注意力机制或成为小模型之争的最前沿。
作者丨梁丙鉴
编辑丨马晓宁

小模型 SOTA 之争持续升温,英伟达也再次下场。
在最新论文中,其最新发布的 Jet-Nemotron 系列混合架构语言模型在多项基准测试中超越或追平了 Qwen3,Qwen2.5,Gemma3 和 Llama3.2 的精度,同时实现了高达 53.6 倍的吞吐量加速和 6.1 倍的预填充加速。在与 DeepSeek-V3-Small 和 Moonlight 等最新 MoE 全注意力模型的比较中,Jet-Nemotron-2B 也在 MMLU 和 MMLU- pro 等数学任务的处理上表现出了更高的精度。
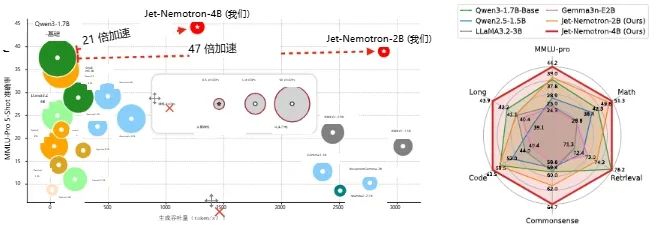
如上图所示,在 NVIDIA H100 GPU 上,以 64K token 的上下文长度测量生成吞吐量。Jet-Nemotron-2B 在 MMLU-Pro 上比 Qwen3-1.7B-Base 具有更高的准确性,同时生成吞吐量提高了 47 倍。Jet-Nemotron-4B 尽管模型规模更大,但生成吞吐量仍比所有参数小于 2B 的全注意力模型更高。
一句话来说,就是以更短的时间实现了更高的准确率。
有意思的是,Jet-Nemotron 系列模型的背后,还是小模型中的老朋友 Qwen2.5-1.5B 和 Qwen2.5-3B。
由于预训练的成本高企不下,设计新的语言模型架构具有具有极大的挑战和风险。在此背景下,Jet-Nemotron 的训练采用了 Post Neural Architecture Search (PostNAS)方案,这是种以完成预训练的全注意力模型为基础,寻找最优注意力模块配置的方法。简单来说,英伟达选择对既有的模型“开刀”进行针对性优化,而从结果来看,手术很成功。

论文链接:https://arxiv.org/pdf/2508.15884

01
Qwen2.5 系列本身就是同尺寸模型中的佼佼者,提供了一个极高的性能起点。PostNAS 的目标不是从零学习知识,而是在保留其核心知识的前提下,对其进行“架构手术”,优化其推理效率。
与主流的语言模型架构设计方法不同,PostNAS 从预训练的全注意力模型开始,继承其 MLP (多层感知器)权重并使其保持冻结,仅对注意力机制部分进行优化,这种策略显著降低了训练成本。
PostNAS 的后续流程包括四个关键步骤:
1.全注意力机制的位置选择与消除
在模型中保留少数全注意力层,对于在检索等任务中保持高精度至关重要,然而这些层的最佳位置并不明确。解决该问题的常见策略之一是将少数全注意力层整合,在全注意力模型的部分层上均匀应用,其余层使用线性注意力。
这种均匀策略并非最优,英伟达团队提出了一种自动方法,用于高效确定全注意力层的位置。
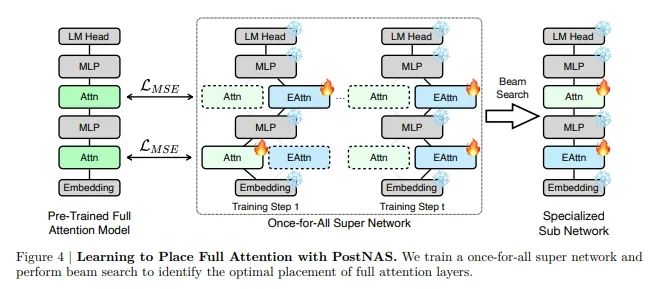
其核心思路是为预训练的全注意力模型增加替代线性注意力路径,构建一个一次性超网络。在训练过程中,研究人员会在每一步随机采样一条活跃路径,形成一个子网络,并对该子网络使用特征蒸馏损失进行训练。训练完成后,使用束搜索就可以确定全注意力层在给定约束条件下的最佳位置。其中搜索目标与任务相关:对于 MMLU,研究人员选择在正确答案上损失最低的配置(即最大化−𝑙𝑜𝑠𝑠),而对于数学和检索任务,则选择准确率最高的配置。
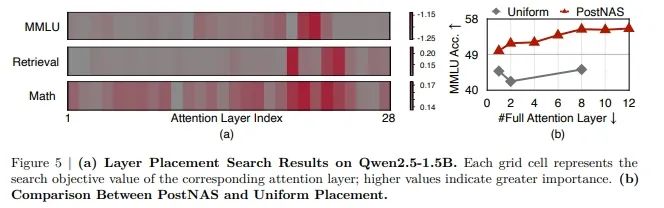
上图展示了 Qwen2.5-1.5B 的搜索结果。通过依次将每一层配置为全注意力机制,同时将所有剩余层设置为线性注意力机制,研究人员从超网络中提取到了相应的子网络。每个子网络的准确率和损失可以在给定任务下进行评估,并通过热力图可视化结果。英伟达团队的分析揭示了三个关键发现:
在预训练的全注意力模型中,并非所有注意力层都同等重要。对于 MMLU 任务,只有两层表现出关键重要性,而对于检索任务,仅有两到三层特别关键。
不同的注意力层对不同的能力有所贡献。对 MMLU 准确率起关键作用的注意力层,不一定对检索任务重要。
对于数学推理等复杂任务,注意力重要性的模式变得更加复杂。幸运的是,为 MMLU 和检索任务识别出的关键层集合已经涵盖了数学所需的大部分关键层。
2.线性注意力模块选择
在全注意力层的最优位置之后,还需要确定最适合的线性注意力模块。英伟达团队评估了六种 SOTA 线性注意力模块,其中包括 RWKV7, RetNet, Mamba2, GLA, Deltanet和 Gated DeltaNet。分析发现,RWKV7 的训练吞吐量与其它线性注意力模块相比显著较低,训练吞吐量显著较低,而 Gated DeltaNet 则实现了最佳的整体准确率。
这归因于两个因素的结合:数据相关门控机制可以实现模型在关注当前 token 和历史状态之间的动态控制,Delta 规则通过当前 token 的信息增量更新历史状态,在此基础上节省有限的状态内存。
值得注意的是,得益于 PostNAS 框架的低训练成本,系统评估既有线性注意力模块在不同任务上的准确性、训练效率和推理速度成为可能。因此随着新的线性注意力模块出现,当他们表现出超越 Gated DeltaNet 的性能时,也可以被快速替换。
3.新的注意力模块设计
Jet-Nemotron 系列模型还应用了一种全新的注意力模块 JetBlock 以扩展线性注意力容量。
不同的此前依赖静态卷积核的方案,英伟达团队引入了一个卷积核生成模块,该模块根据输入特征动态生成卷积核。如下图所示,该模块与 Q/K/V 投影层共享相同输入,首先通过线性缩减层提高效率,缩减比例为 8,然后应用 SiLU 激活函数,最后通过一个最终线性层输出卷积核权重。
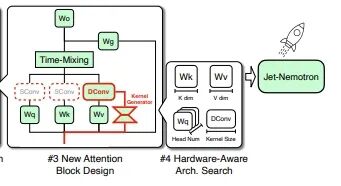
研究人员还发现,一旦对值(V)标记应用动态卷积,对查询(Q)和键(K)标记的静态卷积就可以被移除,而对最终模型精度的影响可以忽略不计。最终实验采用了这种设计,JetBlock 在与之前线性注意力模块的比较中,在数学推理和检索任务上比 Gated DeltaNet 表现出了更高的精度,同时保持了相似的效率。
4.硬件感知架构搜索
PostNAS 还应用了一种硬件感知架构搜索方案,以识别最优的架构超参数,包括键/值维度和注意力头的数量。
虽然参数数量通常被用作衡量语言模型效率的指标,但它实际上与硬件的生成效率并不直接相关。英伟达团队将生成吞吐量作为选择架构超参数的直接目标,通过硬件感知架构搜索,发现了能够实现相似生成吞吐量、同时使用更多参数以获得更高精度的架构超参数。
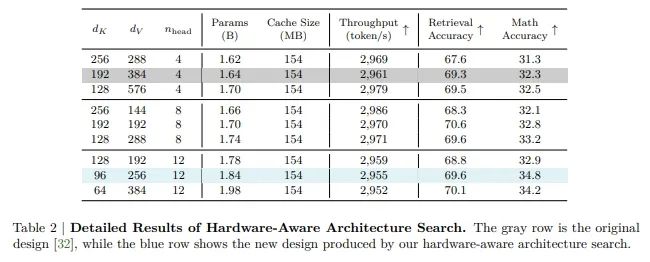
这一原理在于,KV 缓存大小是影响长上下文和长生成吞吐量的最关键因素。当 KV 缓存大小保持不变时,不同参数数量的模型表现出相似的生成吞吐量。研究人员认为,其原因是解码阶段通常受内存带宽限制而非计算限制。在长上下文场景中,KV 缓存往往比模型权重占用更多内存。减小其大小可以减少每步解码的内存传输时间,并支持更大的批量大小,从而提高生成吞吐量。

02
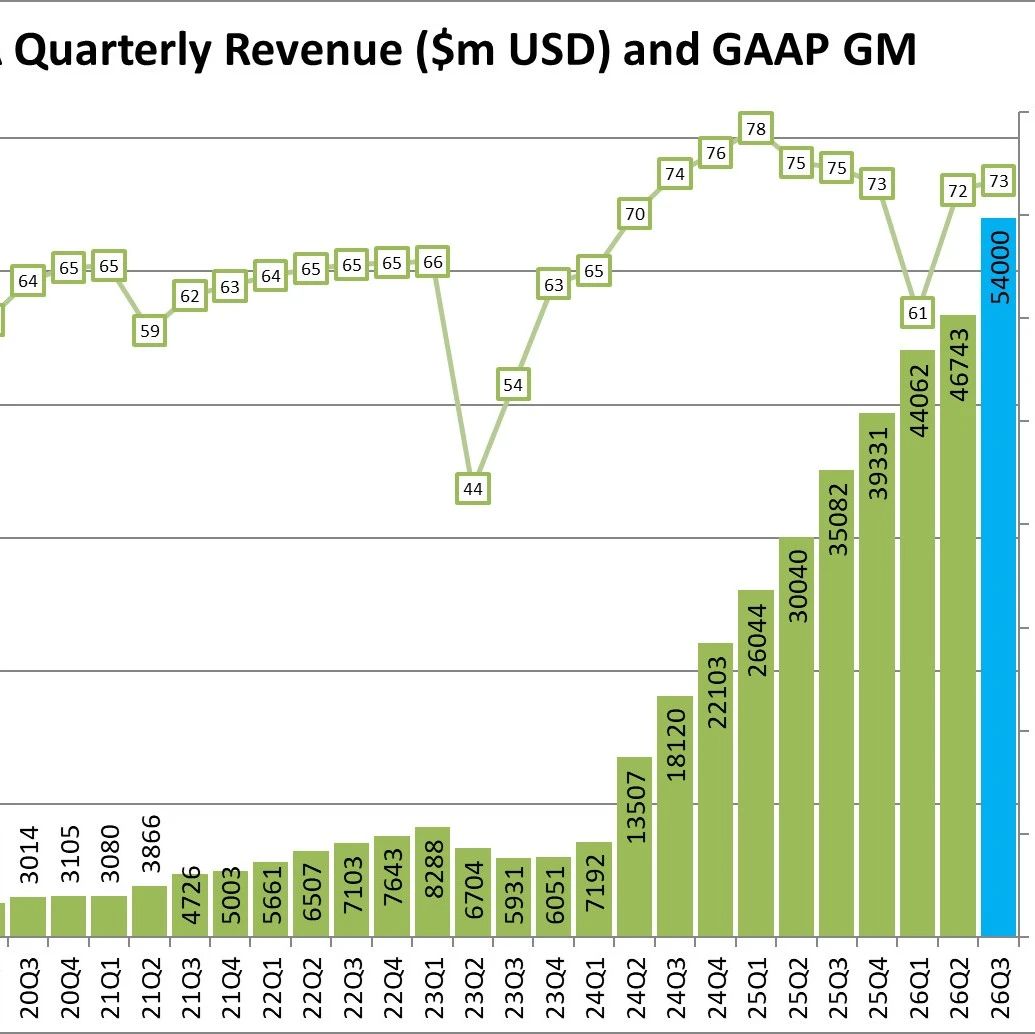
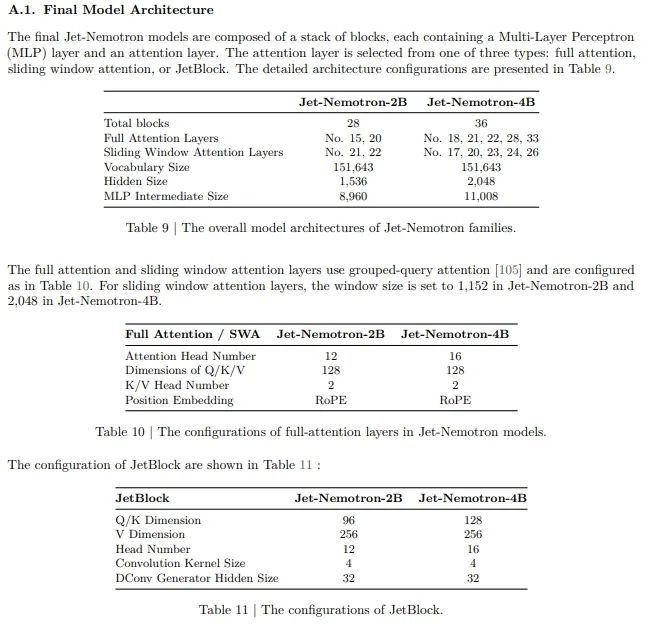
Jet-Nemotron 系列模型包含两个不同参数规模的版本:Jet-Nemotron-2B 和 Jet-Nemotron-4B,分别基于 Qwen2.5-1.5B 和 Qwen2.5-3B 构建。
基准测试结果亦于同期发布。两者在所有六个评估领域中的表现均与前沿完整注意力模型(Qwen3-1.7B-Base)相当甚至更好,具有显著更少的完整注意力层和更小的 KV 缓存大小。在生成吞吐量上,Jet-Nemotron-2B 和 Jet-Nemotron-4B 分别比 Qwen3-1.7B-Base 高出 47 倍和 21 倍。
准确性方面,Jet-Nemotron-2B 在 MMLU(-Pro)和 BBH 上的吞吐量比 Qwen3-1.7B-Base 高 47 倍,缓存大小则小 47 倍,同时在 MMLU、MMLU-Pro 和 BBH 上显著提高了准确率。JetNemotron-2B 甚至超过了参数量更大的 MoE 模型如 DeepSeek-V3-Small 和 Moonlight,两者分别有 2.2B 激活参数和 15B 总参数。当扩展到 4B 参数时,Jet-Nemotron-4B 仍然比 Qwen3-1.7B-Base 在吞吐量上高 21 倍。
数学任务上,Jet-Nemotron-2B 实现了平均 49.6 的准确率,比 Qwen3-1.7B-Base 高出 6.3,同时速度提升了 47 倍。相比之下,之前的线性注意力机制和混合模型在数学任务上则远远落后于 Qwen3。
作为 Jet-Nemotron 系列模型基础的 Qwen2.5 和 Qwen3 在常识推理任务上的性能相对较弱,但 Jet-Nemotron-2B 仍然表现出色,平均准确率达到了 62.0,超越了所有基线模型。此外在检索和编程等任务中,Jet-Nemotron-2B 和 Jet-Nemotron-4B 仍在保持吞吐量优势的前提下,表现出全面超越基线模型的性能。
英伟达团队量化了此种吞吐量优势,下图展示了 Qwen3-1.7B-Base 和 Jet-Nemotron-2B 在不同上下文长度下的吞吐量对比。在预填充阶段,Jet-Nemotron-2B 在较短的上下文长度(4K 和 8K)下初始速度比 Qwen3-1.7B-Base 快 1.14 倍和 1.15 倍。通过设计更优化的 JetBlock 内核实现,这还可以进一步改进。随着上下文长度的增加,线性注意力机制变得突出,使得 Jet-Nemotron-2B 在 256K 上下文长度下实现了 6.14 倍的加速。
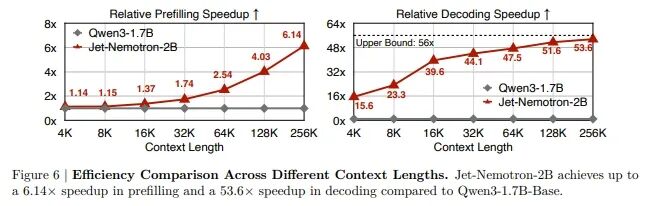
在解码阶段,Jet-Nemotron-2B 始终大幅优于 Qwen3-1.7B-Base。由于 Jet-Nemotron-2B 包含 2 个全注意力层,每组键值状态有 2 组,而 Qwen3-1.7B-Base 包含 28 个全注意力层,每组键值状态有 8 组,因此 Jet-Nemotron-2B 的理论最大加速比是 14 × 4 = 56 倍。据英伟达介绍,在其吞吐量测试平台中,Jet-Nemotron-2B 在 4K 上下文长度下实现了 15.6 倍的加速,在 256K 上下文长度下实现了高达 53.6 倍的加速,几乎达到了理论上的上界。

03
从Jet-Nemotron 的经验来看,在日渐升温的小模型之争中,对现有模型进行深度优化、剪枝、架构改造的能力也将成为多方争夺的前沿,而注意力机制只是起点。
这种基于成熟预训练模型进行架构优化的策略,不仅为英伟达节省了天价开发成本,而且借助 Qwen2.5 和 Qwen3 经过验证的性能保障了下限。其成功之处不在于让英伟达在基准测试榜单上占据几个名次,更深远的意义是 Jet-Nemotron 验证了一条可行的技术路径,即顶级的开源基座模型、创新的高效架构加上低成本的训练后架构搜索,就可以实现新一代高性能、高效率的模型。
这场竞赛的赢家,将是那些在“算法创新”和“工程极致”结合得最好的团队。 注意力机制的创新是发令枪,而整个优化技术体系的马拉松,才刚刚开始。





未经「AI科技评论」授权,严禁以任何方式在网页、论坛、社区进行转载!
公众号转载请先在「AI科技评论」后台留言取得授权,转载时需标注来源并插入本公众号名片。
未经「AI科技评论」授权,严禁以任何方式在网页、论坛、社区进行转载!
公众号转载请先在「AI科技评论」后台留言取得授权,转载时需标注来源并插入本公众号名片。