本文编译自SemiAnalysis,深入解码高带宽内存(HBM)的技术演进与产业变局。面对AI模型对内存容量与带宽的指数级需求,传统内存架构已构成严峻的"内存墙"。文章系统剖析HBM制造工艺的尖端突破(如TSV微孔、混合键合)、供应链权力博弈(三星困境、中国突围),并前瞻HBM4革命性变革——定制基础芯片将重构内存控制器、解锁"海岸线"带宽瓶颈,甚至实现内存内计算。通过揭示Nvidia、OpenAI等巨头的技术路线选择,本文为读者绘制了一幅穿透AI算力桎梏的技术突围地图。
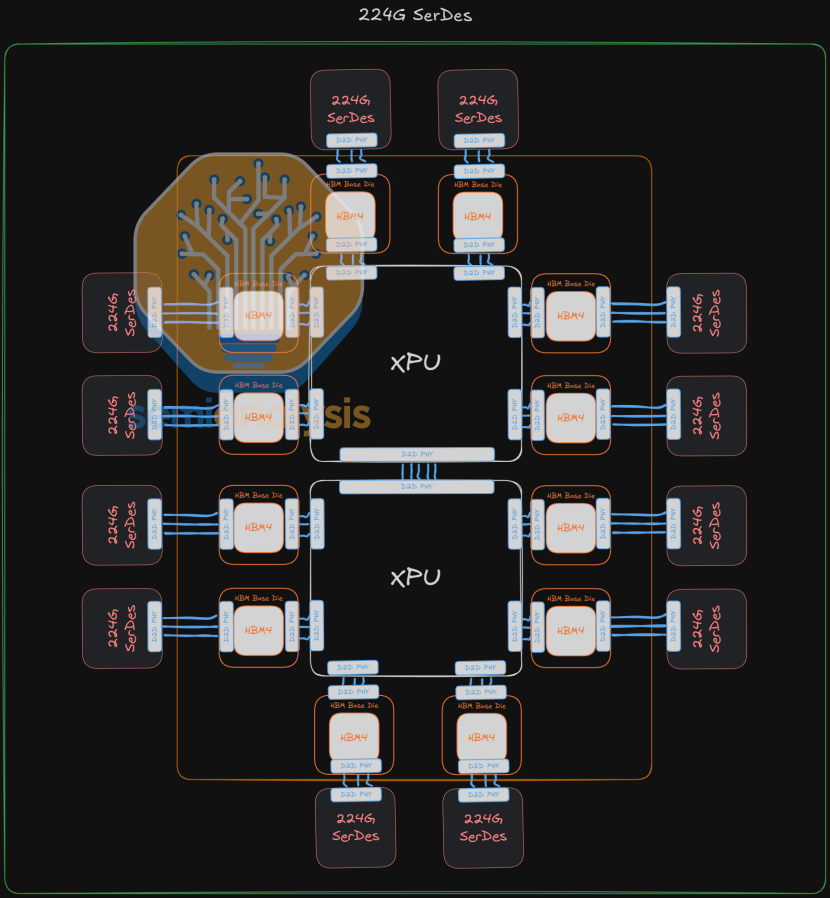
在AI加速器中,由于HBM通常已占用芯片两侧的"海岸线",剩余两侧则用于片外I/O:正如我们在上文GH100示例中所见,一侧用于PCIE接口,另一侧是NVLink接口。与内存类似,片外带宽同样受这种海岸线限制的约束,在AI加速器中这种限制更为突出——因为与其他计算引擎相比,AI加速器有一半甚至更多的海岸线专用于内存,而其他计算引擎 dedicated 的内存专用海岸线较少。延续二级内存的相似理念,可以在HBM后方扩展海岸线,将IO小芯片安置在HBM堆栈背后。HBM基础晶圆将通过桥接技术把数据传输到后方的IO小芯片。这些IO小芯片可以是各种SerDes小芯片(如支持NVLink、ICI、UaLink、PCIE的型号),或是共封装光引擎以实现光学尺度扩展。这个极具前景的创新概念最初由初创公司Eliyan演示实现,采用其专有的NuLink PHY技术及其提出的行业标准接口"UMI"(通用内存接口)。 这些I/O引擎或小芯片可部署在基板上,若需要更高带宽则可采用中介层方案。具体配置有多种可能,但核心原理都是通过扩展海岸线来增加I/O能力,并提升内存与封装外I/O配比的灵活性。上图示意了在每个HBM堆栈后方部署一个224G SerDes小芯片的方案。需要注意的是,由于SerDes小芯片可后置设计,理论上无需为片外I/O保留XPU的两个边缘,从而实现HBM全面环绕主海岸线的布局。假设每个I/O小芯片配备8通道224G SerDes,12个小芯片可额外提供2.4TB/s单向带宽,同时还能增加4组HBM位点——相比逐渐成为行业标准的2颗SOC加8组HBM配置具有显著优势。 当然,这需要采用性能更强的PHY技术来处理数据传输:既要满足通过SerDes小芯片和光引擎传输的封装外数据需求,还要处理封装内内存的读写操作。基础晶圆将采用比主XPU更成熟、成本更低的制程。但近年来SRAM密度在先进节点中提升有限。例如,采用3nm工艺的基础晶圆既能实现优异SRAM密度,成本又低于2nm XPU。若拥有额外可用空间,基础晶圆适合承载哪些SRAM密集型功能?一种可能性是在将HBM用作一级缓存时,将缓存标签置于基础晶圆上。我们将在Repeater PHY章节详细探讨这一点。另一种方案是将SRAM组织为内存侧缓存(MSC)。MSC比其他缓存更简单,因其不参与一致性协议。对系统其他部分而言,它就像HBM内存的组成部分。系统会认为数据存储在HBM的某个地址——系统的一致性资源正是基于这种认知进行追踪。然而,基础芯片实际上可能通过预取或延迟写入等加速技术缓存某些数据。预取可利用堆栈内更高带宽预测XPU的未来请求,而无需提交至外部接口。延迟写入则允许高优先级读取操作插队到写入操作之前,确保外部接口优先处理最高优先级任务,即使有低优先级写入请求在队列中等待。通过简单的旁路检查机制,可以正确读取队列中待写入地址的最新值。基础芯片上的SRAM还是实现其他功能的关键组成部分,例如卸载内存控制器负担以及在内存附近运行计算任务。基础晶圆面积约120平方毫米,需符合HBM标准封装规格。其中约40平方毫米可用于SRAM,其余空间需容纳边缘Serdes、硅通孔Serdes以及内存控制逻辑。采用包含单比特纠错功能的标准IP完整阵列时,典型密度为20Mb/平方毫米,这意味着可提供约80MB可用SRAM。具体容量取决于其他逻辑所需空间——这个数字只是为了帮助理解可能的资源规模。基础晶圆上的计算功能将受热限制制约。堆叠其上的多层DRAM会阻碍热量流动,且任何泄漏到DRAM芯片的热点计算都会增加漏电流,引发刷新率和干扰效应问题。只有低功耗、对带宽敏感的任务才适合在此处理。张量重排序(步幅调整、扁平化、重塑等AI工作负载持续执行的操作)是理想选择。基础晶圆可从所有存储体将张量读入SRAM进行本地重组,仅将所需切片传回XPU,避免了在整个HBM总线上传输完整张量。这既释放了主机上昂贵的SRAM和逻辑资源,又减轻了推理过程中常成为瓶颈的总线流量。其他几种以数据为核心的计算内核也符合相同模式。滤波器(如硬件"grep"模式匹配或最近邻向量相似性搜索)可通过微型状态机实现,这些状态机以内存速度运行且功耗极低。通过字典映射值或提取JSON字段的转换操作(类似于Unix awk)同样受益于在数据旁直接进行文本重组。轻量级块压缩虽可行,但其效益取决于数据压缩率以及增加的复杂度是否合理。最后,简单归约操作(例如就地累加结果的32位整数加法)可充分利用HBM带宽而不超出热预算;浮点求和可能更具挑战性,但这个概念表明:在带宽最高的地方处理16GB地址空间的归约操作正是最佳选择。Dylan Patel, Myron Xie, Tanj Bennett, Ivan Chiam, Jeff Kochhttps://semianalysis.com/2025/08/12/scaling-the-memory-wall-the-rise-and-roadmap-of-hbm/