一场围绕网络搜索与浏览数据的争夺战,正愈演愈烈。
作者:MICHAEL PAREKH
日期:2025 年 8 月 26 日
大语言模型公司之间的竞赛日趋白热化,它们模型的能力几乎每周都在刷新纪录。
在这场竞赛中,数据是驱动一切的核心燃料,无论是用于训练模型,还是用于响应数亿用户的推理查询,这种需求永无止境。
无论是人类亲手创造的,还是机器合成的,数据都已成为所有人工智能公司争夺的焦点。
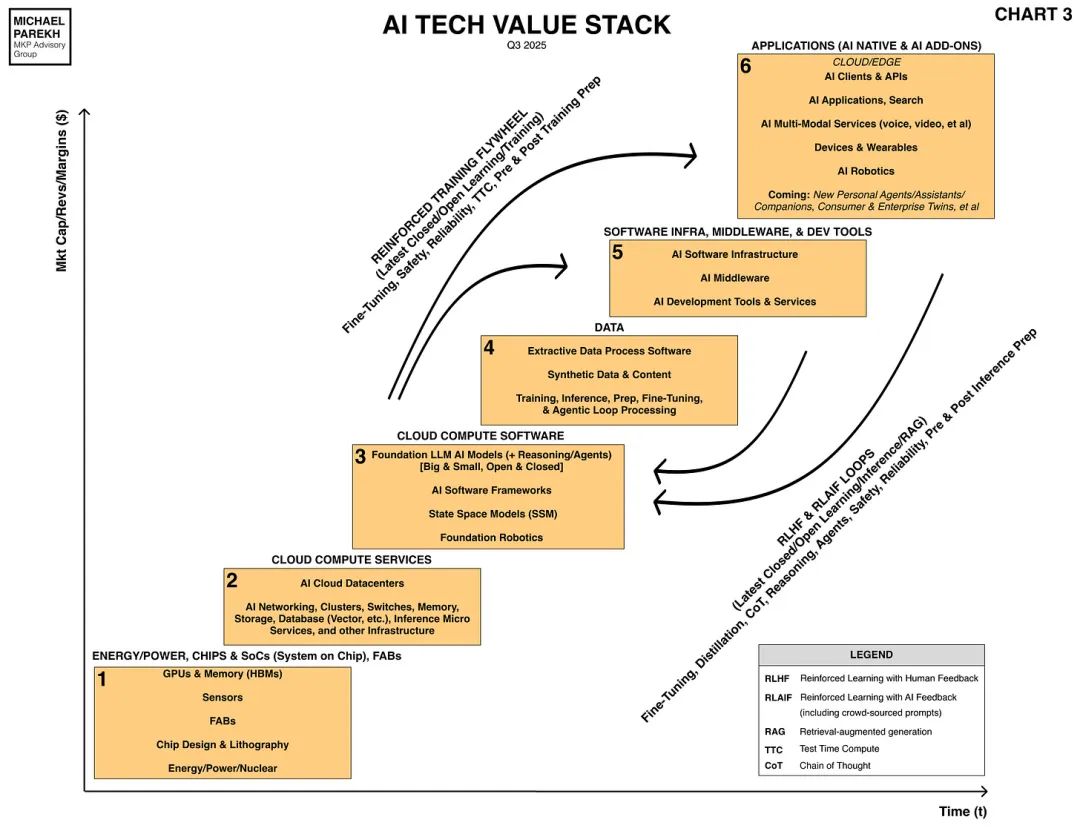
它正是人工智能技术栈中那个独一无二的第四个方框,是在个人电脑、互联网和移动时代的技术栈中前所未见的。
尤其是在实体AI领域,AI 驱动的机器人和汽车对合成数据的需求量巨大,且在飞速增长。
这是训练未来机器人(特别是人形机器人)不可或缺的一环。
但回到大语言模型,其最主要的原始数据来源,依然是人类在互联网上的搜索行为。
实现这一行为的载体,便是我们这个时代无处不在的应用——网络浏览器。
因此,所有目光都聚焦于谷歌和苹果,这两家公司分别拥有全球最受欢迎的浏览器 Chrome 和 Safari。当然,还有备受期待的 OpenAI 的 AI 浏览器。

由此,AI 浏览器开辟了一个全新的战场。
在这个战场上,大大小小的语言模型为了满足自身永不满足的胃口,正激烈争夺着各种新形式的数据。
而在网络搜索这个领域,主角只有谷歌一个,因为它主导了除中国以外的全球市场。
因此,权威科技媒体 The Information 敏锐地指出了 OpenAI 与谷歌之间日益加剧的紧张关系,这毫不令人意外。

“OpenAI 正试图挑战谷歌的霸主地位,但讽刺的是,它依赖的数据来源,恰恰是谷歌自己。
尽管在底层算力上,OpenAI 越来越依赖谷歌的 TPU 芯片架构。
“据两位知情人士透露,OpenAI 一直在使用从网络上抓取的谷歌搜索结果,来为 ChatGPT 的回答提供支持。
其中一位人士称,谷歌的搜索数据帮助 ChatGPT 回答了关于新闻、体育和股市等时事类问题。
这些数据的源头,是一家第三方的行业数据提供商。
“OpenAI 从一家名为 SerpApi 的网络抓取公司获取数据。就在去年五月,这家公司的网站上还将 OpenAI 列为客户,但后来该信息被移除,原因不明。

尽管存在着这种“亦敌亦友”的复杂关系。
“与此同时,OpenAI 开始从谷歌云租用服务器,为 ChatGPT 提供动力。
这表明谷歌相信自己能从 OpenAI 的崛起中获益,就像它与苹果、Meta 这些老对手建立深度商业关系一样。
但对于数据抓取,谷歌并没有坐视不管。
“谷歌在授权 OpenAI 直接访问其搜索数据方面表现得非常敏感。一年前,它就曾拒绝 OpenAI 为开发 ChatGPT 搜索功能而提出的此类请求。
一位知情人士称,谷歌高管私下里对 SerpApi 公司颇有微词,并尝试了多种技术手段,试图增加其网络爬虫抓取高质量信息的难度,但效果如何尚不清楚。
谷歌似乎并未采取法律手段来关停 SerpApi,因为在当前严格的监管审查下,谷歌对打击使用其搜索结果的竞争对手持谨慎态度。
在与美国司法部的反垄断案中,主审法官甚至暗示,支持强迫谷歌向竞争对手分享其搜索结果数据。
面对这种局面,双方都试图保持表面的平静。

“一位 OpenAI 的发言人表示:“我们从网页和各种提供商处检索准确且与上下文相关的信息,这使我们能够综合利用多个来源的信息。”
谷歌发言人和 SerpApi 的首席执行官则对此拒绝置评。
这并非 OpenAI 首次使用谷歌的数据来强化其产品。据报道,它此前曾违规使用 YouTube 视频数据来训练其部分 AI 模型。
当然,走这条路的不只 OpenAI 一家。
“SerpApi 的网站曾将苹果列为客户。此外,运营着一个 AI 搜索引擎的 Perplexity 也是其客户之一。
根据一份政府文件,OpenAI 估计其日均处理的网络搜索量至少是 Perplexity 的 25 倍。
OpenAI 并非只依赖谷歌这一个原始数据来源。
“它不仅使用自己的网络爬虫来获取和索引网页数据,还通过 API 从微软的必应获取数据。
其他公司也提供类似的搜索 API,但谷歌是个例外,它将搜索数据视为自己皇冠上的明珠,从不对外开放。
但谷歌数据的指纹却随处可见。
“OpenAI 的高管们自己也承认,在处理那些冷门、不常见的搜索查询时,他们很难凭一己之力达到谷歌那样的准确度。
外部开发者也已开始注意到,谷歌的搜索结果频繁出现在 ChatGPT 的回答中。
“ChatGPT 的产品负责人 Nick Turley 曾表示:“我们的目标是,用我们自己的第一方索引来服务大约 80% 的流量——这是一个崇高的目标,我们还差得很远。”
“我们认为 100% 实现这个目标虽然长远来看有可能,但它太过遥远和不确定,甚至无法成为一个可操作的目标。”
谷歌也在与其他 AI 领域的亦敌亦友者合作,比如 Meta。
“谷歌已表明愿意向 Meta 等竞争对手提供搜索信息,Meta 在其 AI 聊天机器人中就使用谷歌来辅助回答用户问题。
双方的体量差距依然悬殊。
“谷歌在三月份表示,其年处理搜索量超过 5 万亿次。这意味着,它每天处理的搜索量是 ChatGPT 的数十倍。
这场竞争似乎并未影响谷歌的搜索广告收入,该业务在六月季度增长了 11.7%。
尽管如此,高管和股东们依然担心,ChatGPT 的崛起最终会抑制谷歌的增长。
成立不到三年的 ChatGPT,仅凭订阅收入就有望突破每年 100 亿美元。
OpenAI 还在探索更多的商业模式,比如向免费用户投放广告,或从通过 ChatGPT 促成的交易中抽取佣金。
这场对数据的追逐,还进一步蔓延到了电子商务领域。
“谷歌掌握着数百万种在线商品的详细信息。目前尚不清楚,它是否愿意将这类信息授权给 OpenAI,后者正雄心勃勃地想把 ChatGPT 打造成一个购物搜索入口。
这一切都清晰地揭示了一个核心要点:在人工智能这波科技浪潮的早期阶段,数据,就是兵家必争之地。
而商业利益和监管现实,也在深刻地塑造着这场牌局中,所有玩家之间的互动与博弈。好戏,才刚刚开始。
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!