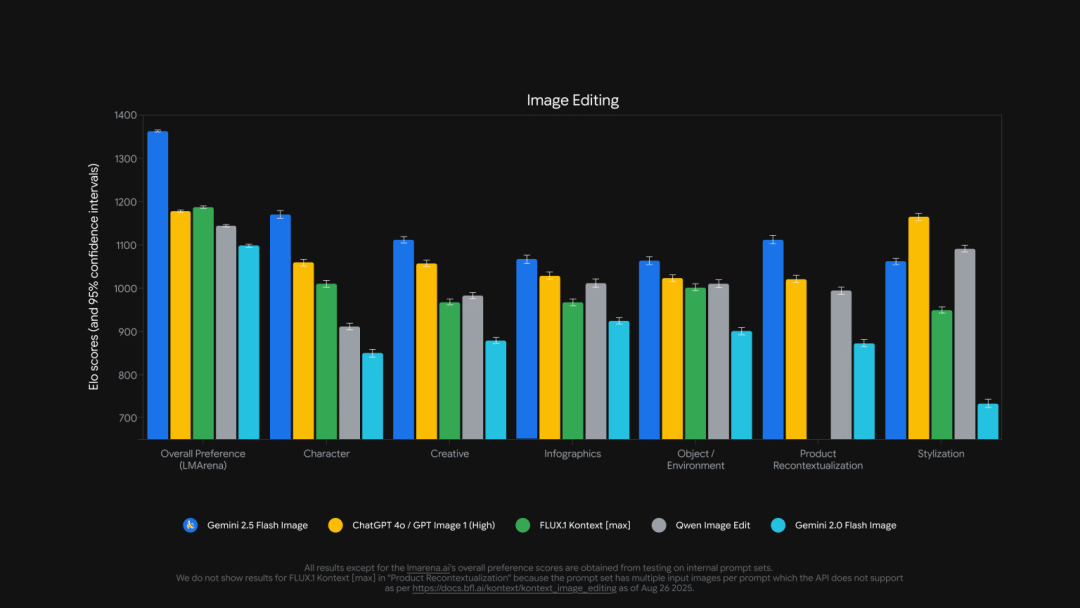
8月27日科技区角互联网行业企业查询平台报道,近日谷歌正通过全新的AI影像大模型升级其Gemini聊天机器人,该模型可为用户提供更精细的照片编辑控制功能,旨在追赶OpenAI热门图像工具的热度并吸引ChatGPT用户。 该款名为Gemini 2.5 Flash Image的更新将于本周二起向Gemini应用所有用户推送,同时通过Gemini API、Google AI Studio及Vertex AI平台向开发者开放。 该AI影像模型专为基于自然语言指令实现精准图像编辑而设计,能在修改过程中保持人脸、动物及其他细节的一致性,这是多数竞品工具难以企及的能力。例如,若要求ChatGPT或xAI的Grok修改照片中某人的衬衫颜色,结果可能导致面部扭曲或背景失真。 谷歌明确表示该模型由其自主研发,具体为其旗舰AI模型Gemini 2.5 Flash的原生图像功能模块。谷歌宣称该图像模型在LMArena等权威评测中已达到行业顶尖水平。 AI图像模型已成为科技巨头的关键战场。今年3月,OpenAI推出GPT-4o原生图像生成器后,因AI生成的吉卜力工作室梗图引发热潮,推动ChatGPT使用量激增,据OpenAI首席执行官阿尔特曼称,这甚至导致公司GPU“不堪重负”。 为追赶OpenAI与谷歌,Meta上周宣布将从初创公司Midjourney授权获取AI图像模型。与此同时,a16z投资的德国独角兽企业黑森林实验室仍凭借其FLUX AI图像模型在基准测试中保持领先。 或许Gemini这款令人印象深刻的AI图像编辑器能帮助谷歌缩小与OpenAI的用户差距。ChatGPT当前周活跃用户超7亿;而在7月的线上财报会议上,谷歌首席执行官桑达尔·皮查伊透露,Gemini月活用户达4.5亿,这意味着其周活用户数量和ChatGPT还有相当大差距。 同时,谷歌DeepMind视觉生成模型产品负责人妮可·布里奇托娃指出,谷歌专门针对消费者使用场景设计该图像模型,例如帮助用户可视化家居与园艺改造方案。此外,模型具备更强的“世界知识”理解能力,可在单条指令中融合多参考元素,例如,将沙发图片、客厅照片与配色方案融合为一张协调的效果图。 尽管Gemini新型AI图像生成器让用户更轻松地创作与编辑图像,但谷歌设置了多重安全限制。该公司曾因Gemini生成历史人物形象失真而公开道歉,并一度全面下架图像生成功能。