腾讯混元 投稿
量子位 | 公众号 QbitAI
自带声音的视频生成模型,开源版开卷!
最新赶到的是腾讯混元:刚刚正式开源端到端的视频音效生成模型HunyuanVideo-Foley。
文本描述:片段一(0-6s): footsteps;片段二(6-21s): gunshot;片段三(21-27s): Flick whoosh, Haaah.
官方介绍这是一款专为视频内容创作者打造的音频生成工具,无论是短视频创作者、电影制作人、广告创意人员,还是游戏开发者,HunyuanVideo-Foley都能提供专业级别的音频配音能力,真正实现“看懂画面、读懂文字、配准声音”。
夸张滑稽的卡通音效和真实演奏配音都不在话下。
文字描述:The sound of the number 3’s bouncing footsteps is as light and clear as glass marbles hitting the ground. Each step carries a magical sound.
文字描述:Electric guitar power chords ringing out loudly and resonating.
并且完全开源,具体链接可见文末。
专业级别视频配音自动化
视频生成领域的最新进展已能产出视觉效果逼真的内容,但缺乏同步音频,严重影响了沉浸感。
视频转音频(V2A)生成仍面临三大关键挑战 ——
1、多模态数据集匮乏:现有音视频数据集规模有限、质量参差,导致模型面对集外场景时难以生成贴合的音效,无法覆盖多样化视频配音场景。 2、语义响应不均衡:音频严重依赖文本语义,而忽略视频语义,导致无法响应视频中文本未描述的音频内容。 3、音质粗糙:现有方法生成的音频仍存在较明显的背景噪音和杂音,无法满足专业制作对音质的要求。
为解决以上挑战,腾讯混元团队推出端到端多模态音频生成框架——HunyuanVideo-Foley,可合成与视觉动态和语义语境精确匹配的高保真音频,真正实现了专业级别的视频配音自动化。
亮点一:泛化能力好,多场景音画同步
HunyuanVideo-Foley对各种场景的视频输入都能够生成音画一致、语义对齐的音频。
人物互动、动物活动、自然景观、卡通动画、科幻等各种场景,都能生成与画面精准匹配的音频。
文本描述:With a faint sound as their hands parted, the two embraced. With soft background music.
文本描述:Creaking of old wooden windmill.
亮点二:多模态语义均衡响应,文本画面全兼顾
HunyuanVideo-Foley既能理解视频画面,又能结合文字描述,自动平衡不同信息源,生成层次丰富的复合音效,不会因为过度依赖于文本语义而只生成部分音效。
例如,当输入一段包含海浪、沙滩人群及海鸥的视频,且文字描述为“海浪声”时,HunyuanVideo-Foley不仅能精准生成与海浪画面同步的波浪音效,响应文本需求,还能捕捉视频中人群交谈的声音、海鸥盘旋的鸣叫声。
甚至根据场景氛围自然融入轻柔的背景环境音,形成层次丰富的复合音效。
这种对文本描述与视频细节的双重响应,避免了“顾文失画”的问题,让生成的音频与整体场景高度契合,显著提升视频观看的沉浸感。
文本描述:The sound of waves crashing.
亮点三:专业级音频保真度
无论是汽车驶过湿滑路面的细节质感,还是环境音的空间层次,HunyuanVideo-Foley均达到专业制作水准。
HunyuanVideo-Foley生成的音频还能精准还原引擎从怠速到轰鸣的动态变化、呈现轮胎与地面摩擦的质感,甚至通过声场变化体现车辆加速时的空间位移感。
文字描述:A car drives over the wet road.
性能表现全面领先
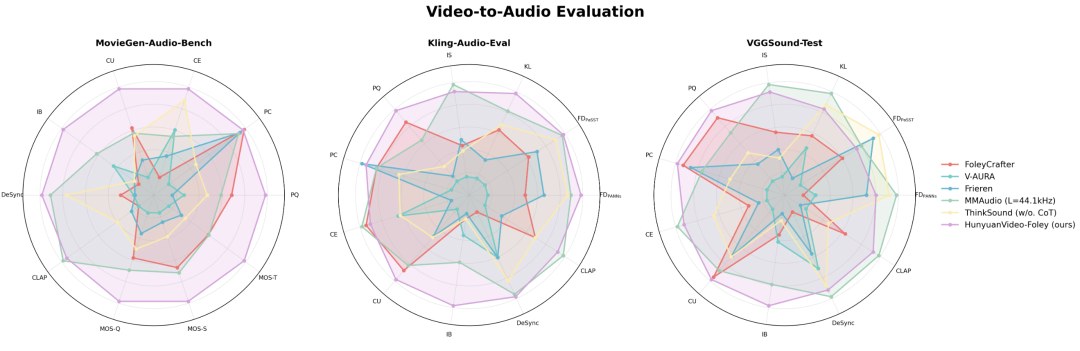
在多个权威评测基准上,HunyuanVideo-Foley的性能表现全面领先。
在音频保真度、视觉语义对齐、时间对齐和分布匹配等维度均达到了新的SOTA水平,超越了所有开源方案。

在权威评测基准MovieGen-Audio-Bench中,HunyuanVideo-Foley的核心指标相对当前最先进的MMAudio模型实现显著提升:
音频质量指标PQ(AudioBox-Aesthetics)从6.17提升至6.59; 视觉语义对齐指标IB从0.27提升至0.35; 在时序对齐指标DeSync上从0.80优化至0.74,均达到当前SOTA水平。
在主观评测中,HunyuanVideo-Foley在音频质量、语义对齐和时间对齐三个维度的平均意见得分均超过4.1分(满分5分),展现了接近专业水准的音频生成效果。
技术方案解读

1、自动化标注与数据过滤的数据管线
首先,为实现可扩展的多模态数据集构建,腾讯混元团队开发了自动化标注与数据过滤的数据管线,成功构建了约10万小时级的高质量TV2A数据集。
为模型训练提供了强大支撑,使得模型拥有强大的泛化能力,能够在各种复杂的视频条件下生成音画一致、语义对齐的高质量音频,包括音效与背景音乐。
生成的音频能够与无声视频相结合,极大提升了视频的真实感和沉浸感。

2、创新MMDiT架构,实现多模态帧级对齐及文本注入
针对模态不平衡问题,HunyuanVideo-Foley创新设计了双流多模态扩散变换器(MMDiT)架构,通过联合自注意力机制建模视频和音频之间的帧级别对齐关系,再通过交叉注意力注入文本信息。
3、引入REPA损失函数,提供语义和声学指导
HunyuanVideo-Foley采用了表征对齐(REPA)损失,通过将单流音频DiT模块的隐层嵌入与预训练自监督模型提取的音频特征对齐,显著提升音频质量。
此外,腾讯混元团队还提出了一种改进的DAC-VAE,采用满足高保真要求的48kHz采样率,并将离散表征扩展至128维连续表征,大幅提升了HunyuanVideo-Foley的音频重建能力。
在这种框架下搭建出的HunyuanVideo-Foley视频音效生成能力,正为多元行业带来高效便捷的解决方案:
针对短视频创作者,能自动适配搞笑段子、生活vlog、AI视频等内容的场景氛围,一键生成贴合画面节奏的背景音效,让创意表达更具感染力; 助力电影制作团队突破传统音效制作的周期与成本瓶颈,快速构建环境音、拟音等细节丰富的声效场景,实现降本提效的后期制作升级; 为广告公司提供专业级音效定制服务,精准匹配产品宣传片的风格调性,通过沉浸式声效增强视觉冲击力与品牌记忆点; 面向游戏开发者,则能依据游戏场景的动态变化实时生成沉浸式环境音、角色动作音效等,助力打造更具代入感的互动体验。
项目官网:https://szczesnys.github.io/hunyuanvideo-foley/
代码仓库:https://github.com/Tencent-Hunyuan/HunyuanVideo-Foley
Hugging Face:https://huggingface.co/tencent/HunyuanVideo-Foley
一键体验视频配音:https://hunyuan.tencent.com/modelSquare/home/play?from=modelSquare&modelId=143
介绍页:https://hunyuan.tencent.com/video/zh?tabIndex=0
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —

🌟 点亮星标 🌟










