人从 “机械工具” 变成 “懂你意图的帮手”,想抓住这个领域的核心技术与未来机会,那么这份综述,正是打开大门的钥匙。
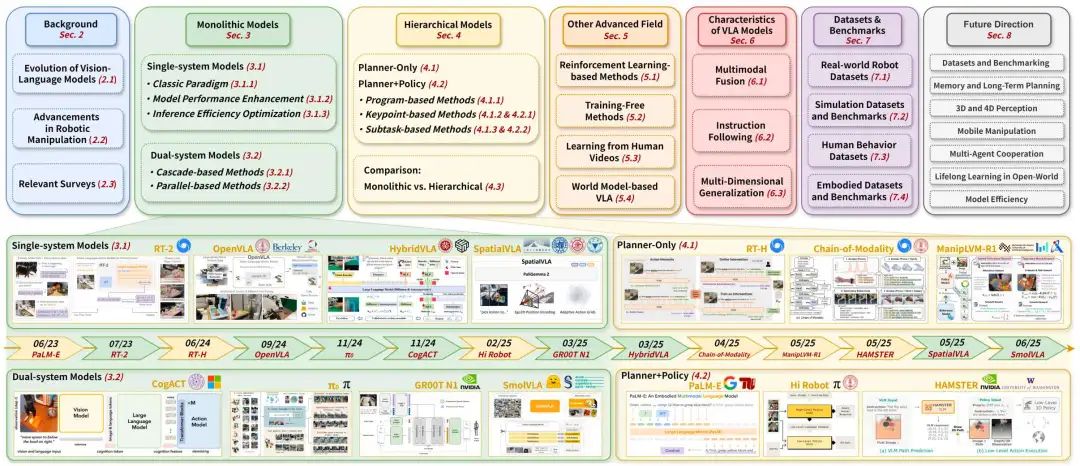
图1|本综述的组织大纲(上)和大型基于VLM的机器人操作视觉语言动作模型的显著发展的时间顺序时间表(下)。时间表突出了单体模型和分层模型的代表性里程碑,提供了该领域最近进展的视角。
作者: Rui Shao, Wei Li, Lingsen Zhang, Renshan Zhang, Zhiyang Liu, Ran Chen, Liqiang Nie
单位:哈尔滨工业大学(深圳)计算机学院
论文标题:Large VLM-based Vision-Language-Action Models for Robotic Manipulation: A Survey
论文链接:https://arxiv.org/abs/2508.13073
项目主页:https://github.com/JiuTian-VL/Large-VLM-based-VLA-for-Robotic-Manipulation
主要贡献
纵向梳理VLA模型发展脉络:系统回顾VLM的进化历程、机器人操作学习的技术进展及VLA范式的诞生,明确单体模型(Monolithic)与分层模型(Hierarchical)的发展路径,识别关键挑战并展望未来方向。
横向整合VLA建模实践:提出更精细的VLA模型分类体系(单体/分层),从结构与功能双维度深入分析两类模型,探索强化学习融合、无训练优化等前沿方向,总结支撑模型发展的数据集与核心特性。
解决领域研究痛点:统一VLA领域术语与建模假设,缓解跨学科(机器人学、计算机视觉、NLP)研究碎片化问题,填补“VLMs与机器人操作交叉领域”的系统性综述空白,并维护实时更新的项目页(https://github.com/JiuTian-VL/Large-VLM-based-VLA-for-Robotic-Manipulation)。
研究背景
视觉语言模型(VLMs)的进化
架构转型:从任务特定架构转向统一多模态框架(如LLaVA1.5、Qwen-VL),核心由“视觉编码器+特征投影器+大型语言模型”构成,可处理视觉问答、空间导航等复杂任务,且能通过视觉指令微调(如LLaVA用GPT-4生成15万对话样本)提升开放指令理解能力。
能力扩展:近年VLMs向多模态感知与推理升级,如LLaVA-OneVision统一图像/视频处理、Qwen-2VL支持动态分辨率、Vision-R1用强化学习优化推理链,为整合“动作生成”奠定基础。

图2|基于大型VLM的机器人操作视觉语言动作(VLA)模型的核心优势。基于VLM的大型VLA模型利用了大型视觉语言模型的优势,包括:(1)开放世界泛化,(2)分层任务规划,(3)知识增强推理,(4)丰富的多模态融合。
机器人操作技术的进展
早期局限:传统方法依赖分离的视觉编码器、语言模块与规划器(如CLIPort用CLIP做语义接地、RT-1用CNN+独立语言嵌入),泛化性差,难以处理未知物体或模糊指令。
VLA模型突破:以RT-2为代表,将机器人动作离散化为文本token,与VLM(PaLM-E/PaLI-X)共训练,实现“视觉-语言-动作”统一建模;后续OpenVLA(7B参数开源模型)、π₀(流匹配架构)进一步提升泛化性与可访问性。
现有综述的不足
多单独聚焦VLMs或机器人操作,缺乏对“VLMs与机器人操作交叉领域”的深入分析
未聚焦“预训练VLM作为基础组件”的主流范式
因覆盖自动驾驶、农业等多领域,稀释了机器人操作特有的实时控制、传感器噪声鲁棒性等挑战
仅关注文本LLM的任务规划,未解决VLM在视觉感知与动作接地的核心问题
研究动机
传统机器人操作的瓶颈:依赖预定义任务规格与刚性控制策略,在非结构化场景(如未知物体、动态环境、模糊自然语言指令)中泛化性与扩展性极差。
VLA模型的潜力:基于预训练VLMs的VLA模型,可复用VLMs的开放世界泛化、分层任务规划、知识增强推理、多模态融合能力,让机器人理解高层指令、识别未知环境并执行复杂操纵任务(如“将红色马克杯放在笔记本电脑旁的顶层架子上”)。
领域研究的碎片化:VLA领域术语不一致、跨学科研究分散,缺乏系统性框架整合现有成果,亟需一篇综述明确模型定义、分类与未来方向。
研究内容
总体框架:VLA模型的定义与分类
定义:满足两个核心条件的模型:① 利用大型VLM理解视觉观测与自然语言指令;② 执行直接/间接服务于机器人动作生成的推理过程。
核心分类:根据“系统整合粒度”与“认知分解显式性”,分为两大类:
单体模型(Monolithic):将感知、语言理解、动作生成整合于单一/双系统架构,无显式中间表示;
分层模型(Hierarchical):显式分离“规划”与“执行”,通过人类可解释的中间表示(如子任务、关键点、程序)连接规划器与策略器。

图3|基于VLM的两大类大型VLA模型的比较。单体模型在单系统或双系统架构中集成了感知、语言理解和动作生成,后者包含了一个额外的动作专家。相反,分层模型通过可解释的中间输出(例如,子任务、关键点、程序、功能支持)将规划与策略执行解耦。
单体模型(Monolithic Models)
单系统模型(Single-system Models)
核心思想:视觉感知、语言指令、机器人状态输入统一模型,通过自回归/并行解码输出动作,架构简洁且无复杂模块通信。

图4|单系统VLA模型。在LLM / VLM列中,省略V-Encoder表示VLM;否则表示LLM。在学习列中,“AD”表示自回归解码,“PD”表示并行解码。“SFT”表示与动作预测模仿学习不同的微调,在动作预测模仿学习中,字幕、VQA、推理等任务都属于SFT。括号中的“A”和“B”代表Action head或Backbone使用的学习方法。
三大研究方向:
经典范式:自回归解码
方法:将连续动作空间离散化为token序列,VLM 自回归生成动作token,再通过解令牌器转换为可执行动作。
代表技术:
RT-2 :以PaLM-E/PaLI-X为VLM骨干,训练互联网视觉语言数据与机器人轨迹,将动作视为语言任务,显著提升语义理解与泛化性;
RT-2-X :在RT-2基础上,用Open X-Embodiment(OXE)跨机器人数据集微调,提升技能迁移能力;
OpenVLA :用DINOv2+SigLIP替代大参数视觉编码器,基于LLaMA2-7B,在真实机器人演示数据上微调,开源且性能优异。
模型性能增强
感知模态扩展:加入3D(Leo Agent 用PointNet++处理点云、SpatialVLA通过深度估计生成3D坐标)、4D(TraceVLA叠加运动轨迹、4D-VLA 整合3D坐标与历史关键帧)、触觉/听觉(VTLA融合触觉、VLAS 用Whisper提取语音);
推理能力提升:引入思维链(ECoT生成推理链、CoT-VLA 预测像素级子目标观测)、分层闭环控制(LoHoVLA 处理长程任务)
泛化性优化:统一动作空间(UniAct定义通用动作码本)、可逆训练(ReVLA恢复视觉编码器预训练状态以减少灾难性遗忘)、多模态融合(FuSe 用自然语言对齐触觉/听觉)。
代表技术:Leo Agent 、TraceVLA、CoT-VLA、UniAct、VTLA 。
推理效率优化
方法:从架构、参数、解码策略三方面降低推理开销。
架构优化:动态层跳过(MoLe-VLA用STAR路由器选择关键LLM层)、早期退出(DeeR-VLA 通过输出一致性判断是否终止推理)、Mamba架构(RoboMamba 实现Transformer的推理速度的三倍);
参数优化:模型压缩(BitVLA 用‘1-bit’权重、NORA 设计小参数模型);
解码加速:并行解码(PD-VLA 将自回归转为不动点迭代、RoboFlamingo 用独立MLP动作头)、投机解码(Spec-VLA速度提升1.42倍)、动作复用(FlashVLA稳定场景下跳过推理)。
代表技术:RoboMamba、DeeR-VLA 、BitVLA 、PD-VLA 、FlashVLA。

图5|单系统模型中代表性范例的比较。
双系统模型(Dual-system Models)
核心思想:分离“高层推理(System 2:VLM骨干)”与“低层动作生成(System 1:动作专家)”,平衡推理精度与实时性,无显式中间表示(区别于分层模型)。
两大研究方向:
级联式(Cascade-based)
方法:System 2处理多模态输入生成 latent 认知表示,再传递给System 1解码为动作,串行执行。
代表技术:
DP-VLA :用OpenVLA为System 2,Behavioral Cloning Transformer为System 1,兼顾效率与性能;
HiRT:System 2低频运行(理解场景),轻量级System 1高频控制,适配动态环境;
TriVLA :新增“世界动态感知模块”(System 3),补充静态感知的不足。

图6|双系统模型中代表性范式的比较。
并行式(Parallel-based)
方法:System 2与System 1并行运行,通过共享注意力/交叉注意力交互信息。
代表技术:
π₀ :以PaliGemma为预训练VLM(System 2),训练流匹配(Flow Matching)动作专家(System 1),支持零样本泛化;
SmolVLA :冻结轻量级SmolVLM-2(System 2),仅训练下游流匹配Transformer(System 1),提升效率;
ForceVLA :在π₀基础上加入MoE结构的力感知模块,优化接触密集型操纵。

图7|双系统VLA模型。“System 2骨干网”列列出了双系统方法中作为System 2组件的VLM骨干网。“系统1学习”一栏列出了作为系统1的行动专家使用的学习方法。“Diff.”表示基于扩散的学习,“FM”表示流匹配,“MSE”表示均方误差,“BCE”表示二元交叉熵,“AR”表示自回归学习。
分层模型(Hierarchical Models)

图8|分层VLA模型。“Type”列表示规划器的输出类型,其中“K”表示Keypoint,“S”表示Subtask,“P”表示Program。“学习”一栏表示模型采用的学习方法,其中“SFT”指监督微调,“RL”指强化学习,“IM”指模仿学习,“API”是一种特殊情况,指调用已有模型。
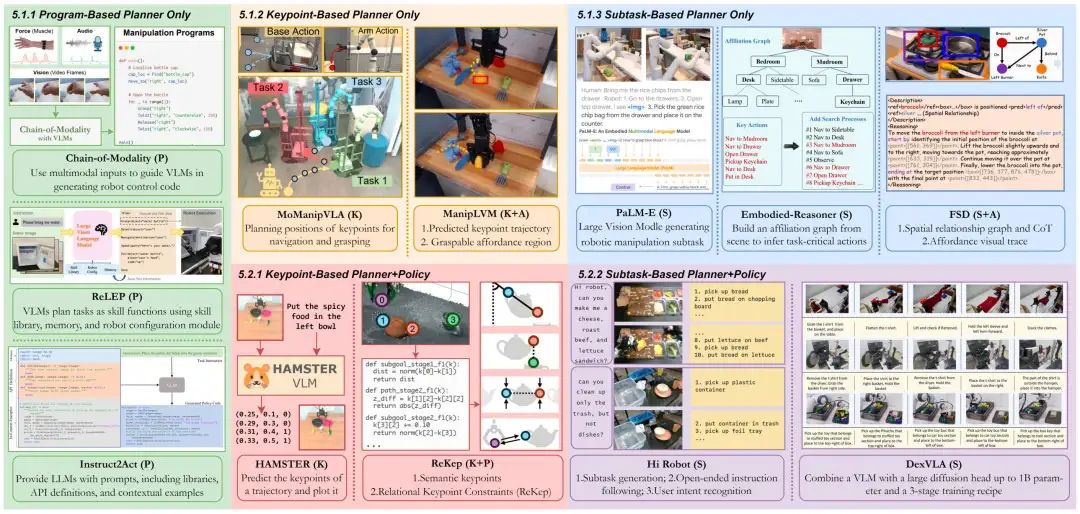
图9|显示本次调查中分层模型的图表。这些模型根据其构成分为两类,即“仅规划器”和“规划器+策略器”。根据中间表示类型,一类可以进一步分为基于子任务的(S)、基于关键点的(K)和基于程序的(P)。“(A)”表示为辅助目的组合功能的方法。
仅规划器(Planner-Only)
核心思想:规划器生成人类可解释的中间表示,依赖现成(off-the-shelf)策略器执行动作,仅聚焦规划器设计。
三大研究方向:
基于程序(Program-based)
方法:规划器生成“机器人可执行程序”或“辅助策略理解的程序”。
代表技术:
Chain-of-Modality :多模态对话生成Python程序控制机器人;
Instruct2Act :生成调用API的Python代码;
RoVI :生成辅助程序,通过平移/旋转成本决议执行;
ReLEP :用带记忆库的VLM分解任务为技能库中的基础技能,生成辅助程序。
基于关键点(Keypoint-based)
方法:规划器预测场景中的显著关键点(如抓手目标位置、物体交互区域)。
代表技术:
MoManipVLA :VLA预测关键路点,通过双层轨迹优化生成动作;
RoboPoint :解析自然语言生成视觉关键点;
ManipLVM-R1 :用GRPO训练VLM,同时预测抓取可行域与物体轨迹;
RoboBrain :LLaVA做高层规划,A-LoRA识别交互区域,T-LoRA预测轨迹路点。
基于子任务(Subtask-based)
方法:规划器将高层指令分解为步骤化文本子任务。
代表技术:
PaLM-E :LLaVA风格VLM,统一VQA与机器人指令生成;
Embodied-Reasoner :引入“观测-思考-动作”轨迹,支持空间分析与验证;
Reinforced Planning :SFT+GRPO强化学习,提升泛化性;
ViLA :用GPT-4V生成候选任务计划,仅执行第一个指令。
规划器+策略器(Planner+Policy)
核心思想:规划器生成中间表示,策略器接收该表示并生成可执行动作,端到端优化规划与执行。
两大研究方向:
基于关键点(Keypoint-based)
方法:规划器预测空间基元(如离散关键点、2D路径),策略器生成连续轨迹。
代表技术:
HAMSTER :预测轨迹关键点并生成渐变色路径,指导策略执行;
ReKep :DINOv2+SAM生成关键点,GPT-4o转为成本函数,优化为动作;
A₀ :规划器预测接触点与接触后运动,策略器转换为控制信号。
基于子任务(Subtask-based)
方法:规划器分解子任务,策略器接收子任务token生成动作。
代表技术:
HiRobot :规划器将开放指令分解为原子命令,策略器执行;
DexVLA :VLM规划器+扩散动作策略器,擅长长程复杂任务;
PointVLA :在DexVLA基础上加入点云编码器,提升空间感知;
RoBridge :规划器生成原始动作文本指令,构建“不变可操作表示”供策略器执行;
RoboMatrix :三层架构(调度层生成子任务、技能层选择行为、硬件层控制)。
其他先进领域

图10|代表性的VLA方法分为四个高级类别:基于强化学习、无训练、从人类视频中学习和基于世界模型的方法。
基于强化学习(RL-based Methods)
核心思想:通过在线交互(实时优化)或离线轨迹(预收集数据)优化VLA策略,解决奖励稀疏、样本效率低问题。
代表技术:
奖励设计:VLA-RL 训练机器人过程奖励模型(RPRM)、ReWiND 以“目标进度”为奖励、Grape用VLM生成反馈奖励;
训练范式:ReWiND(离线IQL+在线SAC)、HIL-SERL(人类在环干预)、ConRFT (离线Cal-ConRFT+在线HIL-ConRFT);
数据引擎:RLDG (训练专家策略后蒸馏到基础模型)、iRe-VLA(在线RL收集轨迹+SFT迭代优化)。
无训练方法(Training-Free Methods)
核心思想:通过架构/计算优化提升VLA效率,无需重新训练,保留原模型能力。
代表技术:
令牌优化:FlashVLA (稳定场景跳过解码)、EfficientVLA (剪枝冗余语言层+过滤视觉令牌);
解码加速:PD-VLA (并行不动点迭代)、FAST(DCT+字节对编码压缩动作序列);
调度优化:RTC (监控任务进度调整控制频率)。
从人类视频学习(Learning from Human Videos)
核心思想:利用人类-物体交互与机器人-物体交互的结构相似性,从人类视频中迁移任务知识,缩小embodiment gap。
代表技术:
Human-Robot Semantic Alignment :用人类-机器人配对视频对齐视觉编码器;
UniVLA :从无标注人类/机器人视频学习任务中心 latent 动作;
LAPA :VQ-VAE量化 latent 动作,在大规模视频-语言数据上预训练;
3D-VLA :融合人类交互视频与机器人演示,提升3D推理;
Humanoid-VLA :从在线视频恢复姿态轨迹,增强运动多样性。
基于世界模型(World Model-based VLA)
核心思想:整合世界模型(预测环境动态的紧凑表示),通过模拟未来状态优化动作规划,提升长程任务能力。
代表技术:
WorldVLA :自回归动作-世界模型,联合预测视觉结果与生成动作;
World4Omni :大规模世界模型生成子目标图像,指导低层级策略;
3D-VLA :生成式世界模型预测未来目标图像与点云;
V-JEPA 2-AC :基于互联网规模视频训练的动作条件世界模型,通过模拟未来 latent 状态做规划。

图11|VLA的代表性RL进路。✓代表在线,而✗代表离线。“S”代表稀疏奖励,“D”代表密集奖励,“RM”代表预训练。其中,“GPT”表示GPT给出的奖励,“TC”表示基于任务完成的奖励函数。
VLA 模型的特征
VLA 模型区别于传统机器人操作模型的核心能力:
多模态融合:通过统一嵌入与动态整合打破模态壁垒。一是构建 “共享嵌入空间”,依托预训练 VLM 生成视觉与语言的联合嵌入,减少模块间语义偏移;二是实现 “令牌级整合”,将视觉、语言、动作等连续模态离散为令牌,由单个 Transformer 处理以捕捉跨模态依赖;三是具备 “全面模态兼容性”,可无缝整合点云(如 PointVLA)、触觉(如 VTLA)、音频(如 VLAS)等新模态,无需修改核心架构或全量重训。
指令遵循:依托语义理解与推理实现灵活指令响应。一是 “语义指令定位”,利用 VLM 世界知识动态解读模糊指令,如 ChatVLA-2 可理解白板上的数学问题并选择数字卡片;二是 “任务分解与协作”,将长期任务拆分为子目标,如 LoHoVLA 生成自然语言子任务指导动作;三是 “思维链推理”,通过预测未来视觉状态(如 CoT-VLA)缓解短视幻觉,提升复杂任务可靠性。
多维度泛化:实现跨任务、跨领域、跨载体的广泛适配。一是 “跨任务泛化”,如 DexVLA 无需任务调优即可完成多样操作,性能超越 OpenVLA;二是 “跨领域泛化”,如 π₀ 通过异构数据联合训练,在家庭环境中分布外任务成功率超 90%;三是 “跨载体与模拟到现实泛化”,如 HAMSTER 依托分层架构,在七个泛化维度上成功率比 OpenVLA 高 20%。
数据集与基准测试
真实世界机器人数据集:
特点:捕捉真实环境复杂性,支持语言与动作对齐。但开放世界物体、场景、技能的长尾分布仍未充分覆盖。
典型案例:
OXE(整合 22 个机器人平台的 100 万 + 多模态演示)
RH20T(支持 147 项任务单样本学习)
DROID(含 564 项 “自然场景” 远程操作演示)
模拟数据集与基准测试:
特点:提供可扩展、安全的训练环境,降低真实数据采集成本。但存在物理模拟不完美、视觉伪影等局限。
典型案例:
BEHAVIOR(支持杂乱家庭环境多步骤控制)
CALVIN(支持无约束语言指令下的长期操作)
SIMPLER(通过校准环境减少模拟到现实差距)
人类行为数据集:
特点:提供语义丰富的人类交互先验,辅助 VLA 理解操作逻辑;可帮助 VLA 学习目标识别、动作序列与任务分解。
典型案例:
Ego4D(3000 小时第一视角视频)
EPIC-Kitchens(细粒度烹饪任务视频)
EgoDex(829 小时含 3D 手部追踪的第一视角视频)
具身数据集与基准测试:
特点:聚焦 VLA 的规划与推理能力评估,推动从 “操作” 向 “认知 + 操作” 升级。为高层语义规划提供严格评估标准。
典型案例:
OpenEQA(评估功能与常识推理)
LoTa-Bench(验证 LLM 生成规划的可执行性)
MT-EQA(支持多目标推理)
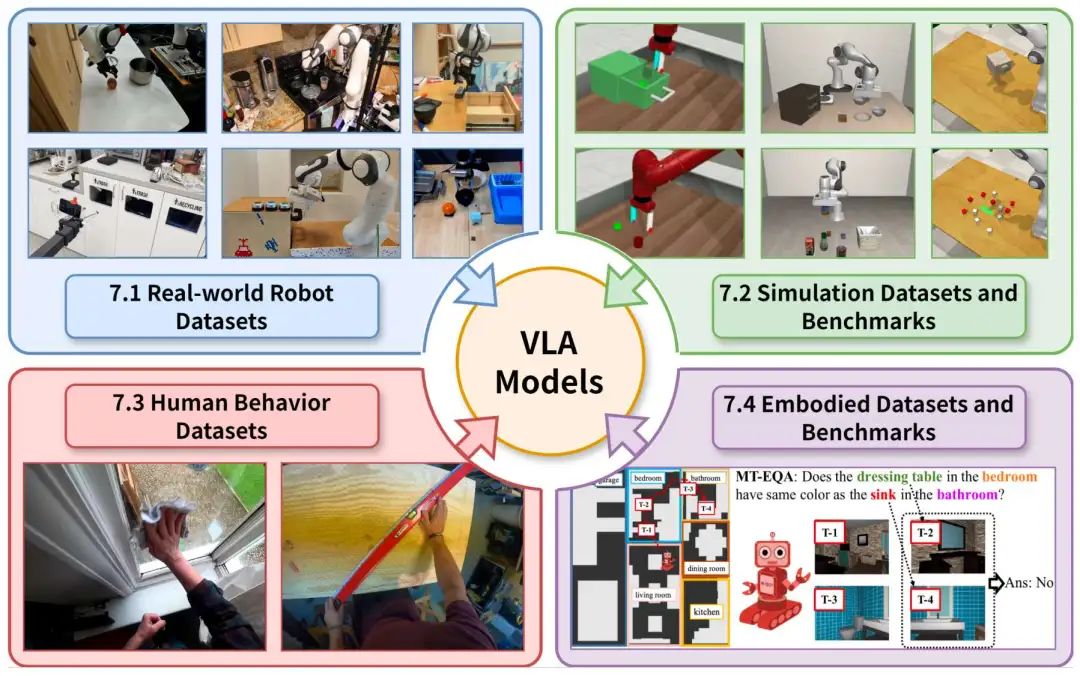
图12|四种数据集类型,支持用于机器人操作的基于VLM的大型VLA模型。
未来方向
数据集与基准测试优化:需结合大规模真实世界数据采集与复杂任务套件(如长期规划、移动操作),引入子任务成功率、时间效率、抗干扰性等多维度评估指标,解决现有数据 “现实差距” 与基准 “任务单一” 问题。
记忆机制与长期规划:设计具备情景感知的记忆架构,让 VLA 可利用历史观测信息,从 “逐帧反应” 转向 “目标驱动的长期连贯动作”,解决当前模型短视行为问题。
3D 与 4D 感知升级:突破静态 2D 视觉输入局限,整合深度、点云数据实现 3D 空间理解,结合时间动态信息构建 4D 感知,提升复杂环境操作稳健性。
移动操作整合:打破 “移动” 与 “操作” 的阶段分离,学习自适应优先的整合策略,实现机器人同时完成 locomotion 与交互操作,适配真实世界动态场景需求。
多智能体协作:构建共享世界模型与涌现式对话协议,让多个 VLA 智能体可协商意图、分配子任务(如联合搬运物体、协作使用工具),解决单智能体在复杂协作任务中的能力局限。
开放世界终身学习:设计增量知识积累机制与抗遗忘记忆结构,让 VLA 可在开放环境中通过探索与反馈持续学习新技能、适应未知物体与交互方式,突破静态数据集训练的局限。
模型效率提升:通过任务感知动态令牌修剪、异步推理、硬件友好量化,平衡模型容量与实时推理需求,适配资源受限的机器人平台。
结论
基于大型 VLM 的 VLA 模型已成为机器人操作与具身 AI 领域的关键突破方向,其发展核心在于:①构建了 “单体式 - 分层式” 二元分类体系,明确单系统 / 双系统与仅规划器 / 规划器 - 策略的架构差异,解决领域分类混乱与研究碎片化问题;②整合多模态融合、指令遵循、多维度泛化等核心特征,形成 “感知 - 语言 - 动作” 协同的技术框架,同时梳理了真实世界、模拟、人类行为、具身四类支撑数据集与基准;③推动强化学习、世界模型等技术与 VLA 模型深度结合,为复杂环境操作提供新路径。
当前领域仍存在”跨载体自适应不足、真实部署扩展性有限、高层推理与低层执行耦合松散、人类演示利用不充分“等关键挑战。未来需以 “多模态大语料拓展、模块化控制优化、真实场景适配、互联网级人类演示融合” 为重点,进一步打通 “视觉理解 - 语言解析 - 动作生成” 的全链路,推动 VLA 模型成为统一感知、语言与动作的具身 AI 基础,助力机器人操作走向更广泛的现实应用。











